



爬虫所遇反爬取措施
1、头信息User-Agent反爬虫策略
1.1、什么是User-Agent?
User-Agent是一种请求头,服务器可以从User-Agent对应的值中来识别用户端使用的操作系统、浏览器、浏览器引擎、操作系统语言等等。
浏览器User-Agent通常由浏览器标识、渲染引擎标识、版本信息这三部分来构成。
1.2、解决方法
1.2.1、简单粗暴
使用浏览器调试工具
按照下面步骤进行即可:
- 打开你要爬虫的网页
- 按键盘的F12或手动去浏览器右上角的“更多工具”选项选择开发者工具
- 按键盘的F5刷新网页
- 点击Network,再点击Doc
- 点击Headers,查看Request Headers的User-Agent字段,直接复制
1.2.2、进阶方法
使用random获取定义随机User-Agent达到每次请求头信息都改变的方法。
设置头信息方法,每次请求都调用方法,传入上次的链接来达到动态referer_url的步骤。
以及Python有不少库都可以随机生成User-Agent。
2、Ip限制
其实IP限制最好解决,只需要准备好一个IP池,然后结合多进程即可。虽然免费ip极不稳定,但是页奈不住在多线程和多进程的攻式下。
大部分网站都可以采用这样的方法解决。
然后可能就是还需要带上时间戳:int(time.time())即可
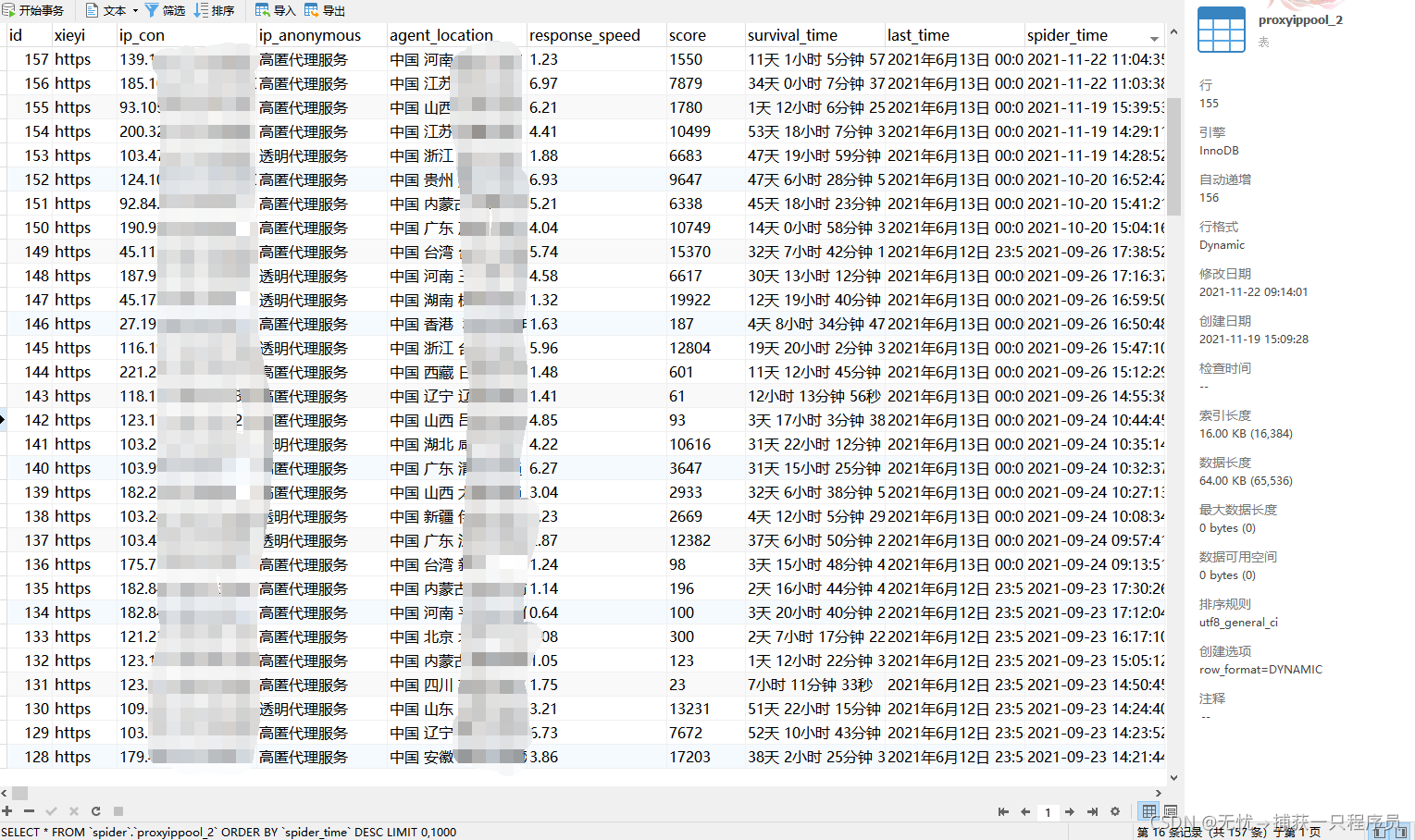
3、IP代理池
通过对网上众多IP筛选,选取相对可用的157个IP(条件允许的朋友可以购买付费的稳定IP)

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









