




1、java基础
1.1java基础语法
1.1.1、变量,数据类型
(1)int和integer的区别
延伸:
关于Integer和int的比较
1、由于Integer变量实际上是对一个Integer对象的引用,所以两个通过new生成的Integer变量永远是不相等的(因为new生成的是两个对象,其内存地址不同)。Integer i = new Integer(100);
Integer j = new Integer(100);
System.out.print(i == j); //false2、Integer变量和int变量比较时,只要两个变量的值是相等的,则结果为true(因为包装类Integer和基本数据类型int比较时,java会自动拆包装为int,然后进行比较,实际上就变为两个int变量的比较)
Integer i = new Integer(100);
int j = 100;
System.out.print(i == j); //true3、非new生成的Integer变量和new Integer()生成的变量比较时,结果为false。(因为非new生成的Integer变量指向的是java常量池中的对象,而new Integer()生成的变量指向堆中新建的对象,两者在内存中的地址不同)
Integer i = new Integer(100);
Integer j = 100;
System.out.print(i == j); //false4、对于两个非new生成的Integer对象,进行比较时,如果两个变量的值在区间-128到127之间,则比较结果为true,如果两个变量的值不在此区间,则比较结果为false
Integer i = 100;
Integer j = 100;
System.out.print(i == j); //trueInteger i = 128;
Integer j = 128;
System.out.print(i == j); //falsejava在编译Integer i = 100 ;时,会翻译成为Integer i = Integer.valueOf(100);,而java API中对Integer类型的valueOf的定义如下:(源码)
public static Integer valueOf(int i){
assert IntegerCache.high >= 127;
if (i >= IntegerCache.low && i <= IntegerCache.high){
return IntegerCache.cache[i + (-IntegerCache.low)];
}
return new Integer(i);
}java对于-128到127之间的数,会进行缓存,Integer i = 127时,会将127进行缓存,下次再写Integer j = 127时,就会直接从缓存中取,就不会new了
(2)==和equals的区别
1)对于==,如果作用于基本数据类型的变量,则直接比较其存储的 “值”是否相等;
如果作用于引用类型的变量,则比较的是所指向的对象的地址
2)对于equals方法,注意:equals方法不能作用于基本数据类型的变量
如果没有对equals方法进行重写,则比较的是引用类型的变量所指向的对象的地址;
诸如String、Date等类对equals方法进行了重写的话,比较的是所指向的对象的内容。
(3)String 能被继承吗? StringBuider StringBuffer String之间的区别
都不能被继承:
源码是这样的:
public final class String extends Object
public final class StringBuffer extends AbstractStringBuilder implements java.io.Serializable, CharSequence
public final class StringBuilder extends AbstractStringBuilder implements java.io.Serializable, CharSequence
因为Sting是这样定义的:public final class String extends Object,里边有final关键字,所以不能被继承。(1)String 类
String的值是不可变的,这就导致每次对String的操作都会生成新的String对象,不仅效率低下,而且大量浪费有限的内存空间。
String a = "a"; //假设a指向地址0x0001a = "b";//重新赋值后a指向地址0x0002,但0x0001地址中保存的"a"依旧存在,但已经不再是a所指向的,a 已经指向了其它地址。
因此String的操作都是改变赋值地址而不是改变值操作。(2)StringBuffer
StringBuffer是可变类,和线程安全的字符串操作类,任何对它指向的字符串的操作都不会产生新的对象。 每个StringBuffer对象都有一定的缓冲区容量,当字符串大小没有超过容量时,不会分配新的容量,当字符串大小超过容量时,会自动增加容量。
StringBuffer buf=new StringBuffer(); //分配长16字节的字符缓冲区
StringBuffer buf=new StringBuffer(512); //分配长512字节的字符缓冲区
StringBuffer buf=new StringBuffer("this is a test")//在缓冲区中存放了字符串,并在后面预留了16字节的空缓冲区。3.StringBuffer
StringBuffer和StringBuilder类功能基本相似,主要区别在于StringBuffer类的方法是多线程、安全的,而StringBuilder不是线程安全的,相比而言,StringBuilder类会略微快一点。对于经常要改变值的字符串应该使用StringBuffer和StringBuilder类。String 字符串常量
StringBuffer 字符串变量(线程安全)
StringBuilder 字符串变量(非线程安全)
速度比较一般情况下,速度从快到慢:StringBuilder>StringBuffer>String,这种比较是相对的,不是绝对的。
(1).如果要操作少量的数据用 = String
(2).单线程操作字符串缓冲区 下操作大量数据 = StringBuilder
(3).多线程操作字符串缓冲区 下操作大量数据 = StringBuffer
1.1.2、if 循环语句
(1)乘法口诀表
for (int i = 1; i <= 9; i++) {
for (int j = 1; j <= i; j++) {
System.out.print(i + "x" + j + "=" + i * j + "\t");
}
System.out.println();
}(2)冒泡排序
int[] arr = {12,21,14,22,11,2};
for (int i = 0; i < arr.length ; i++) {
for (int j = 0; j < arr.length - 1 - i ; j++) {
if (arr[j] > arr[j + 1]) {
int temp = arr[j];
arr[j] = arr[j + 1];
arr[j + 1] = temp;
}
}
}
for(int m:arr) {
System.out.print(m+",");
}public class MaopaoSrot {
public static void maopaoSort(int[] arr) {
for (int i = 0; i < arr.length; i++) {
for (int j = 0; j < arr.length-1-i; j++) {
if (arr[j] > arr[j+1]) {
int temp = arr[j];
arr[j] = arr[j+1];
arr[j+1]=temp;
}
}
}
printArray(arr);
}
public static void printArray(int[] arr) {
System.out.print("(");
for (int i = 0; i < arr.length; i++) {
if (i != arr.length-1) {
System.out.print(arr[i] + ",");
}else {
System.out.print(arr[i]);
}
}
System.out.print(")");
}
public static void main(String[] args) {
System.out.println("冒泡排序");
int[] array = {22,1,2,43,32,2,2,1,};
printArray(array);
maopaoSort(array);
}
}(3)快速排序
import java.util.Arrays;
/**
* @author LPJ
* @version 1.0 创建时间:2018年3月3日 上午11:23:57
* describe:原理:采用单轴双向比较方法,设置基准值,首次循环从后向前对比,当小于基准值时,交换,然后从开始
* 位置与基准值进行比较,当大于基准值时,进行交换。全部结束后,元素分为两部分,右侧为大于基准值,左侧为小于基准值
* 然后将两部分分别递归调用排序方法
*/
public class QucikSort {
public static void main(String[] args) {
int [] aa = {3,2,45,21,5};
System.out.println(Arrays.toString(aa));
aa = quickSort1(aa);
System.out.println(Arrays.toString(aa));
}
static int[] quickSort1(int [] a) {
return quickSort(a, 0, a.length - 1);
}
//快速排序方法
static int[] quickSort(int [] a,int low, int high) {
int start = low;//记录起始位置
int end = high;//记录终点位置
int key = a[low];//记录分界点值,基准值
//首次循环
while(start < end) {
//从后向前比较,如果大于基准值,继续向前
while(start < end && a[end] >= key)
end--;
//如果小于基准值,进行交换
a[start] = a[end] + (a[end] = a[start]) * 0;
//从前向后比较,如果小于基准值,继续向后
while(start < end && a[start] <= key)
start++;
//如果大于基准值,进行交换
a[start] = a[end] + (a[end] = a[start]) * 0;
}
//递归,分成两部分,此时start = end
//基准值以及以前的部分,重复递归end-1
//基准值以及以后的部分,重复递归end+1
if(start > low) quickSort(a, low, end - 1);
if(end < high) quickSort(a, end + 1, high);
return a;
}
}(4)说说你认识的所有的排序的算法,让你按效率排序一下。
快速排序 > 插入排序 > 选择排序 > 冒泡排序
1.1.3、集合
(1)HashTable HashMap的区别
HashMap不是线程安全的
hastmap是一个接口 是map接口的子接口,是将键映射到值的对象,其中键和值都是对象,并且不能包含重复键,但可以包含重复值。HashMap允许null key和null value,而hashtable不允许。
HashTable是线程安全的一个Collection。HashMap是Hashtable的轻量级实现(非线程安全的实现),他们都完成了Map接口,主要区别在于HashMap允许空(null)键值(key),由于非线程安全,效率上可能高于Hashtable。 HashMap允许将null作为一个entry的key或者value,而Hashtable不允许。 HashMap把Hashtable的contains方法去掉了,改成containsvalue和containsKey。因为contains方法容易让人引起误解。 Hashtable继承自Dictionary类,而HashMap是Java1.2引进的Map interface的一个实现。 最大的不同是,Hashtable的方法是Synchronize的,而HashMap不是,在多个线程访问Hashtable时,不需要自己为它的方法实现同步,而HashMap 就必须为之提供外同步。 Hashtable和HashMap采用的hash/rehash算法都大概一样,所以性能不会有很大的差
public static void main(String args[]) {
Hashtable<String, Integer> h=new Hashtable<String, Integer>();
h.put("用户1",new Integer(90));
h.put("用户2",new Integer(50));
h.put("用户3",new Integer(60));
h.put("用户4",new Integer(70));
h.put("用户5",new Integer(80));
Enumeration<Integer> e=h.elements();
while(e.hasMoreElements()){
System.out.println(e.nextElement());
}
}总结:
| hashmap | 线程不安全 | 允许有null的键和值 | 效率高一点、 | 方法不是Synchronize的要提供外同步 | 有containsvalue和containsKey方法 | HashMap 是Java1.2 引进的Map interface 的一个实现 | HashMap是Hashtable的轻量级实现 |
| hashtable | 线程安全 | 不允许有null的键和值 | 效率稍低、 | 方法是是Synchronize的 | 有contains方法方法 | Hashtable 继承于Dictionary 类 | Hashtable 比HashMap 要旧 |
(2)HashMap和HashSet的区别
什么是HashMap
HashMap实现了Map接口,Map接口对键值对进行映射。Map中不允许重复的键。Map接口有两个基本的实现,HashMap和TreeMap。TreeMap保存了对象的排列次序,而HashMap则不能。HashMap允许键和值为null。HashMap是非synchronized的,但collection框架提供方法能保证HashMap synchronized,这样多个线程同时访问HashMap时,能保证只有一个线程更改Map。
public Object put(Object Key,Object value)方法用来将元素添加到map中。| HashMap | HashSet |
| HashMap实现了Map接口 | HashSet实现了Set接口 |
| HashMap储存键值对 | HashSet仅仅存储对象 |
| 使用put()方法将元素放入map中 | 使用add()方法将元素放入set中 |
| HashMap中使用键对象来计算hashcode值 | HashSet使用成员对象来计算hashcode值,对于两个对象来说hashcode可能相同,所以equals()方法用来判断对象的相等性,如果两个对象不同的话,那么返回false |
| HashMap比较快,因为是使用唯一的键来获取对象 | HashSet较HashMap来说比较慢 |
(3)Collection和Collections的区别
1、java.util.Collection 是一个 集合接口。它提供了对集合对象进行基本操作的通用接口方法。Collection接口在Java 类库中有很多具体的实现。Collection接口的意义是为各种具体的集合提供了最大化的统一操作方式。 Collection
├List
│├LinkedList
│├ArrayList
│└Vector
│ └Stack
└Set 2、java.util.Collections 是一个包装类。它包含有各种有关集合操作的静态多态方法,用于实现对各种集合的搜索、排序、线程安全化等操作。此类不能实例化,就像一个工具类,服务于Java的Collection框架。
import java.util.ArrayList;
import java.util.Collections;
import java.util.List;
public class TestCollections {
public static void main(String args[]) {
//注意List是实现Collection接口的
List list = new ArrayList();
double array[] = { 112, 111, 23, 456, 231 };
for (int i = 0; i < array.length; i++) {
list.add(new Double(array[i]));
}
Collections.sort(list);
for (int i = 0; i < array.length; i++) {
System.out.println(list.get(i));
}
// 结果:23.0 111.0 112.0 231.0 456.0
}
}(4)某个集合背后的数据结构
Hashmap数据结构:
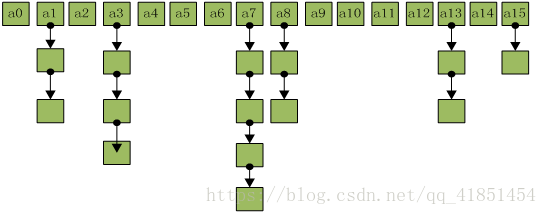
HashSet类:
Java.util.HashSet类实现了Java.util.Set接口。 它不允许出现重复元素; 不保证和政集合中元素的顺序 允许包含值为null的元素,但最多只能有一个null元素 |
List(列表):
List的特征是其元素以线性方式存储,集合中可以存放重复对象。 List接口主要实现类包括: ArrayList() : 代表长度可以改变得数组。可以对元素进行随机的访问,向ArrayList()中插入与与删除元素的速度慢。 LinkedList(): 在实现中采用链表数据结构。插入和删除速度快,访问速度慢。对于List的随机访问来说,就是只随机来检索位于特定位置的元素。 |
Map(映射):
Map 是一种把键对象和值对象映射的集合,它的每一个元素都包含一对键对象和值对象。 Map没有继承于Collection接口 从Map集合中检索元素时,只要给出键对象,就会返回对应的值对象。 |
(5)某个集合线程安全不安全
线程安全(Thread-safe)的集合对象:
| Vector HashTable StringBuffer |
非线程安全的集合对象:
| ArrayList : LinkedList: HashMap: HashSet: TreeMap: TreeSet: StringBulider: |
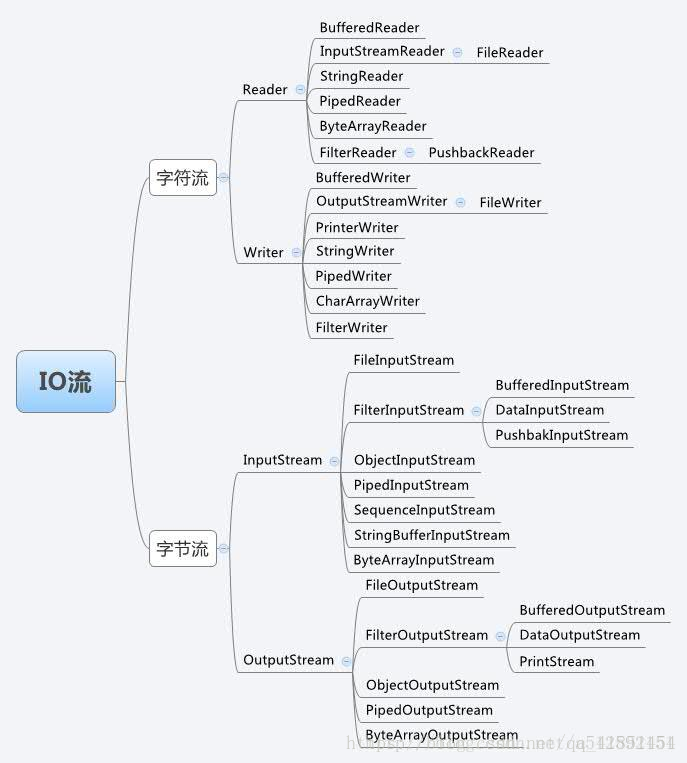
1.1.4、IO流
(1)说出常用的IO流的类,都有些什么特点
(1)InputStream 是所有的输入字节流的父类,它是一个抽象类;
(2)StringBufferInputStream从StringBuffer中读取数据;
(3)FileInputStream从本地文件中读取数据;
(4)OutputStream 是所有的输出字节流的父类,它是一个抽象类;
(5)FileOutputStream往本地文件中写入数据;
(6)Reader 是所有的输入字符流的父类,它是一个抽象类;
(7)Writer 是所有的输出字符流的父类,它是一个抽象类;
1.1.5、多线程(并发)
(1)sleep 和wait的区别
sleep()
sleep() 方法是线程类(Thread)的静态方法,让调用线程进入睡眠状态,让出执行机会给其他线程,等到休眠时间结束后,线程进入就绪状态和其他线程一起竞争cpu的执行时间。
因为sleep() 是static静态的方法,他不能改变对象的机锁,当一个synchronized块中调用了sleep() 方法,线程虽然进入休眠,但是对象的机锁没有被释放,其他线程依然无法访问这个对象。
wait()
wait()是Object类的方法,当一个线程执行到wait方法时,它就进入到一个和该对象相关的等待池,同时释放对象的机锁,使得其他线程能够访问,可以通过notify,notifyAll方法来唤醒等待的线程
(2)线程的创建的方式有几种,都有些什么特别。
1)继承Thread类创建线程类
1. 定义Thread类的子类,并重写该类的run方法,该run方法的方法体就代表了线程要完成的任务。因此把run()方法称为执行体。 2. 创建Thread子类的实例,即创建了线程对象。 3. 调用线程对象的start()方法来启动该线程。 |
2)通过Runnable接口创建线程类
1. 定义runnable接口的实现类,并重写该接口的run()方法,该run()方法的方法体同样是该线程的线程执行体。 2. 创建 Runnable实现类的实例,并依此实例作为Thread的target来创建Thread对象,该Thread对象才是真正的线程对象。 3. 调用线程对象的start()方法来启动该线程。 |
3)通过Callable和Future创建线程
1. 创建Callable接口的实现类,并实现call()方法,该call()方法将作为线程执行体,并且有返回值。 2. 创建Callable实现类的实例,使用FutureTask类来包装Callable对象,该FutureTask对象封装了该Callable对象的call()方法的返回值。 3. 使用FutureTask对象作为Thread对象的target创建并启动新线程。 4. 调用FutureTask对象的get()方法来获得子线程执行结束后的返回值 |
4、创建线程的三种方式的对比
采用实现Runnable、Callable接口的方式创见多线程时,优势是: 线程类只是实现了Runnable接口或Callable接口,还可以继承其他类。 在这种方式下,多个线程可以共享同一个target对象,所以非常适合多个相同线程来处理同一份资源的情况,从而可以将CPU、代码和数据分开,形成清晰的模型,较好地体现了面向对象的思想。 劣势是: 编程稍微复杂,如果要访问当前线程,则必须使用Thread.currentThread()方法。 使用继承Thread类的方式创建多线程时优势是: 编写简单,如果需要访问当前线程,则无需使用Thread.currentThread()方法,直接使用this即可获得当前线程。 劣势是: 线程类已经继承了Thread类,所以不能再继承其他父类。 |
(3)消费者和生产者
线程优先级:
| 优先级范围:1—10 设置线程t优先级的方法:t.setPriority(1--10) 获取线程t优先级的方法:t.getPriority() 线程优先级的默认值是:5 线程优先级为10的优先级最高,为1的最低 |
下面是一个生产者与消费者的示例,加深对多线程的理解与运用!!!
package com.thread.src;
public class Test {
public static void main(String[] args) {
//工具类
Utils u = new Utils();
//创建一个生产者线程
Productor p = new Productor(u);
//创建一个消费者线程
Customer c = new Customer(u);
//启动生产者和消费者线程
p.start();
c.start();
}
}package com.thread.src;
/**
* 生产者
* @author winy_lm
*
*/
public class Productor extends Thread{
//工具类
private Utils u;
//构造函数
public Productor(Utils u){
this.u = u;
}
//线程执行方法
public void run(){
while(true){
//每循环一次向data中放一个数据
//调用Utils类中的procuce()方法来生产
u.produce();
}
}
} package com.thread.src;
/**
* 消费者
* @author winy_lm
*
*/
public class Customer extends Thread{
//工具类
private Utils u;
//构造函数
public Customer(Utils u){
this.u = u;
}
//线程执行方法
public void run(){
while(true){
//每次从data中取一个数据
u.consume();
}
}
}package com.thread.src;
/**
* 工具类
* @author winy_lm
*
*/
public class Utils {
//被操作的数组,最多只能放三个,超过三个就等待,为0个的时候也等待
private int[] data = new int[3];
// 定义一个count用来标识data数据的个数
private int count = 0;
// 定义一个num用来表示,生产者上一次生产的数据
private int num = 0;
/*
* 如果一个类中的方法同时被2个或者多个线程访问, 那么我们就要把这个/这些方法同步,避免破坏数据完整性
*/
/**
* 此方法是完成生产向data放数据的功能
*/
synchronized public void produce() {
try {
if (count < 3) {
data[count] = num + 1;
System.out.println("生产者:" + (num + 1));
num = num + 1;
count++;
// 生产者生产数据之后 data中有数据了,消费者可以消费了
// 所以要唤醒消费者
notifyAll();
} else {
//等待被唤醒
wait();
}
} catch (InterruptedException e) {
e.printStackTrace();
}
}
/**
* 此方法用来供消费者线程调用,消费一个数据
*/
synchronized public void consume() {
try {
if (count > 0) {
int m = data[count - 1];
data[count - 1] = 0;
count--;
System.out.println("消费者:" + m);
// 因为我们已经消费了一个数据,data有空位,可以生产了
// 所以我们调用notifyAll()来唤醒生产者生产
notifyAll();
} else {
// else表明data中是空的,消费者不能消费,只有等待生产者生产
//等待被唤醒
wait();
}
} catch (InterruptedException e) {
e.printStackTrace();
}
}
} 
















 727
727

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









