




 介绍了一种简单的深层神经网络模型——深度平均网络(DAN),该模型在情感分析和事实式问答任务中表现出与复杂模型相当甚至更优的性能,同时大幅减少了训练时间。DAN通过平均词向量并将其传递给非线性层进行分类,证明了在某些任务中,非线性的特征转换比明确地考虑语法结构更加关键。
介绍了一种简单的深层神经网络模型——深度平均网络(DAN),该模型在情感分析和事实式问答任务中表现出与复杂模型相当甚至更优的性能,同时大幅减少了训练时间。DAN通过平均词向量并将其传递给非线性层进行分类,证明了在某些任务中,非线性的特征转换比明确地考虑语法结构更加关键。
摘要
Many existing deep learning models for natural language processing tasks focus on learning the compositionality of their inputs, which requires many expensive computations. We present a simple deep neural network that competes with and, in some cases, outperforms such models on sentiment analysis and factoid question answering tasks while taking only a fraction of the training time. While our model is syntactically-ignorant, we show significant improvements over previous bag-of-words models by deepening our network and applying a novel variant of dropout. Moreover, our model performs better than syntactic models on datasets with high syntactic variance. We show that our model makes similar errors to syntactically-aware models, indicating that for the tasks we consider, nonlinearly transforming the input is more important than tailoring a network to incorporate word order and syntax.
(许多现有的自然语言处理任务的深度学习模型侧重于学习其输入的组合性,这需要许多昂贵的计算。我们提出了一个简单的深层神经网络,它在情感分析和因子式问答任务上与此类模型竞争,并且在某些情况下优于此类模型,同时只占用很少的训练时间。虽然我们的模型在语法上是无知的,但是我们通过深化我们的网络和应用一种新的dropout变体,显示了比以前的bag-of-words模型的显著改进。此外,我们的模型在高句法变异的数据集上比句法模型表现得更好。我们发现我们的模型与句法感知模型有相似的错误,这表明对于我们所考虑的任务,将输入非线性转换比裁剪网络来整合词序和语法更重要。)
成果
We introduce a deep unordered model that obtains near state-of-the-art accuracies on a variety of sentence and document-level tasks with just minutes of training time on an average laptop computer. This model, the deep averaging network (DAN), works in three simple steps:
- take the vector average of the embeddings associated with an input sequence of tokens
- pass that average through one or more feedforward layers
- perform (linear) classification on the final layer’s representation
(我们引入了一个深度无序模型,在一台普通笔记本电脑上,只需几分钟的训练时间,就可以在各种句子和文档级任务上获得近乎最先进的准确度。此模型称为深度平均网络(DAN),其工作原理有三个简单步骤:
1- 取与输入标记序列相关联的嵌入的平均值;
2- 将平均值通过一个或多个前馈层;
3- 对最后一层的表示进行(线性)分类。)
The model can be improved by applying a novel dropout-inspired regularizer: for each training instance, randomly drop some of the tokens’ embeddings before computing the average.
(该模型可以通过使用一个新的drop-out的正则化进行了改进:对于每个训练实例,在计算平均值之前,随机地删除一些单词的嵌入向量。)
Our goal is to marry the speed of unordered functions with the accuracy of syntactic functions. In this section, we first describe a class of unordered composition functions dubbed “neural bag-of-words models” (NBOW). We then explore more complex syntactic functions designed to avoid many of the pitfalls associated with NBOW models. Finally, we present the deep averaging network (DAN), which stacks nonlinear layers over the traditional NBOW model and achieves performance on par with or better than that of syntactic functions.
(我们的目标是结合无序功能的速度和句法功能的准确性。在本节中,我们首先描述一类无序组合函数,称为“neural bag-of-words models”(NBOW)。然后,我们探索更复杂的句法功能,以避免与NBOW模型相关的许多缺陷。最后,我们提出了深度平均网络(DAN),该网络在传统的NBOW模型的基础上叠加了非线性层,取得了与句法功能相当或更好的性能。)
模型结构
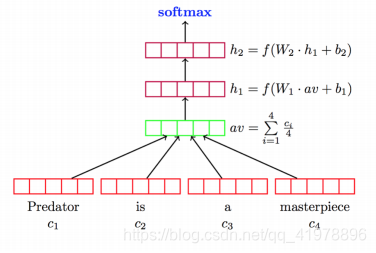
Fig. 1. The architecture of the Deep Average Network (DAN)
结论
In this paper, we introduce the deep averaging network, which feeds an unweighted average of word vectors through multiple hidden layers before classification. The DAN performs competitively with more complicated neural networks that explicitly model semantic and syntactic compositionality. It is further strengthened by word dropout, a regularizer that reduces input redundancy. DANs obtain close to state-of-the-art accuracy on both sentence and document-level sentiment analysis and factoid question-answering tasks with much less training time than competing methods; in fact, all experiments were performed in a matter of minutes on a single laptop core. We find that both DANs and syntactic functions make similar errors given syntactically-complex input, which motivates research into more powerful models of compositionality.
(在本文中,我们引入了深度平均网络,该网络在分类前通过多个隐藏层输入未加权的词的平均值。DAN使用更为复杂的神经网络(明确地为语义和句法组合建模)进行训练。字节drop-out(减少输入冗余的正则化器)进一步加强了这种方法。DAN在句法和文档层面的情感分析以及事实上的问答任务上都获得了接近最先进的准确度,而训练时间远少于其他方法;事实上,所有实验都在一个笔记本电脑核心上在几分钟内完成。我们发现,DAN和句法功能在复杂的句法输入下都会产生类似的错误,这促使了我们后期对更强大的组合模型的研究。)


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









