




长期更新,建议关注收藏点赞。
本文主要以AI为中心。
整体框架
-
例子:
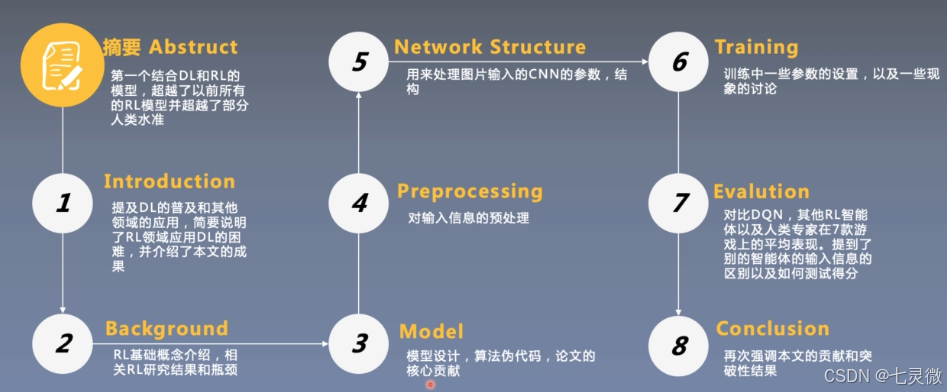
-
核心点:先选好故事讲好故事,以任务为切入点,讲技术点也要有技巧。
-
所有有可能创新的点
data->model->loss->opt【99%都出于data,model】->评估指标
如果说做开源数据集,也要出一个针对性的模型在这个上面表现好,并且这个数据集比当前有的数据集更好,或者应用场景独特。
数据才是真正意义上的壁垒。
曾经如何做的,当下如何做的,当下没做好的,当下还没做的
新方法解决新问题>新方法解决旧问题>旧方法解决新问题
可以选择别人已经做的,但是没做好或者还没做的地方;要理解以前人家是怎么做的,自然就知道他们还没做什么,重点在摘要。
- 如何选择合适的主题
实际:对于真实世界问题的适应
理论:探索解释性、可解释性、鲁棒性、安全性、隐私性、跨模态多模态 - 摘要很重要,阅卷老师没时间看那么多
模版:随着…发展,进步,当前的方法主要以…为主,完成,取得…成绩,但是只是聚焦于…的提取,导致在…场景下表现不好,为了完善…,提出一个方法…,用于…,我们提出了新颖的…,具体而言分为x个部分,为了促进…,提出了新的…,重新设计了…,通过大量的实验,表现…,与其他对比… - backbone迁移其实都可以做不同的任务,关键在于loss function的区别->用来约束任务
- method一样,怎么发?
故事不一样就行,模型没那么重要,找一个领域A+领域B结合成领域C,解决这个问题。可以再包装一下,加一些模块。模型的的优劣选最新最好的baseline很重要,其他地方稍微改一下也不会影响太多。先有故事,为了故事去创造模型,一开始就定好故事,然后找结构找点。 - 很多时候科研遇到瓶颈、idea没有work,是因为实验没有设计好,决定好故事基调后大部分时间都是在调模块,很多新手可以复现baseline,根据开源代码跑起来,但没从实验中总结新问题,应该验证别人的理论之后发现产生结论,尤其是熟练的把一个方向的模型换一个数据集跑起来并知道怎么讲这个故事。
- 新手如何选择参考?选择别人开源的给权重的给训练代码的来分析,知名度比较高的,对故事线梳理->找到问题,提出idea,换数据集或者换故事->做实验验证自己的idea,发掘新idea,得到自己的启发性建议->如果不能涨点,不要担忧,这只是剩下50%的工作了,不要急着调参和学习率(有限且不好迁移)
- 实验设计的方法:追求多样化、能不能更简单、能不能改更多、能不能跳出当前空间、能不能有更好的视觉效果、结合自己领域做大胆猜想、一定是全局比局部更优?、有没有可能极端场景不work
- 数据收集:选择经典开源数据集,最好选择给了权重的,观察论文代码中的预处理,考虑能否往自己的领域进行迁移学习;对于cv来说,改善图像、减少噪声、提取关键特征、使算法更易处理,常见的预处理:尺度调整、图片裁剪、各种滤波器提升图片质量、对像素值归一化处理将其缩放在固定范围内 BN batchnorm、AIGC生成数据。
深度学习的核心:不是分类、就是回归。encoding->decoding
- 语义分割 v.s. 显著性目标检测
将图像划分成有意义的区域,并且赋予每个区域标签。
目标检测是二分类语义分割 - GAN v.s. 语义分割模型
任务上主要区分还是在最后输出的层数和计算loss上
结构上毫无区别,GAN在img2img任务中主要多个D,但是D本身架构和Loss都是现成的 - SSM动态空间模型
最近Mamba系列(Mamba、VMamba、Vision Mamba)比较火,在同样具备高效长距离建模能力的情况下,Transformer具有平方级计算复杂度,而Mamba架构则是线性级计算复杂度,并且推理速度更快。所以Mamba的出现相当于对Transformer发出了挑战。
状态空间模型(State Space Model,简称SSM)是一种数学模型,用于描述和分析动态系统的行为。这种模型在多个领域都有应用,包括控制理论、信号处理、经济学和机器学习等。在深度学习领域,状态空间模型被用来处理序列数据,如时间序列分析、自然语言处理(NLP)和视频理解等。通过将序列数据映射到状态空间,可以更好地捕捉数据中的长期依赖关系。
由于视觉数据的位置敏感性、视觉理解所需要的全局上下文依赖性,表示视觉数据对于SSM而言是一项具有挑战性的任务。 - 善用docker 看成是一个虚拟机,跑别人的模型最好用虚拟环境给搭配好直接用
- 训练、测试、推理尽可能拆分
- 预训练权重非常重要,节约时间且提供给我们迁移到其他任务的基础
- 对比学习和CLIP
CLIP(Contrastive Language–Image Pretraining)(对比语言-图像预训练)是 OpenAI 在 2021 年发布的多模态 AI 模型,可以同时理解文本(自然语言)和图片。
分别将文本特征、图像特征计算相似性,则可以匹配分类,实现不用过分类器也能拿到类别。这里面的结构也可以拆开,
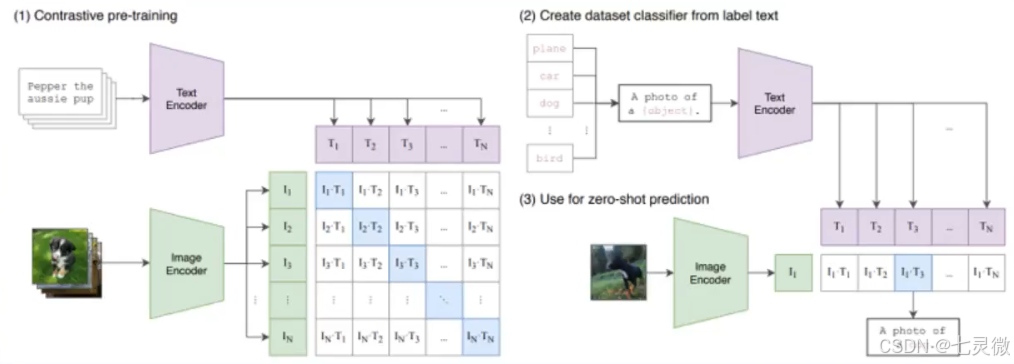
对比学习:希望自己训练的标签尽可能距离相似的类别近一些,距离偏远类别远一些。设计Loss要考虑正负样本,在CLIP任务中为了使图像和对应类别能匹配,使用三元组的设计方式(图像,正样本文本,负样本文本)跟正样本尽可能相似,跟负样本尽可能远。

使用对角线元素作为标签(labels),分别计算图像和文本方向上的交叉熵损失(loss i和loss t)。
这里的对称对比学习损失是将对角线上的元素作为正样本,其他元素作为负样本,将正样本的相似性视为类别概率,计算交叉熵损失最后,将图像和文本方向上的损失取平均得到最终的对比学习损失(loss)
在NLP里其实把图像部分换掉就是NLP的用法了,对比学习在Bert里主要也是计算句子之间的相似度,对于每个正负样本对,计算两个句子表示之间的相似度或距离。一种常见的方法是使用余弦相似度或欧氏距离来度量句子之间的相似性。在使用BERT进行对比学习时可以将预训练的BERT模型作为基础模型,根据具体任务进行微调或添加额外的层。一般主要还是应用在文本匹配,检索,以及做语句生成。
对比学习在常规数据集上可能表现没那么好,但在特殊设计过的数据集上可能很好。如何均衡对比学习中的loss也是一个新方向。 - stable diffusion SD
自从这个出现之后大部分情况已经用不到数学了。为什么SD方法最为人熟知?因为直接采样出图像的做法完全不可控,通过文本描述生成图像的可能,但文本不是唯一输入条件,需要更可控的方式,即大家熟知的controlnet。 - 正确看待采样器,不能靠这个发论文
- 只有 Unet输出的latent被训练
- 对文本的理解能力又不够用了,需要更大的文本编码器
- Unet图像理解能力又不够用了,需要增强图像的理解能力
- 如何不训练 避免训练 新的发论文的点
类controlnet微调形
sora一样重新训练型
上述区别主要是用什么文本编码器,用unet还是dit架构,以及vae是否用视频的增强解码稳定性 - diffusion+视频理解的前景
不要训练diffusion(太大了),搞其他的东西
文献综述
总结已有、展望未来(研究空白、未解决的问题)、发现趋势和前沿、提供实证基础支持。
认真的去总结里面提到的模块、算法、模型都是哪些、可以做迁移
对特定领域内的都要回顾和整合、分类、对比、局限性不足、简化细节(更适合初学者)、统计论文+数据集。
- 选哪些读?选档次高的今年的,再可以补充arixv的新论文。
先看图,统计的很好。【学术论文是反过来的,因为那些图其实ppt的画来画去都差不多】最重要的必看部分有引言背景、目标研究问题、文献收集和筛选方法、文献综合和分类、研究方法技术、结果讨论、结论总结。 - 学术论文 v.s. 文献综述
学术论文讲的是自己跟别人不一样的,比别人好的地方,强调自己是好的对的
文献综述讲的是求同存异,没有绝对的1+1=2的绝对结果,会得出许多新旧分支路线。
模型设计
挑模型就要发现哪个模型好,哪个可能发。


反向思考这个故事里面还缺什么东西。
模型设计可以考虑并行/串行
故事新颖、架构新颖、模块新颖。
不能直接拿两个现成的模型做A+B,必须要想办法在模型设计上变成C,可以同时取全局特征(比如transformer)、局部特征(attention)的两条链路,skip connection。multi-scale attention>多尺度简单连线>单一维度连线。
疑问:局部特征和全局特征到底能不能直接简单相加、连接,会不会冲突干扰?
假设是这样,则把这个故事讲好,需要一个平衡机制,它们二者在一个模块中融合。
一种顶会思路:全新architecture+全新feature processing+新的global feature local feature融合块+SOTA
如何把别人的东西放到自己这里用上?先跑通,效果好拿来用。先应用,再做创新。迁移是第一要义,换数据集、换故事、换模型。
如何避免做无用功?当前的某个领域到底缺什么东西,不是越大越好,要轻还效果好。一开始就要找一个跟别人都不一样的故事,然后再按照这个点去做一堆实验,哪个好用哪个。可以从架构去找目标,找某个特点主打的架构,几个架构看看能不能连几个分支,改动一下架构等等。
私有数据
- 证明数据具有普适性,模型都发挥的不错
- 模型在私有数据上还是有些缺陷
- 设计针对这个数据的模型 证明这个模型具有竞争力
- 要么大,要么复杂
实验实施和结果分析

调整超参数/loss等的长点的变化非常小,尽可能不要在这个上面做重点调整。
- 先学会跟别人一摸一样。论文结构一摸一样,话术套路一摸一样,实验写法也要跟别人一摸一样(不要展现的很奇怪),表放的越多、图放的越多越容易中,凑字数、伪代码加分,跟故事相似和架构相似的都要进行比较,由易到难投。
- 如何分辨可复现论文?
- 核心:基本知识和组件熟悉,如CNN, transformer, self-attention, 多尺度, 各种attention, skip connection,掌握这些和backbone的排列组合就能做出80%论文内容
- 新的知识和开源代码跑通和debug细节,能掌握很多奇怪操作,学到就是故事
- 很多复现不了是因为数据集、输入输出的细节流程
论文写作和结构学术
- 图和故事谁重要?
图不需要展示细节,只需要简洁(看图看不出技术含量和细节),故事是核心。 - 论文基本结构组织
模仿->修改->创新,但创新其实也不需要产生一个完全新的东西,只需要有不一样的点。
AI(人工智能)论文通常遵循标准的学术论文结构,以确保内容清晰、逻辑严密,并便于同行评审。一般包括以下几个部分:
- 标题(Title)
准确概括论文主题,简洁明了。
可能包含研究方法或创新点的关键词。

- 摘要(Abstract)
简要概述研究的背景、问题、方法、实验和主要结论。贡献是怎么写的
通常限制在 150-300 字以内。
文章写得好不好,只看摘要就知道了

- 关键词(Keywords)
提供 3-6 个核心关键词,便于检索,如 “deep learning”, “reinforcement learning”。 - 引言(Introduction)
研究背景:介绍研究领域的发展情况和重要性。
问题定义:明确研究问题或挑战。
相关工作:简要讨论已有研究的不足之处。
贡献总结:概述论文的创新点和主要贡献。
描述以前怎么做的,随着发展,…有问题,展开描述,为此提出xxx解决xxx,贡献是什么
贡献图给一张放这个区域里面,打开的第一页就能看到这个
引言贡献举例

观察Abs和Intro的贡献描述的区别

- 相关工作(Related Work)
详细回顾与本研究相关的文献,包括已有方法、优缺点等。
说明本研究与现有工作的不同之处。
贡献例子

列出门派1234,我们的跟前4者不一样,这属于贡献的一部分 - 方法(Methodology)
详细描述研究方法,包括数学公式、模型架构、算法步骤等。
如果涉及深度学习,可以介绍神经网络架构、损失函数、优化策略等。
必要时提供伪代码(pseudocode)或流程图。
模块的图和表述
很多东西基于什么东西改一改就不叫原来那个名字,又起了别的名字。
补贡献可以多给个数据集。 - 实验(Experiments)
数据集:介绍实验所用的数据集来源、预处理方法等。
实验设置:说明实验参数、训练细节、对比方法等。提供一个可复现的参数。
结果分析:展示实验结果(表格、图表),进行定量和定性分析。
消融实验(Ablation Study):分析模型关键部分对性能的影响。
方法,对比有这个模块/没这个模块,在别人数据集上是有效的。 - 讨论(Discussion)(可选)
深入分析实验结果,讨论模型的优势、局限性和潜在改进方向。 - 结论(Conclusion)
总结研究成果,强调主要贡献。提出未来可能的研究方向。
做了什么东西,解决什么,实现什么效果,但有什么不足,未来… - 参考文献(References)
列出论文引用的所有文献,格式一般符合特定期刊或会议要求(如 IEEE、ACM、APA)。 - 附录(Appendix)(可选)
包含实验细节、数学推导、额外实验等,不影响论文主体的流畅性。
这种结构适用于 AI 领域的大多数会议论文(如 NeurIPS、ICLR、CVPR)和期刊论文(如 TPAMI、JMLR)。不同会议或期刊可能会有特定格式要求,需参考其官方投稿指南。
贡献放在哪里,Abs+Intro+Related works
- 常见拒稿理由
摘要缺少贡献、架构不清晰模糊,摘要是核心
文章字数少
对某领域说毫无进展之类惹恼评审,不要把话说死、
贡献之间的串联:大贡献+小贡献+SOTA否则贡献不足、
Related Work引用少了没引用到他的被拒,实验太少、Related Work归类与评审的认定不一致,“二者均没有极大利用”这种话得罪审稿人,多补实验
数学公式不直白,伪代码不直白,模型结构图有歧义、
可以不提供代码,多提供对比,但越开源的影响力越大
打假:大模型一般比小模型好,小模型一般比大模型跑得快,有些指标是正相关和大小关系
论文讨论和贡献+局限性分析
可以主动的把还没做的未做好的问题暴露出来以后做或者留给后人做。不要写成疑问句。1个architecture+3个贡献
这里也要把摘要部分拿过来重写,陈述事实,留坑(自己没做好的 可能被diss的部分说未来解决,如加数据集、换赛道、加多模态)


- 局限性这部分要谨慎的措辞

- 厉害的组擅长挖坑和填坑
Conclusion
都是结论式的。还是摘要拿过来改写,摘要写好,结论很容易写。

论文修改和审稿反馈
- 确定idea是几区的工作,通过平时对区位收集和写作方法风格,就可以仿照;看自己有几个贡献,大+小+SOTA不会跑出一二区,三四区只是一个贡献+SOTA
- 为什么会被diss
- 这篇论文到底在干什么 发现别人是怎么解决问题的 怎么描述故事的 要解决现实问题 而不是只是说解决局部特征/全局特征
- 创新太直接的A+B=C,效果也没体现绝对优势,把C跟A做对比,而不是证明B涨点,要说实际解决了什么实际情况,不要花费篇章做无用的推理和详情展开
不要直接说基于xx或者A+B,表明改动的重要性,比如Resnet和VGG,如果直接说Resnet=VGG+残差结构,就没贡献了,为什么Resnet如此出名?众所周知模型越深越掉点,提出解决方法,从模型映射形式y=fx改为y=fx+x,即残差学习,防止模型容易拟合fx=0导致不容易学出fx=x,残差学习非常容易实现而且效果非常好。
为什么人家啥都没改就中了,要学习人家的写作方式。你不强调的东西,不要指望别人自己悟出来。要在一个地方【摘要】集中完整提出你的东西,不要散落到处都是,不要假设读者有耐心看完50%篇幅才理解做了什么。
- 想要看到什么论文
- 迅速看明白提出什么新东西,介绍工作的最终形态,而不是研究过程
- 符合文章组织写作风格,什么地方放什么东西,不要一反常态
- 该有的亮点可以有,但要放的有实际意义,不要花大篇幅验证解释没用的东西
- 我们怎么避免
- 挑研究重点写,不要当记事本,还原研究过程细节,不要故弄玄虚。
- 为了解决问题甲,提出变化很大的方案A,发现不够好,研究后发现是方案A引入了新问题乙,研究如何解决乙后提出改进版方案B(改进很小,加一个trick)解决所有问题,这个trick用在其他方法也有提升。审稿人可能会有疑问:为什么方案A不好使的本质问题是问题乙?方案A也有一定效果,如何证明因为A解决了问题甲?方案B相对于方案A只有很小的差别,贡献太小。B的改进在其他方法上也有提升,那为什么还需要A,没有比别的方法好到哪去。
- 投稿流程
会议有时间显示,aideadline里有汇总,期刊全年都能投但出结果时间长。
会议先返回结果->反驳->最终结果。
期刊->大修小修->中/重投->第二轮
放到正式中稿模版上也会有一段时间




letpab 或 小木虫
面对审稿人 有啥说啥就行了 面对不同的审稿人要有不同的话术 上策还是讨好
非要和可有可无的数据 直接补,承诺未来加
过于离谱的审稿,明明写了没看到,给AC写信说审稿不仔细、没信息、缺乏公平评论
审稿人有分歧,分差巨大,向高分审稿人说话,用高分审稿人的评论回答低分的 - rebuttal:以理服AC,AC具备一票否决权,最终论文中不中由AC根据审稿人反馈来决定;偶尔审稿人水平低不会影响最终论文;分低也可以写信以理服AC,前提是知道自己做的东西在解决什么问题、写工作和实验时候能自问自答对论文进行修改和补全。
学术发表和学术生涯规划
画图基本都是用ppt画的
- 把GPT当工具来使用,不需要训练他
- 另一个新的idea:预计GPT有xx能力,通过你的探索发现它具备这个能力,但是现有的方法模型对于其使用这个能力很有限,提出xx网络,通过这个能展示出很好的效果
- 发表渠道和选择
避免单打独斗,都需要花费大量精力,一作、通讯作者>共一>按顺序,求职中参与一篇有影响力的好工作更好&个人在论文里是否有参与
第一篇尽量找人带流程或找前辈润色,别人视角能暴露很多问题。
CVPR工作坊workshop和竞赛:workshop里拿1 2名可以推送论文
在学校
在企业
社区:paper with code,readpaper,letpub
练习
练习的目的:学习基本的模式模版语感、分析写作套路、贡献点挖掘的技巧。
- GoogleNet v1-v3摘要研读,故事性分析摘要结构
- 文献综述与普通学术论文的区别
- 文献综述一般发表在哪
文献综述越长越好,总结的又细又全最好。 - VIT (Vision Transformer)和NLP的transformer有什么不同
- 研读这篇文献综述

本文涵盖了检测器、检测数据集、评估指标、检测系统的基本构建模块、加速技术、最近最先进的检测方法。
最值得学习的章节:c.目标检测中的技术演进
最值得学习的章节:罗马数字三:speed-up of detection
最值得学习的章节:罗马数字五:conclusion and future directions ,其中最重要的部分是towards open-world detection - 调研自己感兴趣的课题常用的数据集、当前新论文中用的是哪几个、新论文中以模型作为改进的实验如何做的、实验为了证明什么、目前自己想做的基础实验有几个
- 调研相似课题,分析模型架构区别,额外模块的故事异同
- 将相似课题模型拿到自己课题做实验
- 分析迁移后原论文的故事是否能讲在当前方向内
- 分析实验部分、什么时候画图、什么时候画表
- 熟读一篇自己领域最新论文,标注分析动机、贡献、实验
- 模拟上面这个论文,给自己起一个标题编摘要
- 自己领域论文摘要和讨论部分异同收集对比,熟悉写法,以自己的idea风格进行试写
- 以审稿人角度思考自己的论文
- 如何看待aigc时代各种算法任务之间的异同
- 调研自己领域是否存在用别的领域工作将自己领域故事的论文 都是投几区的



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











