




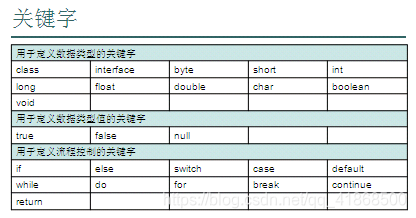
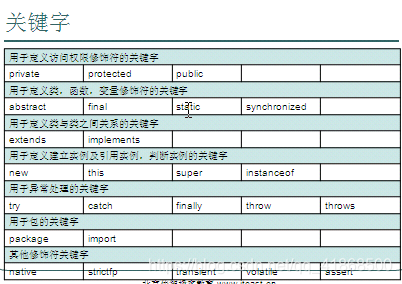
一:关键字
概述:被JAVA语言赋予特定含义的单词
特点:组成关键字的字母全部小写
注意事项:
(1)goto和const作为保留字存在,目前并不使用
(2)类型Notepad++这样的高级记事本,针对关键字有特色的颜色标记,非常直观
二.标识符
概述:就是给,接口,方法,变量等起名字时使用的字符序列
组成规则:
(1)英文大小写字母
(2)数字字符
(3)$和_
注意事项:
(1)不能以数字开头
(2)不能是JAVA中的关键字
(3)区别大小写
三:标识符中常见的命名规则
(1)包:其实就是文件夹,用于把相同的类名进行区分,全部小写
单级:linyi
多级:cn.itcast
(2)类或者接口:
一个单词组成:单词的首字母必须大写
举例:Student,Dog
多个单词组成:每个单词的首字母必须大写
举例:HelloWord,UserName
(3)方法或者变量:
一个单词:单词的首字母小写
举例:main,age
多个单词:从第二个单词开始,每个单词的首字母大写
举例:studentAge,showAllnames()
(4)常量:
一个单词:全部大写
举例:PI
多个单词:每个字母都大写,用_隔开
举例:STUDENT_MAX_AGE
四:注释概述及其分类
概述:用于解释说明程序的文字
作用:解释说明程序,提高程序的阅读性,可以帮助我们调试程序
注释分类格式:
(1)单行注释://注释文字
(2)多行注释:/*注释文字*/
(3)文档注释:/**注释文字*/
五:常量
概述: 常量是一种特殊的变量 值一旦被设定 ,在程序运行过程中不允许改变,常量名一般使用大写字符
格式:fianl 常量名= 值
常量分类:
(1)字面值常量
(2)自定义常量(后面讲)
1.字面值常量
(1)字符串常量:用双引号括起来的内容,例"A","b","0"
(2)整数常量:所有整数,例如12,23
表示形式:二进制、八进制、十进制、十六进制(进制转换)
进制概述:进制:就是进位制,对于任何一种进制--X进制,就表示某一位置上的数运算是逢X进一位。二进制是逢二进一,八进制是逢八进一,十进制是逢十进一,十六进制是逢十六进一
(3)小数常量:所有小数,例如12.34,12.56
(4)字符常量:用单引号括起来的内容,例'A','a','0'
(5)布尔常量:较为特有,只有true和false
(6)空常量:null
在Java中针对整数常量提供了四种表现形式:
A:二进制 由0,1组成。以0b开头。
B:八进制 由0,1,...7组成。以0开头。
C:土进制 由0,1,...9组成。 整数默认是十进制。
D:土六进制 由0,1,...9,a,b,c,d,e,f (太小写均可)组成。以0x开头。
有符号数据表示法:
在计算机内,有符号数有3种表示法:原码、反码和补码。所有数据的运算都是采用补码进行的。
原码:
就是二进制定点表示法,即最高位为符号位,“0"表示正,“1”表示负,其余位表示数值的大小。
反码:
正数的反码与其原码相同;负数的反码是对其原码逐位取反,但符号位除外。
补码:
正数的补码与其原码相同; -负数的补码是在其反码的未位加1。
例如:用原码,反码,补码分别表示 +7和-7,首先我们得到7的二进制:111
原码:正数的原码最高位是0,负数的原码最高位是1,其他是数值位
符号位 数值
+7 0 0000111
-7 1 0000111
反码:正数的反码和原码相同,负数的反码与原码是符号位不变,数值位取反,就是1变0,0变1
符号位 数值
+7 0 0000111
-7 1 1111000
补码:正数的补码与原码相同,负数的补码是在反码的基础上加1
符号位 数值
+7 0 0000111
-7 1 1111001
六:变量
概述:在程序执行的过程中,在某个范围内可以发生改变的量(理解:如同数学中的未知数)
定义变量的格式:
a:数据类型 变量名 = 初始化值;
b:数据类型 变量名;
c:变量名 = 初始化值;
注意:格式是固定的,记住格式,以不变应万变
使用规则:
1Java中的变量需要先声明后使用
2 变量使用时,可以声明变量的同时进行初始化,也可以先声明后赋值 String a = 1; /String a; a=1;
3 变量中每次只能赋一个值,但可以修改多次
4.main 方法中定义的变量必须先赋值,然后才能输出
使用变量时要注意的问题:
A:作用域:
变量定义在哪一级大模块中,哪个大括号的范围就是这个变量的作用域,相同的作用域中不能定义两个同名变量。
B:初始化值:
没有初始化的变量不能直接使用
只要在使用前给值就行,不一定非要在定义的时候立即给值
推荐在定义前就给值
在一行上建议只定义一个变量
可以定义多个,但是不建议
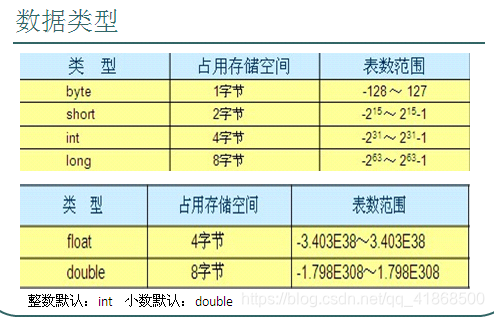
七:数据类型
基本数据类型:
(1)数值型:
整数类型:byte,short,int,long
浮点类型:float,double
(2)字符型:char
(3)布尔型:boolean
引用数据类型:
(1)类:class
(2)接口:interface
(3)数组:[]
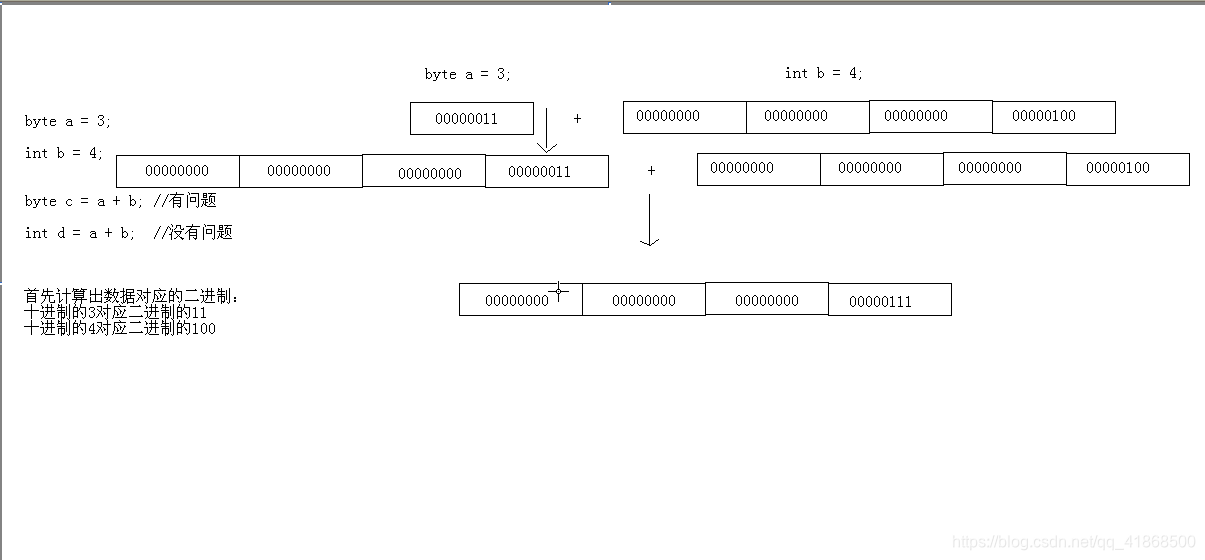
八:数据类型转换
默认转换:(从小到大的转换)
byte,short,char- -int- -long一 float -double
byte ,short, char相互之间不相互转换,他们参与运算首先直接转换为int类型
boolean类型不能转换未其他数据类型
例如:
byte c=5;
int d=7;
System.out.println(c+d);
强制转换:(从大的小的转换)
格式:
目标数据类型 变量 = (目标数据类型) (被转换的数据);
注意:
整数默认是int类型
浮点数默认是double类型
不要随意的去使用强制转换,因为它隐含了精度损失问题
长整型建议用L或者l标记,建议使用L
单精度浮点数用F或者f标记,建议使用F
例如:
byet a=3;
int b=4;
byte c=(byte)(a+b);
九:进制转换
其他进制到十进制:
系数:就是每一个位上的数
基数:X进制的基数就是X
权:对每一个位上的数,并且从0开始编号,对应的编号就是该数据的权
结果:系数*基数^权次幂之和
十进制到其他进制:
除基取余,直到商为0,余数反转
进制快速转换法:
A:十进制和二进制间的转换:8421码
B:二进制到八进制、十六进制的转换
十:运算符
1.算术运算符:
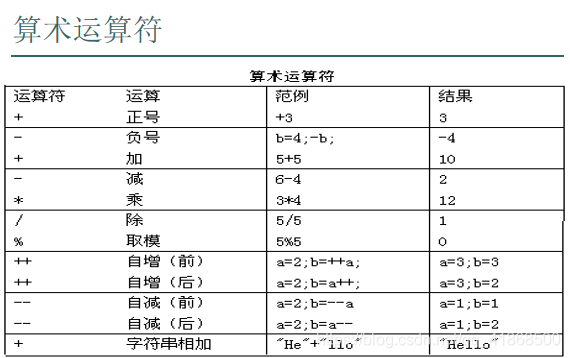
+,-,*,/都是比较简单的操作,简单演示即可
+的几种作用:
加法:System.out.println(3+4);
正数 :System.out.println(+4);
字符串连接符:
System.out.println('a');//只打印一个字符的情况下控制台只会输出这个字符
System.out.println('a'+1);//char类型参与运算首先会转换成int类型并参与运算
System.out.println("hellow"+'a'+1);//运算是从左到右开始运算的,所以这里的值是字符串hellowa1
注意事项:
A:整数相除只能得到整数,如果想得到小数,必须先转换为浮点类型
/和%的区别:
B:/获取的是除法操作的商,%获取的是除法操作的余数
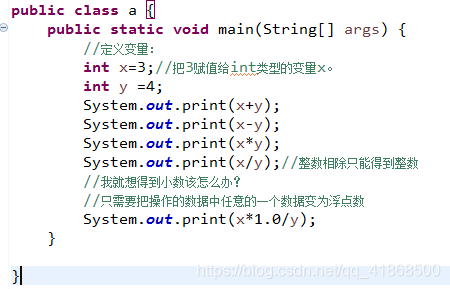
++和--的应用:
单独使用:
++--放在操作数的前面或者后面效果是一样的(这种用法是我们比较常见的)
参与运算使用:
++或者--放在后面是先参与运算再自增或自减
++或者--放在前面是先自增或自减再参与运算
2.赋值运算符:
基本的赋值运算符:=(把右边的数据赋值给左边)
扩展的赋值运算符:+=,-=,*=,/=,%=(把左边和右边做计算再赋值给左边)
扩展的赋值运算符隐含了一个强制类型转换:
例如:
short int =1
s+=1;
不是等价于s=s+1;
而是等价于s=(s的数据类型)(s+1);
3.比较(关系)运算符:
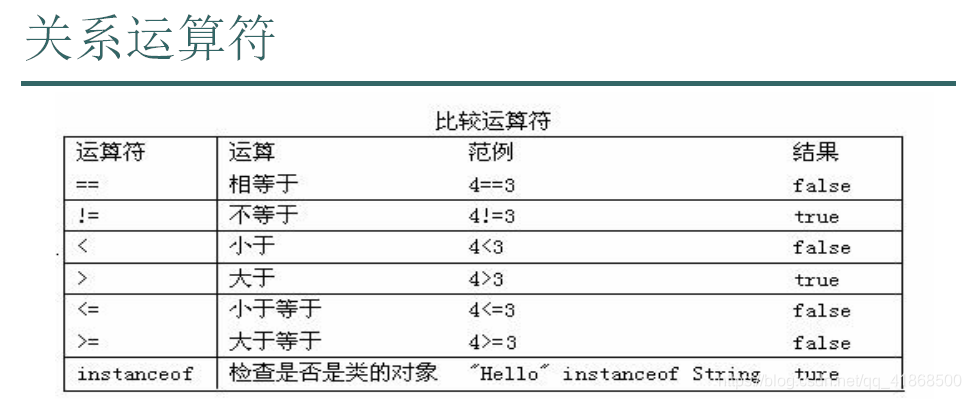
注意:
(1)比较运算符的结果都是boolean类型,也就是要么是true,要么false
(2)比较运算符"=="不能误写成"="
特点:无论操作是简单还是复杂结果肯定是boolean类型
4.逻辑运算符:
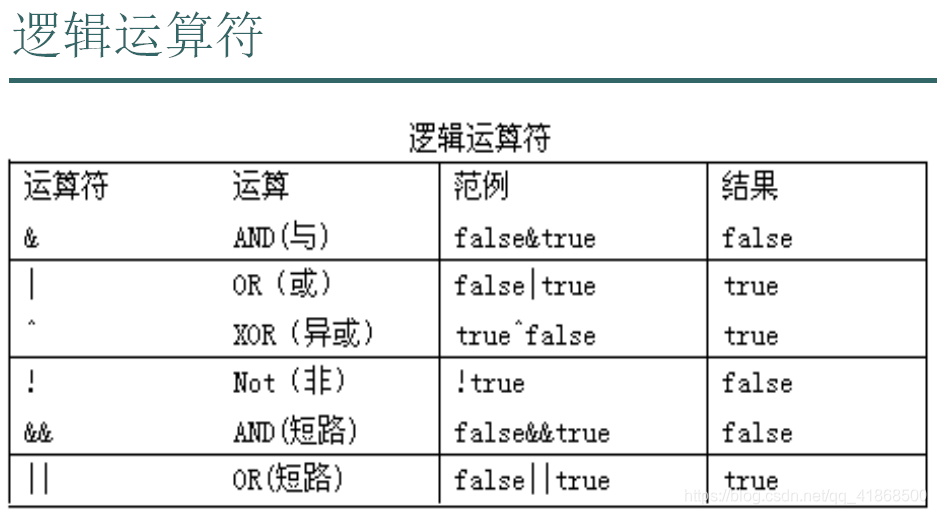 逻辑运算符用于连接布尔型表达式,在java中不可以写成3<x<6,应该写成x>3x&x<6;
逻辑运算符用于连接布尔型表达式,在java中不可以写成3<x<6,应该写成x>3x&x<6;
注意:当逻辑运算符两边是数据做的是位运算,当逻辑运算符两边是布尔值做的是逻辑运算
特点:逻辑运算符一般用户连接boolean类型的表达式或值
表达式:就是用运算符把常量或者变量连接起来的符合java语法的式子
算术表达式:a+b
比较表达式:a==b
结论:
&逻辑与:有false则false,只有全部结果为true才会true
|逻辑或:有true则true,只有全部为false才会为false
^逻辑异或:结果相同为falser,不同为true
!逻辑非:非false则true,非true则false 特点:偶数个!不改变本身
“&”和“&&”的区别:
单&时,左边无论真假,右边都进行运算
双&&时,如果左边为真,右边参与运算,如果左边为假,那么右边不参与运算
“|”和“||”的区别:
单|时,左边无论真假,右边进行运算
双||时,当左边为true时,右边不参与运算,如果左边为false,那么右边参与运算
异或( ^ )与或( | )的不同之处是:当左右都为true时,结果为false。
5.位运算符:
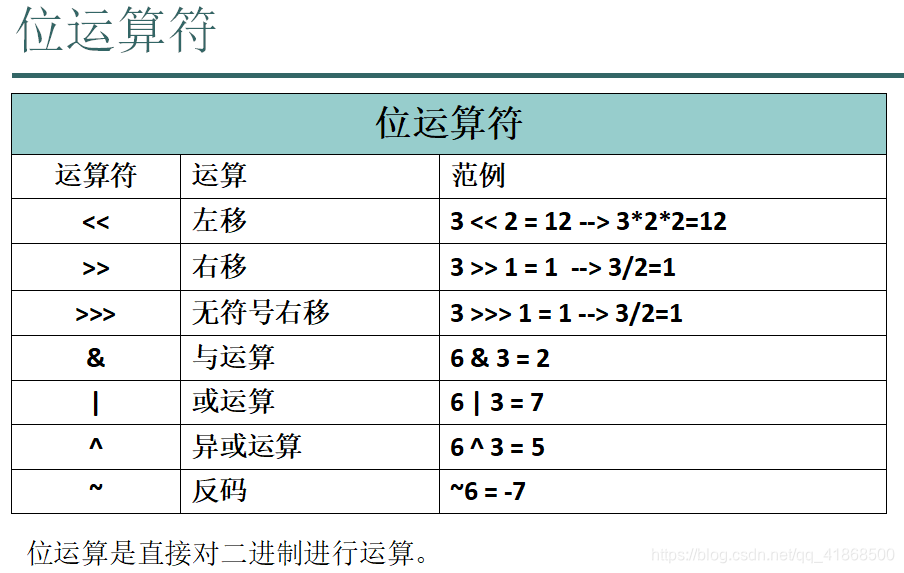
(1)<<:空位补0,被移除的高位丢弃。
算法:<<把<<左边的数据*2的移动次幂
(2)>>:被移位的二进制最高位是0,右移后,空缺位补0; 最高位是1,最高位补1。
算法:>>把>>左边的数据/2的移动次幂
(3)>>>:被移位二进制最高位无论是0或者是1,空缺位都用0补。
(4)&:任何二进制位和0进行&运算,结果是0; 和1进行&运算结果是原值。(0代表false,1代表true)
(5)|:任何二进制位和0进行 | 运算,结果是原值; 和1进行 | 运算结果是1。(0代表false,1代表true)
(6)^:任何相同二进制位进行 ^ 运算,结果是0; 不相同二进制位 ^ 运算结果是1。(0代表false,1代表true)
^的特点:某一个数据对另一个数据异或两次,结果不变
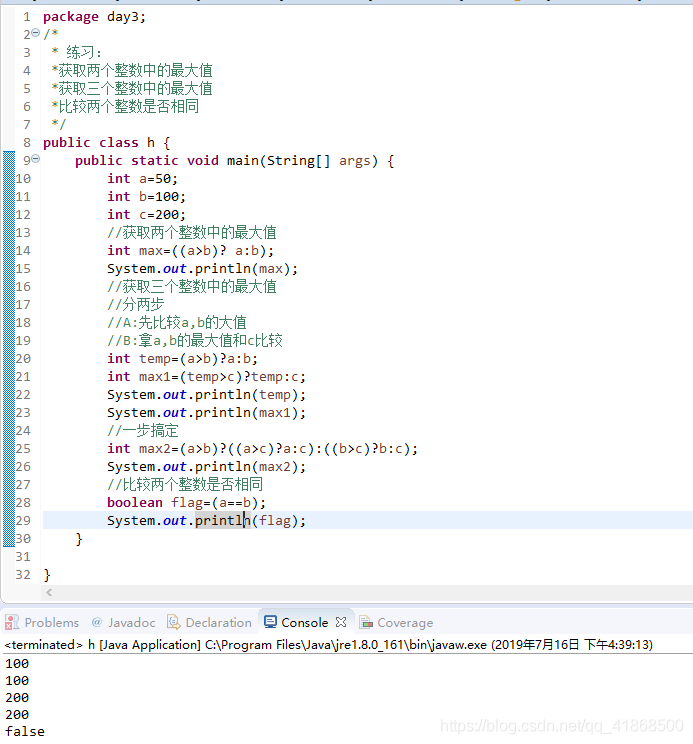
6.三元运算符:
格式:(关系表达式)?表达式1:表达式2;
如果条件为true,运算后的结果是表达式1;
如果条件为false,运算后的结果时表达式2;
注意:布尔类型格式后面不需要跟true和false,因为它本身就是布尔类型。
十一:键盘录入数据
概述:我们目前在写程序的时候,数据值都是固定的,但是实际开发中,数据值肯定是变化的,所以,我准备把数据改进为键盘录入,提高程序的灵活性。
如何实现键盘录入数据呢?(目前先记住使用)
导包(位置放到class定义的上面) import java.util.Scanner;
创建对象 Scanner sc = new Scanner(System.in);
接收数据 int x = sc.nextInt();
十二:流程控制语句
流程控制语句分类:
1.顺序结构:从上往下,依次执行
2.选择结构:按照不同的选择执行不同的代码
if语句 :if语句有三种格式
if语句第一种格式:
if(关系表达式) {
语句体
}
执行流程 :
(1)首先判断关系表达式看其结果是true还是false
(2)如果是true就执行语句体 如果是false就不执行语句体
注意事项:
(1)关系表达式无论简单还是复杂,结果必须是boolean类型
(2)if语句控制的语句体如果是一条语句,大括号可以省略;如果是多条语句,就不能省略,建议永远不要省略
(3)一般来说,有左大括号就没有分号,有分号就没有左大括号
if语句第二种格式:
if(关系表达式) {
语句体1;
}else { 语句体2;
}
执行流程:
(1)首先先判断关系表达式看其结果是true还是false
(2)如果是true就执行语句体1
(2)如果是false就执行语句体2
三元运算符和if语句格式二的区别:
三元运算符实现的,都可以采用if语句实现,反之不成立
什么时候if语句实现不能用三元改进呢?当if语句控制的操作时一个输出语句的时候就不能,因为三元运算符是一个运算符,
运算符操作完毕后就应该有一个结果,而不是输出
if语句第三种格式:
if(关系表达式1) {
语句体1;
}else if (关系表达式2) {
语句体2; }
…
else {
语句体n+1; }
执行流程:
(1)首先判断关系表达式1看其结果时false还是true
(2)如果是true就执行语句体1
(3)如果是false就继续判断关系表达式2看其结果是true还是false
(4)如果是true就执行语句体2
(5)如果是false就继续判断关系表达式.....看其结果时true还是false
(6)......
(7)如果没有任何关系表达式为true,就执行语句体n+1
if语句的使用场景:
(1)针对一个表达式时boolean类型的判断
(2)针对一个范围的判断
(3)if语句是可以嵌套使用的
switch语句:
格式:
switch(表达式) {
case 值1:
语句体1;
break;
case 值2:
语句体2;
break;
…
default:
语句体n+1;
break;
格式解释 :
switch表示这是switch语句
表达式的取值:byte,short,int,char JDK5以后可以是枚举 JDK7以后可以是String
case后面跟的是要和表达式进行比较的值 语句体部分可以是一条或多条语句 break表示中断,结束的意思,可以结束switch语句 default语句表示所有情况都不匹配的时候,就执行该处的内容,和if语句的else相似。
执行流程:
(1)首先计算出表达式的值
(2)其次,和case依次比较,一旦有对应的值,就会执行相应的语句,在执行过程中,遇到break就会结束
(3)最后,如果所有的case都和表达式的值不匹配,就会执行default语句体部分,然后程序结束掉
注意事项:
(1)case后面只能跟常量,不能是变量,而且,多个case后面的值不能出现相同的
(2)default可以省略,但是不建议,除非判断的值的固定的
(3)break可以省略,但是不建议,否则结果可能不是你想要的
(4)default的位置可以出现在switch的任意位置
(5)switch的结束条件:遇到break或者执行到程序的末尾
if语句和switch的区别:
if语句使用场景:
针对结果是boolean类型的判断
针对一个范围的判断
针对几个常量值的判断
switch语句使用场景:
针对几个常量值的判断
3.循环结构:主要做一些重复的代码
循环语句的组成:
初始化语句:一条或者多条语句,这些语句完成一些初始化操作
判断条件语句:这是一个boolean表达式,这个表达式能决定是否执行循环体
循环体语句:这个部分是循环体语句,也就是我们要多次做的事情
控制条件语句:这个部分在一部分循环体结束后,下一次循环判断条件前执行,通过用于控制循环条件中的变量,使得循环在合适的时候结束
for循环语句格式:
for(初始化语句;判断条件语句;控制条件语句;){
循环体结构;
}
执行流程:
A:执行初始化语句
B:执行判断条件语句,看其结果时truehaisfalse
(1)如果是true,继续执行
(2)如果是false,循环结束
C:执行循环体语句
D:执行控制条件语句
E:回到B继续执行
注意事项:
A:判断条件语句的结果是一个boolean类型
B:循环体语句如果是一条语句,大括号可以省略;如果是多条语句,大括号不能省略。建议永远不要省略。
C:一般来说:有左大括号就没有分号,有分号就没有左大括号
while循环语句格式:
基本格式:
while(判断条件语句){
循环体语句;}
扩展格式:
初始化语句:
while(判断条件语句){
循环体语句;
控制条件语句;}
while和for循环的区别:
使用区别:控制条件语句所控制的那个变量,在for循环结束后就不能再访问到了,而while循环结束后还可以继续使用,如果你想继续使用就用while循环,否者推荐使用for循环,原因是for循环结束,该变量就从内存中消失,能够提高内存的使用效率
场景区别:
for循环适合针对一个范围判断进行操作
while循环适合判断次数不明确操作
do…while循环语句格式:
基本格式:
do{
循环体语句;
}while(判断条件语句);
扩展格式:
初始化语句;
do{
循环体语句;
控制条件语句;
}while(判断条件语句);
循环语句的区别:
do…while循环至少会执行一次循环体。
for循环和while循环只有在条件成立的时候才会去执行循环体
优先考虑for循环,其次考虑while循环,最后考虑do...while循环
注意事项:
写程序优先考虑for循环,再考虑while循环,最后考虑do…while循环。
如下代码是死循环
while(true){}
for(;;){}
循环嵌套:就是循环语句的循环体本身是一个循环语句。
十三:跳转控制语句
break 中断:
使用场景:
A:switch语句中
B:循环语句中加入了if判断的情况
注意:离开上面的两个场景,无意义
如何使用:
A:跳出单层循环
B:跳出多层循环
带标签的跳出,(格式:标签名:循环语句)
标签名要符合java要求
continue继续:
使用场景:
A:在循环语句中
B:离开使用场景的存在时没有意义的
作用:
单层循环对比break,然后总结两个区别
A:break跳出单层循环
B:continue跳出一次循环,进入下一次的执行
也可以带标签的使用
return返回:
作用:它的作用不是拿来结束循环的,而是拿来结束方法的
十四:方法和数组
方法定义:
完成特定功能的代码块
注意:在很多语言里面有函数的定义,而java里面的函数被称为方法
方法格式:
修饰符 返回值类型 方法名(参数类型 参数名1,参数类型参数名2,......){
函数体;
ruturn 返回值;}
详细解释:
修饰符:目前就用public static ,后面我们再详细的讲解其他的修饰符
返回值类型:就是功能结果的数据类型
方法名:符合命名规则即可,方便我们的调用
参数:
实际参数:就是实际参与运算的
形式参数:就是方法定义上的,用于接收实际参数的
参数类型:就是参数的数据类型
参数名:就是变量名
方法体语句:就是完成功能的代码
return:结束方法的
返回值:就是功能的结果,由return带给调用者
方法的执行特点:不调用不执行
基本类型和引用类型的区别:
基本类型:形式参数的改变对实际参数没有影响
引用类型:形式参数的改变直接影响实际参数
方法调用:
有明确返回值的调用:
(1)单独调用:sum(x,y);
一般来说没有意义,所以不推荐
(2)输出调用:System.out.println(sum(x,y));
但是不够好,因为我们可能需要对结果进行进一步的操作
(3)赋值调用:int result =sum(x,y); System.out.print(result);
推荐方案
画图解释调用流程:

方法注意事项:
(1)方法不调用不执行
(2)方法与方法之间是层级关机,不能嵌套定义
(3)方法定义的时候参数之间用逗号隔开
(4)方法调用时不需要再传递数据类型
(5)如何方法有明确的返回值,一定要有return带回一个值
没有明确返回值的调用:
(1)没有明确的返回值时返回值类型为void
(2)没有明确的返回值时只能使用单独调用,不能使用输出调用和赋值调用:sum(x,y);
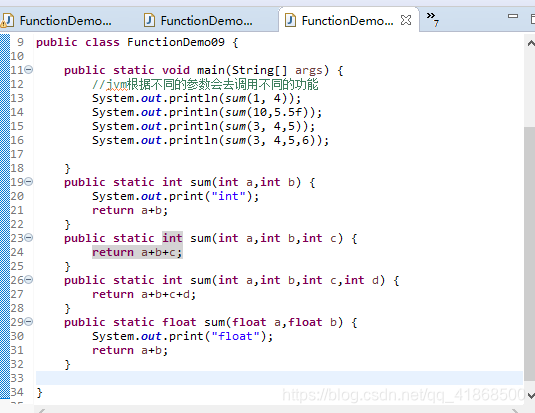
方法重载:
方法重载定义:在同一类中,允许存在一个以上的同名方法,只要他们的参数个数或者参数类型不同即可
方法重载特点:
(1)与返回值类型无关,只看方法名和参数列表
(2)在调用时,虚拟机通过参数列表的不同来区分同名方法
参数列表:参数类型不同、参数个数不同
如下图例子:
方法递归在IO之前详细讲解
数组概念:
(1)数组是存储同一种数据类型多个元素的组合,也可以看成是一种容器
(2)数据既可以存储基本的数据类型,也可以存储引用数据类型
数据定义格式:
格式1:数据类型[] 数组名;
格式2:数据类型 数组名[];
数组初始化概述:
(1)java中的数组必须先初始化,然后才能使用
(2)所谓初始化:就是为数据中的数据元素分配内存空间,并为每个数组赋值
数组的初始化方式:
动态初始化:初始化时只指定数据长度,由系统为数组分配初始值
格式:数据类型[] 数组名 = new 数据类型[数据长度];
数据长度其实就是数组中元素的个数
赋值:数组名[索引]=值;
静态初始化:初始化时指定每个数组元素的初始值,由系统决定数组长度
格式:数据类型[] 数组名=new[]{元素1,元素2,.......}
获取数组元素格式:数组名[索引] (索引就是每个元素的编号,从0开始,最大索引是数组的长度-1)
获取数组长度格式:数组名.length

注意事项:不要同时动态和静态进行,如下格式int[] a=new int[3]{1,2,3};
数组操作的两个常见小问题:
数组索引越界:ArrayIndexOutOfBoundsException
原因:你访问了不存在的索引
空指针异常:NullPointerException
原因:数组已经不再指向堆内存了,而你还用数组名去访问元素
二维数组:
动态初始化格式1:
数据类型[][]变量名 = new数据类型[m][n];
m表示这个二维数组有多少个一维数组
n表示每一个一维数组的元素个数
举例:
int[][] arr = new int[3][2];
定义了一个二维数组arr 这个二维数组有3个一维数组,名称是arr[0],arr[1],arr[2]
每个一维数组有2个元素,可以通过arr[m][n]来获取 表示获取第m+1个一维数组的第n+1个元素
动态初始化格式2:
数据类型[][] 变量名=new 数据类型[m][];
m表示这个数组有多少个一维数组
这一次没有直接给出一维数组的元素个数,我们可以动态给出
动态分配元素:数组名[一维数组索引]=new 数据类型[元素长度];
赋值:数组名[一维数组索引][元素索引]=值;
举例:
//动态为每一个一位数组分配元素
a[0]=new int[3];
a[1]=new int[2];
a[2]=new int[2];//给数组元素赋值
a[0][0]=100;
a[0][1]=200;
a[0][2]=300;
a[1][0]=400;
静态初始化格式3:
数据类型[][] 变量名=new 数据类型[][]{{元素......},{元素......},{元素......}};
简化版格式:数据类型[][] 变量名={{元素......},{元素......},{元素......}};
举例:int[][] a={{1,2,3},{2,4},{3}};
Java中的内存分配以及栈和堆的区别:
java中程序为了提交代码的效率,就对数据进行了不同空间的分配
具体的划分为如下5个内存空间:
1.栈 :存放的是局部变量
局部变量:在方法定义中或者方法声明上的变量都成为局部变量
栈特点: 内存的数据用完就释放掉,这个释放一定是在这个数据脱离了她的作用域
栈内存的两个引用指向同一个堆内存空间,无论是它们谁的操作,都是针对同一个地方
2.堆:存放的是所有new出来的东西
栈内存的两个引用指向同一个堆内存空间,无论是它们谁的操作,都是针对同一个地方
堆特点:
(1)使用完毕后就变成了垃圾,但没有立即回收,会在垃圾回收器空闲的时候回收
(2)每一个new出来的东西都有地址值,这个地址值会赋值给变量名
(3)每个变量都有默认值

3.方法区:(面向对象部分详细讲解)
4.本地方法区:和系统相关
5.寄存器:CPU使用
十五:面向对象
1.面向对象思想:面向对象是基于面向过程的编程思想
面向过程:强调的是每一个功能的步骤
面向对象:强调的是对象,然后由对象去调用功能
2.面向对象的特点:
A:是一种更符合我们思想习惯的思想
B:可以将复杂的事情简单化
C:将我们从执行者变成了指挥者
3.开发、设计、特征:
面向对象开发:就是不断的创建对象,使用对象,指挥对象做事情
面向对象设计:管理和维护对象之间的关系
面向对象特征:封装(encapsulation)、继承(inheritance)、多态(polymorphism)
4.类与对象的关系:
类:是一组相关的属性和行为的集合,是一种抽象的概念
对象:是该类食物的具体表现形式,具体存在的个体
距离:
学生:类
班长、副班长:对象
5.类的定义:定义类就是在定义类的成员(成员变量和成员方法)
成员变量:和以前变量的定义是一样的格式,但是位置不同,在类中方法外
成员方法:和以前变量的定义是一样的格式,现在先把static去掉
如何使用:
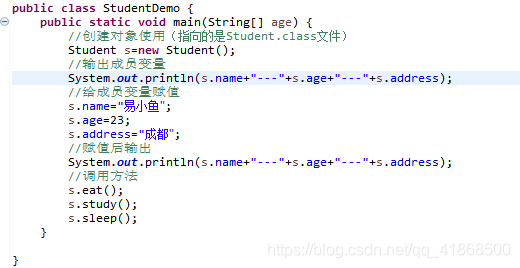
创建对象: 类名 对象名 = new 类名();
使用变量:对象名.成员变量
使用方法:对象名.成员方法();
如何给成员变量赋值:对象名.成员变量=值;(定义的成员变量是什么类型值就必须是什么类型)
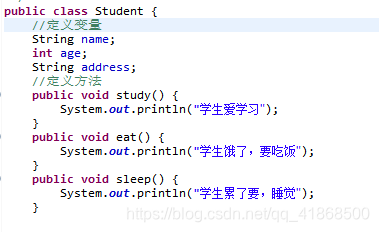
6.成员变量和局部变量的区别
A:在类中的位置不同
成员变量:在类中方法外
局部变量:在方法定义中,或方法声明外
B:在内存中的位置不同
成员变量:在堆内存
局部变量:在栈内存
C:生命周期不同
成员变量:随着对象的创建而存在,随着对象的消失而消失
局部变量:随着方法的调用而存在,随着方法的调用完毕而消失
D:初始化值不同
成员变量:有默认初始化值
局部变量:没有默认初始化值,必须定义赋值才能使用
注意事项:局部变量名称可以和成员变量名称一样,在方法中使用的时候采用的是就近原则
7.实际参数和形式参数的区别
实际参数:就是实际参与运算的
形式参数:就是方法定义上的,用于接收实际参数的
8.形式参数基本类型和引用类型的区别
基本类型:形式参数的改变不影响实际参数
引用类型:形式参数的改变直接影响实际参数
注意:如果你看到一个方法的形式参数是一个类类型(引用类型),这里其实需要的是该类的对象
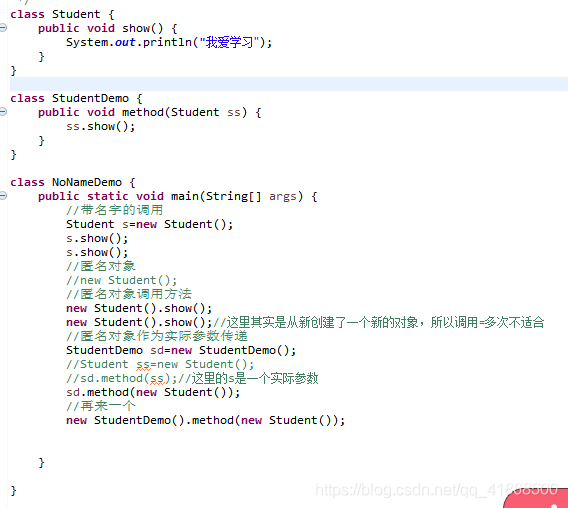
9.匿名对象
匿名对象:没有名字的对象
匿名对象的应用场景:
A:对象调用方法仅仅一次的时候
注意:调用多次的时候不适合
好处:匿名对象调用完毕后就是垃圾,可以被垃圾回收器回收
B:作为实际参数传递
10.封装
封装概述:是指隐藏对象的属性和实现细节,仅对外提供公共访问方式
好处:
(1)隐藏实现细节,提供公共访问方式
(2)提高了代码的复用性
(3)提高安全性
封装原则:
(1)将不需要对外提供的内容都隐藏起来
(2)把属性隐藏,提供公共的访问方式
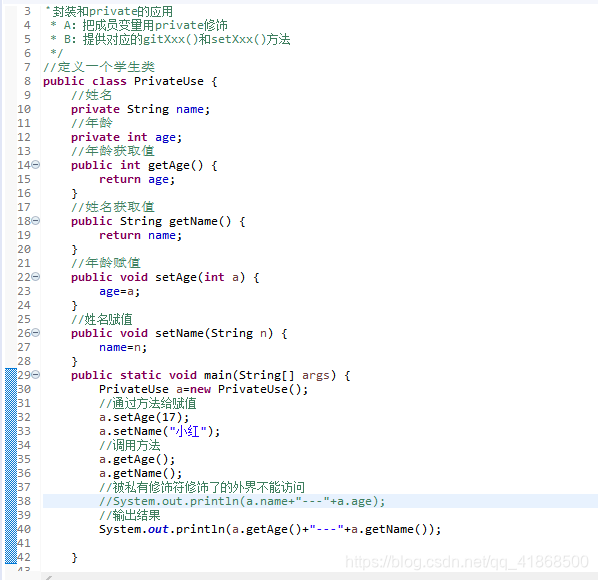
private关键字:
(1)是一个权限修饰符
(2)可以修饰成员(成员变量和成员方法)
(3)如果类的成员被private访问控制符修饰,则这个成员只能被该类的其他成员访问,其他类无法直接访问
private最常见的应用:
(1)把成员变量用private修饰
(2)提供对应的gitXxx()/setXxx()方法
(3)一个标准案例的使用
this关键字:
this:代表所在类的对象引用
记住:方法被哪个对象调用,this就代表哪个对象
什么时候使用this呢?
(1)局部变量隐藏成员变量
(2)其他用法后面和super一起讲
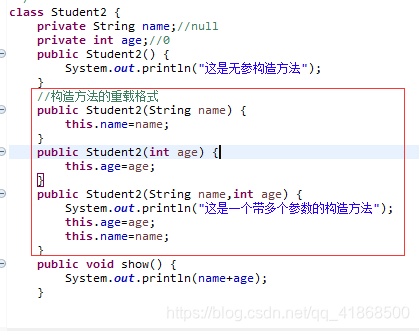
构造方法:
构造方法作用概述:给对象的数据进行初始化
构造方法格式:
(1)方法名与类相同
(2)没有返回值类型,连void都没有
(3)没有具体的返回值
构造方法注意事项:
(1)如果你不提供构造方法,系统会默认给出构造方法
(2)如果你提供了构造方法,系统将不再提供
(3)如果我们还想使用无参构造方法,就必须自己给出,建议永远自己给出无参构造方法
(4)构造方法也是可以重载的(以数据类型来区分)
重载案例:
类的成员方法;
方法具体划分:
(1)根据返回值:
有明确返回值类型
void返回值类型
(2)根据形式参数
无参方法
带参方法
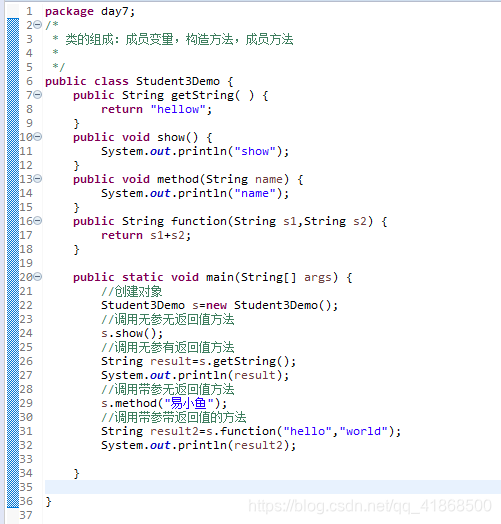
一个基本类的标准代码写法:
1.类:
(1)成员变量
(2)构造方法:
无参构造方法
带参构造方法
(3)成员方法
gitXxx()
setXxx()
2.给成员变量赋值的方式:
(1)无参构造方法+setXxx()
(2)带参构造方法
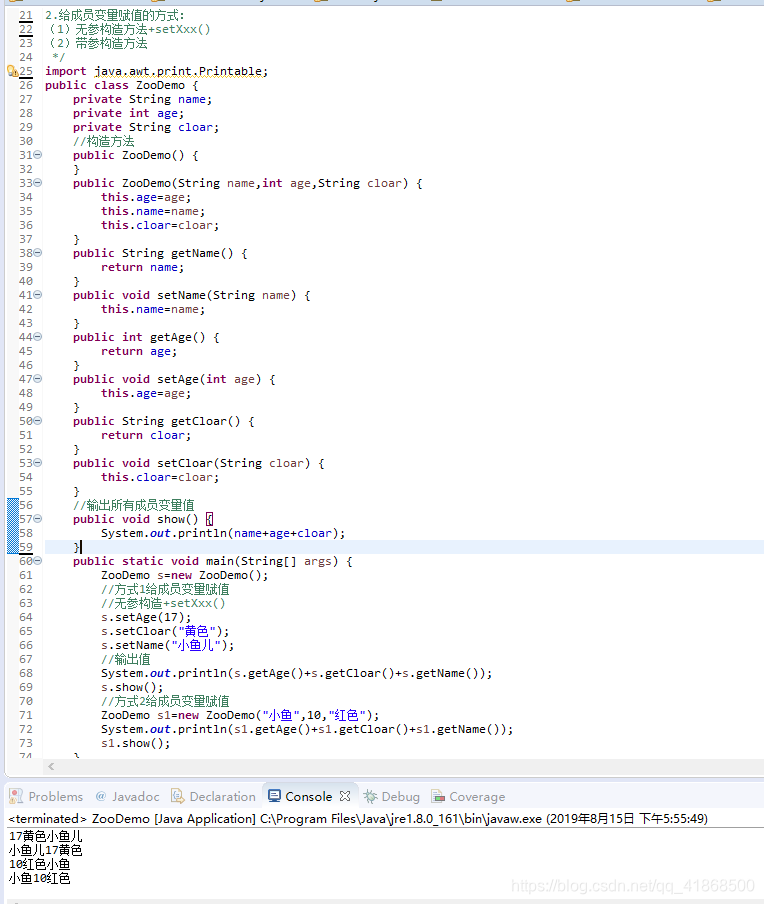
类的初始化过程:
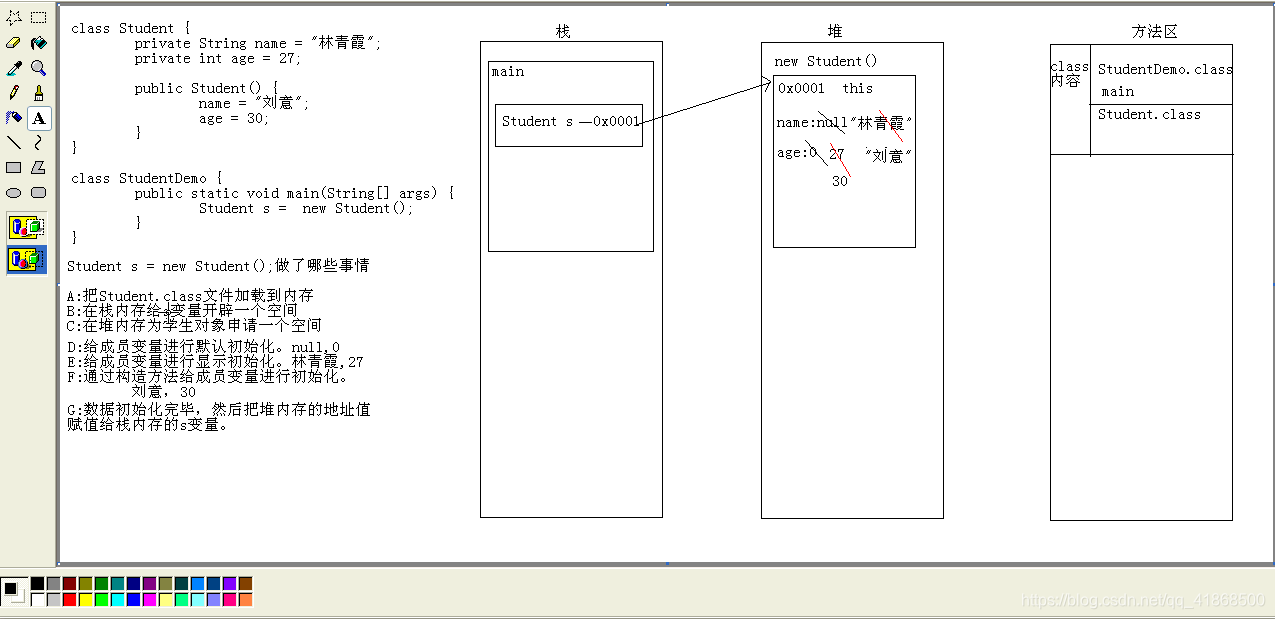
Student s = new Student();在内存中做了哪些事情?
A:加载Student.class文件进内场
B:在栈内场为s开辟空间
C:在堆内存为学生对象开辟空间
D:对学生对象的成员变量进行默认初始化
E:对学生对象的成员变量进行显示初始化
F:通过构造方法对学生对象的成员变量赋值
G:学生对象初始化完毕,把对象地址赋值给s变量
static关键字:
可以修饰成员变量和成员方法
static关键字特点:
A:随着类的加载而加载
B:优先于对象存在
C:被类的所有对象共享:这也是我们判断是否使用静态关键字的条件
D:可以通过类名调用:静态修饰的内容一般我们叫做与类相关的,也叫类成员
static关键字注意事项:
A:在静态方法中时没有this关键字的
如何理解:
静态是随着类的加载而加载,this是随着对象的创建而存在
静态比对象先存在
B:静态方法只能访问静态的成员变量和静态的成员方法
静态方法:
成员变量:只能访问静态变量
成员方法:只能访问静态成员方法
非静态方法:
成员变量:可以是静态的,也可以是非静态的
成员方法:可以是静态的成员方法,也可以是非静态的成员方法
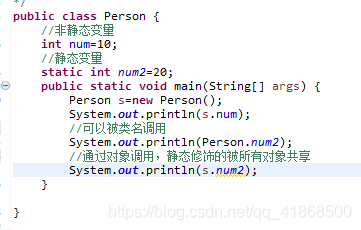
静态变量和成员变量的区别:
所属不同:
静态变量属于类,所以也成为类变量
成员变量属于对象,所以也成为实例变量(对象变量)
内存中位置不同:
静态变量存储于方法区的静态区
成员变量处于堆内存
内存出现的时间不同:
静态变量随着类的加载而加载,随着类的消失而消失
成员变量随着对象的创建而存在,随着对象的消失而消失
调用不同:
静态变量可以通过类名调用,也可以通过对象调用
成员变量只能通过对象名调用
main方法是静态的:
public static void main(String[] args) {}
public被jvm调用,访问权限足够大
static被jvm调用,静态的,不用创建对象,直接访问类名
void被jvm调用,不需要给jvm返回值
main是一个常见的方法入口,一个通用的名称,虽然不是关键字,但是被jvm识别
String[] args 这是一个字符串数组,以前用于接收键盘录入的,格式是:java MainDemo HelloWord word java
制作帮助文档:
制作工具类 :ArrayTools
制作帮助文档(API) :javadoc -d 目录 -author -version ArrayTool.java
如何使用帮助文档:
1:打开帮助文档
2:点击显示,找到索引,看到输入框
3:知道你要找谁?以Scanner举例
4:在输入框里面输入Scanner,然后回车
5:看包
java.lang包下的类不需要导入,其他的全部需要导入。
要导入:
java.util.Scanner
6:再简单的看看类的解释和说明,别忘了看看该类的版本
7:看类的结构
成员变量 字段摘要
构造方法 构造方法摘要
成员方法 方法摘要
8:学习构造方法
A:有构造方法 就创建对象
B:没有构造方法 成员可能都是静态的
9:看成员方法
A:左边
是否静态:如果静态,可以通过类名调用
返回值类型:人家返回什么,你就用什么接收。
B:右边
看方法名:方法名称不要写错
参数列表:人家要什么,你就给什么;人家要几个,你就给几个
代码块:
局部代码块:局部位置,用于限定变量的生命周期
构造代码块:在类的成员位置,用{}括起来的代码,每次调用构造方法执行前都会先执行代码块
作用:可以把多个构造方法中共同代码放到一起,对对象进行初始化
静态代码块:在类中成员位置,用{}括起来的代码,只是他用static修饰了
作用:一般是对类进行初始化,在加载的时候就进行执行,并且只执行一次
执行顺序:静态代码块---构造代码块---构造方法
静态代码块:只执行一次
构造代码块: 每次调用构造方法都执行
继承:
继承概述:多个类中存在相同属性和行为时,将这些内容抽取到单独一个类中,那么多个类无需在定义这些属性和行为,只需要继承那个类即可
通过extends关键字可以实现类与类的继承:class 子类名 extends 父类名{}
单独的这个类称为父类,基类或者超类;多个类可以称为子类或者派生类。
继承的好处:
(1)提高了代码的复用性:多个类相同的成员可以放到一个类中
(2)提高了代码的维护性:如果功能的代码需要修改,修改一处即可
(3)让类与类之间产生了关系是多态的前提:其实这也是继承的一种弊端:类的耦合性很强
继承特点:
1.java只支持单继承,不支持多继承
(1)一个类只可以有一个父亲,不可以有多个父亲
class SubDemo extends Demo{} //ok
class SubDemo extends Demo1,Demo2...//error
2.java支持多层继承(继承体系)
class A{}
class B extends A{}
class C extends B{}
Java中继承的注意事项:
(1)子类只能继承父类所有非私有方法的成员(成员方法和成员变量)
其实这也提现了继承的另一只弊端:打破了封装性
(2)子类不能继承父类的构造方法,但是可以通过super(后面讲)去访问父类的构造方法
(3)不要为了部分功能而去继承
(4)我们到底在什么时候使用继承呢?
继承中类之间提现的是:“is a”的关系


















 9万+
9万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











