




 本文详细介绍Hadoop伪分布式环境的搭建过程,包括JDK配置、Hadoop环境变量设定、核心配置文件修改及启动步骤。深入解析MapReduce、YARN等模块作用,适合初学者快速上手。
本文详细介绍Hadoop伪分布式环境的搭建过程,包括JDK配置、Hadoop环境变量设定、核心配置文件修改及启动步骤。深入解析MapReduce、YARN等模块作用,适合初学者快速上手。
hadoop伪分布式搭建
分布式
由分布在不同主机上的进程(程序)协同子啊一起才能构成整个应用。
Browser/web server:瘦客户端程序.
大数据4V特征
1.Volumn : 体量大
2.Velocity : 速度快
3.Variaty : 样式多
4.Value : 价值密度低
Hadoop
可靠的、可伸缩的、分布式计算的开源软件.
是一个框架、允许跨越计算机集群的大数据集处理,使用简单的编程模型(MapReduce)。
可从单个服务器扩展到几千台主机,每个节点提供了计算和存储的功能。而不是依赖高可用性的机器
依赖于应用层面上的实现,
Hadoop 模块
1.hadoop common 公共类库
2.HDFS hadoop 分布式文件系统
3.Hadoop Yarn 作业调度和资源管理框架
4.Hadoop MapReduce 基于yarn系统的大数据集并行处理技术
MapReduce 工作原理
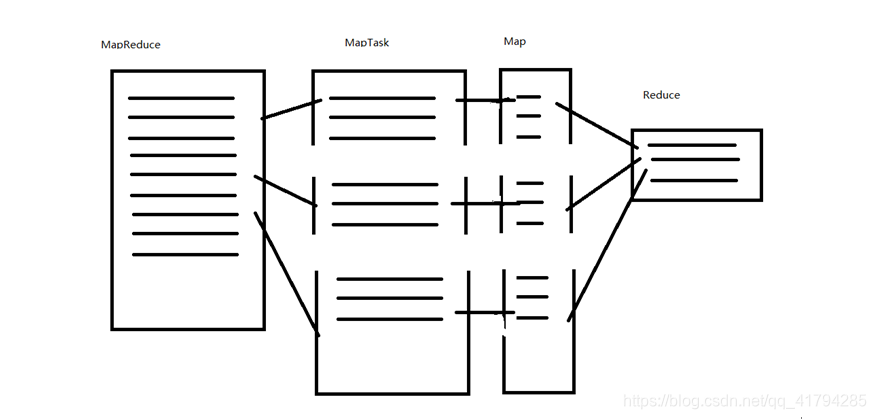
Hadoop安装
- jdk(建议使用JDK 1.8.11)
- 解压:tar-zxvf hadoop.tar.gz(建议使用Hadoop 2.7.3)
- 配置环境变量:
首先要确保jdk配置好:注意HOME下的路径是自己设置的路径
export HADOOP_HOME=/usr/soft/hadoop-2.7.3
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
export HADOOP_INSTALL=$HADOOP_HOME
配置hadoop各类site.xml文件
${HADOOP_HOME}/etc/hadoop/*-site.xml
-
单机模式:i.没有守护进程、所有程序运行在同一JVM中,利于test和debug
-
伪分布式模式:
-
cd /usr/soft/hadoop-2.7.3/etc/hadoop/
-
配置该文件夹下的xml文件
- 1.coresite-xml
- fs.defaultFS hdfs://192.168.10.125:9000 hadoop.tmp.dir /usr/soft/hadoop-2.7.3/tmp
- 3.Mapred-site-xml(CP)
- 由于hadoop配置文件中并没有Mapred-site-xml文件,所以需要复制一份Mapred-site-xml.template文件
- cd /usr/soft/hadoop-2.7.3/etc/hadoop/
- 进入文件夹
- cp mapred-site.xml.template mapred-site.xml
- 拷贝文件
- mapreduce.framewok.name yarn
- 设置化简模型框架为yarn框架
- 4.Yarn-site.xml
- yarn.resourcemanager.localhost localhost yarn.nodemanager.aux-service mapreduce_shuffle
cd .ssh/发现没有找到目录,说明生成秘钥对
生成秘钥对:
ssh-keygen -t rsa -P ‘’
捕捉免密登录秘钥:
cat id_rsa.pub>>authorized_keys
设置权限:
chmod 600 authorized_keys
- 关键一步:
- 在运行hadoop之前要在hadoop目录下的etc目录下找到
- export JAVA_HOME=${JAVA_HOME}
- 更改为自己jdk目录
- export JAVA_HOME=/usr/soft/jdk1.8.0_111/
- 启动命令start-all.sh
- 启动hadoop后发现仅有五个节点
- 6448 NodeManager
6562 Jps
6227 SecondaryNameNode
6071 DataNode
4877 ResourceManager - 关键第二步:
- 在启动之前,需要对namenode中的数据进行格式化,否则无法正常启动name节点
- 命令为:hdfs namenode -format
- 注意空格!
- 启动后输入jps
- 6448 NodeManager
6227 SecondaryNameNode
6821 NameNode
7301 Jps
6071 DataNode
4877 ResourceManager - 当出现六个节点时,大功告成
-


















 450
450

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









