




一、简介
Lucene是apache软件基金会4 jakarta项目组的一个子项目,是一个开放源代码的全文检索引擎工具包,但它不是一个完整的全文检索引擎,而是一个全文检索引擎的架构,提供了完整的查询引擎和索引引擎,部分文本分析引擎(英文与德文两种西方语言)。Lucene的目的是为软件开发人员提供一个简单易用的工具包,以方便的在目标系统中实现全文检索的功能,或者是以此为基础建立起完整的全文检索引擎。Lucene是一套用于全文检索和搜寻的开源程式库,由Apache软件基金会支持和提供。Lucene提供了一个简单却强大的应用程式接口,能够做全文索引和搜寻。在Java开发环境里Lucene是一个成熟的免费开源工具。就其本身而言,Lucene是当前以及最近几年最受欢迎的免费Java信息检索程序库。人们经常提到信息检索程序库,虽然与搜索引擎有关,但不应该将信息检索程序库与搜索引擎相混淆。
二、lucene实现全文检索流程
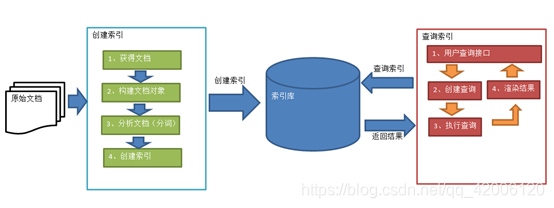
1、绿色表示索引过程,对要搜索的原始内容进行索引构建一个索引库,索引过程包括:
确定原始内容即要搜索的内容 => 采集文档 => 创建文档=>分析文档=>索引文档
2、红色表示搜索过程,从索引库中搜索内容,搜索过程包括:
用户通过搜索界面=>创建查询=>执行搜索,从索引库搜索=>渲染搜索结果
三、基本使用
3.1 jar包
lucene-analyzers-common.jar
lucene-core.jar
ikAnalyzer.jar
lucene-queryparser.jar
3.2 创建索引
@Test
public void create() throws IOException {
//指定索引库存放的路径
FSDirectory fsDirectory = FSDirectory.open(new File("D:\\java\\IDEA_WORKSPACE\\LuceneDomo\\index").toPath());
//使用IKAnalyzer分析器
IndexWriterConfig config=new IndexWriterConfig(new IKAnalyzer());
//创建indexwriter对象
IndexWriter writer=new IndexWriter(fsDirectory,config);
//原始文档
File[] files=new File("H:\\searchsource").listFiles();
for (File f:files){
String name = f.getName();
String path = f.getPath();
String content= FileUtils.readFileToString(f, "utf-8");
long size = FileUtils.sizeOf(f);
//创建域
Field fName=new TextField("name",name,Field.Store.YES);
Field fPath=new StoredField("path",path);
Field fContent=new TextField("content",content,Field.Store.YES);
Field lSize=new LongPoint("size",size);
Field fSize=new StoredField("size",size);
//存入域
Document doc=new Document();
doc.add(fName);
doc.add(fContent);
doc.add(fPath);
doc.add(fSize);
doc.add(lSize);
writer.addDocument(doc);
}
writer.close();
}
3.3 检索
@Test
public void search() throws IOException {
//指定索引库存放的路径
FSDirectory fsDirectory = FSDirectory.open(new File("D:\\java\\IDEA_WORKSPACE\\LuceneDomo\\index").toPath());
IndexReader reader= DirectoryReader.open(fsDirectory);
IndexSearcher searcher=new IndexSearcher(reader);
Query query=new TermQuery(new Term("content","spring"));
TopDocs docs = searcher.search(query, 10);
System.out.println("共记录:"+docs.totalHits);
for (ScoreDoc doc:docs.scoreDocs){
int id=doc.doc;
Document document = searcher.doc(id);
System.out.println(document.get("name"));
System.out.println(document.get("path"));
}
reader.close();
}
四、分析器
4.1. IkAnalyzer中文分析器(第三方)
对中文支持比好,扩展性也好
@Test
public void analyzer() throws IOException {
Analyzer analyzer=new IKAnalyzer();
TokenStream tokenStream = analyzer.tokenStream("name", "们都是一些公开给别人尝试破解的小程序,制作 Crackme 的人可能是程序员,想测试一下自己的软件保护技术 ");
CharTermAttribute charTermAttribute = tokenStream.addAttribute(CharTermAttribute.class);
tokenStream.reset();
while (tokenStream.incrementToken()){
System.out.println(charTermAttribute.toString());
}
tokenStream.close();
}
4.2 StandardAnalyzer(自带)
对英文支持比较好,对中文分析不行,就是按照中文一个字一个字地进行分词。
如:“我爱中国”,
效果:“我”、“爱”、“中”、“国”。
4.3 SmartChineseAnalyzer(自带)
对中文支持较好,但扩展性差,扩展词库,禁用词库和同义词库等不好处理
五、索引库的维护
| Field类 | 数据类型 | Analyzed是否分析 | Indexed是否索引 | Stored是否存储 | 说明 |
|---|---|---|---|---|---|
| StringField(FieldName, FieldValue,Store.YES)) | 字符串 | N | Y | Y或N | 这个Field用来构建一个字符串Field,但是不会进行分析,会将整个串存储在索引中,比如(订单号,姓名等)是否存储在文档中用Store.YES或Store.NO决定 |
| LongPoint(String name, long… point) | Long型 | Y | Y | N | 可以使用LongPoint、IntPoint等类型存储数值类型的数据。让数值类型可以进行索引。但是不能存储数据,如果想存储数据还需要使用StoredField。 |
| StoredField(FieldName, FieldValue) | 重载方法,支持多种类型 | N | N | Y | 这个Field用来构建不同类型Field不分析,不索引,但要Field存储在文档中 |
| TextField(FieldName, FieldValue, Store.NO)或TextField(FieldName, reader) | 字符串或流 | Y | Y | Y或N | 如果是一个Reader, lucene猜测内容比较多,会采用Unstored的策略. |
5.1 添加文档
@Test
public void addDocument() throws Exception {
//索引库存放路径
Directory directory = FSDirectory.open(new File("C://index").toPath());
IndexWriterConfig config = new IndexWriterConfig(new IKAnalyzer());
//创建一个indexwriter对象
IndexWriter indexWriter = new IndexWriter(directory, config);
//创建一个Document对象
Document document = new Document();
//向document对象中添加域。
//不同的document可以有不同的域,同一个document可以有相同的域。
document.add(new TextField("filename", "新添加的文档", Field.Store.YES));
document.add(new TextField("content", "新添加的文档的内容", Field.Store.NO));
//LongPoint创建索引
document.add(new LongPoint("size", 1000l));
//StoreField存储数据
document.add(new StoredField("size", 1000l));
//不需要创建索引的就使用StoreField存储
document.add(new StoredField("path", "d:/temp/1.txt"));
//添加文档到索引库
indexWriter.addDocument(document);
//关闭indexwriter
indexWriter.close();
}
5.2 索引库删除
说明:将索引目录的索引信息全部删除,直接彻底删除,无法恢复
@Test
public void deleteAllIndex() throws Exception {
//getIndexWriter重复代码省略为方法
IndexWriter indexWriter = getIndexWriter();
//删除全部索引
indexWriter.deleteAll();
//关闭indexwriter
indexWriter.close();
5.3 指定查询条件删除
@Test
public void deleteIndexByQuery() throws Exception {
IndexWriter indexWriter = getIndexWriter();
//创建一个查询条件
Query query = new TermQuery(new Term("filename", "apache"));
//根据查询条件删除
indexWriter.deleteDocuments(query);
//关闭indexwriter
indexWriter.close();
}
5.4 7.3 索引库的修改
原理就是先删除后添加。
//修改索引库
@Test
public void updateIndex() throws Exception {
IndexWriter indexWriter = getIndexWriter();
//创建一个Document对象
Document document = new Document();
//向document对象中添加域。
//不同的document可以有不同的域,同一个document可以有相同的域。
document.add(new TextField("filename", "要更新的文档", Field.Store.YES));
document.add(new TextField("content", " Lucene 简介 Lucene 是一个基于 Java 的全文信息检索",
Field.Store.YES));
indexWriter.updateDocument(new Term("content", "java"), document);
//关闭indexWriter
indexWriter.close();
}
六、Lucene索引库查询
对要搜索的信息创建Query查询对象,Lucene会根据Query查询对象生成最终的查询语法,类似关系数据库Sql语法一样Lucene也有自己的查询语法,比如:“name:lucene”表示查询Field的name为“lucene”的文档信息。
可通过两种方法创建查询对象:
1)使用Lucene提供Query子类
2)使用QueryParse解析查询表达式
6.1 TermQuery
TermQuery,通过项查询,TermQuery不使用分析器所以建议匹配不分词的Field域查询,比如订单号、分类ID号等。指定要查询的域和要查询的关键词。
上面入门例子即是
6.2 数值范围查询
size为LongPoint类型
@Test
public void testRangeQuery() throws Exception {
IndexSearcher indexSearcher = getIndexSearcher();
Query query = LongPoint.newRangeQuery("size", 0L, 10000L);
printResult(query, indexSearcher);
}
6.3 使用queryparser查询
@Test
public void testQueryParser() throws Exception {
//指定索引库存放的路径
FSDirectory fsDirectory = FSDirectory.open(new File("D:\\java\\IDEA_WORKSPACE\\LuceneDomo\\index").toPath());
//指定索引库存放的路径
IndexReader reader= DirectoryReader.open(fsDirectory);
IndexSearcher searcher=new IndexSearcher(reader);
QueryParser queryParser=new QueryParser("content",new IKAnalyzer());
Query query = queryParser.parse("Lucene是java开发的");
printResult(query,searcher);
}
private void printResult(Query query, IndexSearcher indexSearcher) throws Exception {
//执行查询
TopDocs topDocs = indexSearcher.search(query, 10);
//共查询到的document个数
System.out.println("查询结果总数量:" + topDocs.totalHits);
//遍历查询结果
for (ScoreDoc scoreDoc : topDocs.scoreDocs) {
Document document = indexSearcher.doc(scoreDoc.doc);
System.out.println(document.get("name"));
//System.out.println(document.get("content"));
System.out.println(document.get("path"));
System.out.println(document.get("size"));
}
//关闭indexreader
indexSearcher.getIndexReader().close();
}
最后
贴下pom.xml方便使用
<dependencies>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.11</version>
<scope>compile</scope>
</dependency>
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-core</artifactId>
<version>8.0.0</version>
</dependency>
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-analyzers-common</artifactId>
<version>8.0.0</version>
</dependency>
<dependency>
<groupId>commons-io</groupId>
<artifactId>commons-io</artifactId>
<version>2.6</version>
</dependency>
<!--自己安装得-->
<dependency>
<groupId>com.lucene</groupId>
<artifactId>ikAnalyzer</artifactId>
<version>1.0</version>
</dependency>
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-queryparser</artifactId>
<version>8.0.0</version>
</dependency>
</dependencies>

















 4507
4507

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









