



mysql 里面很多的数据结构和算法 实现得很好,操作系统强相关
MySQL里面会有很多可插拔的插件,例如一些公司大佬实现了MySQL的插件
@@ 力扣错题总结:
584. 寻找用户推荐人 :
判断 一个列属性是否为空 不能写作 col=NULL 而是 col is NULL
1581. 进店却未进行过交易的顾客
left join 的理解:
-
左表的每一行都会出现在最终结果中(这是 LEFT JOIN 的定义)。
-
若右表中有多条匹配记录,则左表中的该行将与每一条匹配行组合形成多行输出。
-
若右表中无匹配记录,则左表的该行右边会是 NULL。
举个例子:

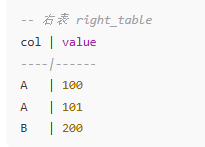
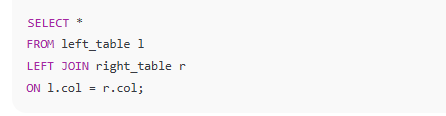
结果会是: 注意右表的A因为有多个项,那么在 Left join的时候,左表的A 则会 广播为 与右表相同的数量,然后进行拼接

更进一步,如果,左表中用于连接的列也存在重复项,那么,legft join 的结果为:


 ==>结果是:
==>结果是: 
197. 上升的温度:
注意再查同一个表格里面某一项之间的内容联系的时候,可以选择表拼接,表拼接的时候也可以先进行处理
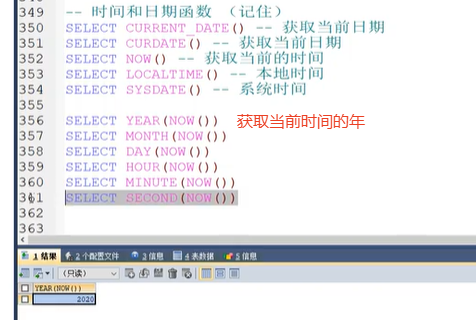
MYSQL中日期加减(前一天、后一天等)以及格式化的函数:
MYSQL中日期加减(前一天、后一天等)以及格式化的函数_date 前一天 mysql-优快云博客
核心就是这个函数:date_sub(table.your_date, interval 1 day)
1661. 每台机器的进程平均运行时间
join 的时候可以按照需求进行筛选拼接,拼接条件也是可以用 and 进行组合的。
JOIN 拼接条件(即 ON 子句)确实可以使用 AND 也可以使用 OR,但:实践中,几乎所有严谨的数据开发都会使用 AND。
但同时注意,join语法就用来拼接就好了,虽然他也可以做一些类似where的操作,但是,最好join就是用来拼接,where就是用来筛选
select s.machine_id, round(AVG(e.timestamp - s.timestamp), 3) as `processing_time` from Activity as s
inner join Activity as e
on s.machine_id = e.machine_id and s.process_id = e.process_id and s.activity_type='start' and e.activity_type='end' -- 此时join的最后两条选择 start 和 end 就属于 抢了where 的活啦
group by s.machine_id
## 更合适的做法:
select s.machine_id, round(AVG(e.timestamp - s.timestamp), 3) as `processing_time` from Activity as s
inner join Activity as e
on s.machine_id = e.machine_id and s.process_id = e.process_id
where s.activity_type='start' and e.activity_type='end'
group by s.machine_id1280. 学生们参加各科测试的次数(建议再做一次)
join 或者说 Inner join 就是笛卡尔积,是可以不加 on 哪个属性的列的 ,通过 join,会生成 学生 × 科目 的笛卡尔积,即每个学生与每个科目的所有可能组合。
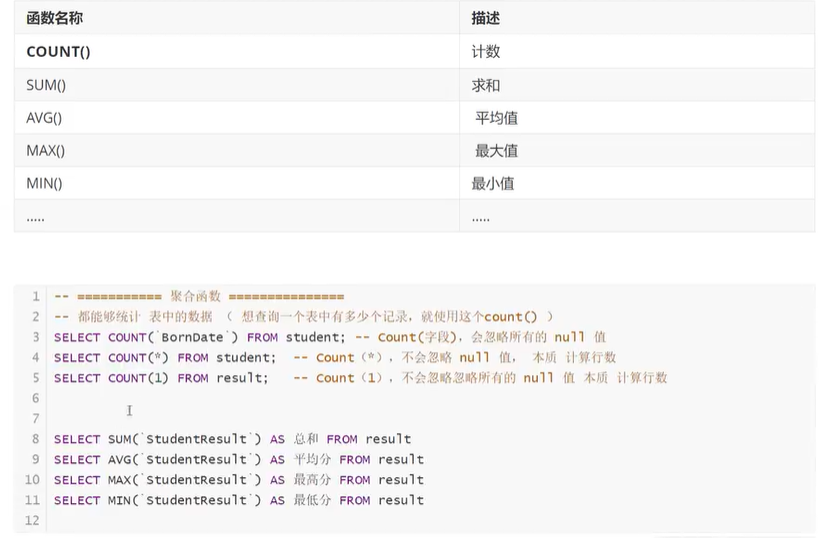
count('某一个特定的列') 的时候,是不会计算该列的NULL值的
但是 count(*) 则是无论是否有NULL,全部算上去
join 的时候 可以后面直接 加一个括号,括号里面直接就是 一个 select XX 语句生成的新表格,也可以 在表格后面 加 as AAA 进行重命名,这样在 最外围用于展示返回值的select 上,就可以 select AAA.column 了
select s.student_id, s.student_name, sub.subject_name, ifnull(new.attended_exams, 0) as attended_exams
from Students as s
cross join Subjects as sub
left join (
select student_id, subject_name, count(*) as attended_exams from Examinations as e
group by student_id, subject_name
) as new
on new.student_id = s.student_id and sub.subject_name = new.subject_name
order by s.student_id, sub.subject_name一、 最基本的命令:







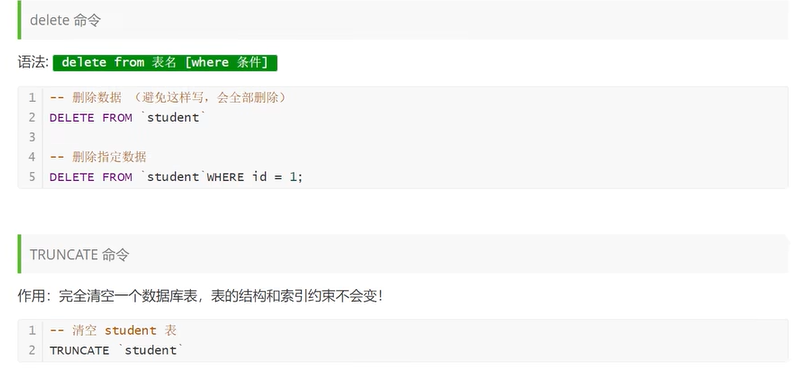
修改属性的时候注意 修改的话属性要全修改,不能就修改部分属性,会报错,只能按顺序指定全部的修改后的属性
外键约束:
1. 建立表的时候直接建立外键约束:

2. 修改表的时候加上外键约束:

上述的这种外键是 物理外键,不建议使用,因为删一个被引用外键的表,删不掉,除非把引用他的表先删掉

即使是插入自增的项,也可以指定数值,例如下图就直接指定了id是7,也是可以插入进去的
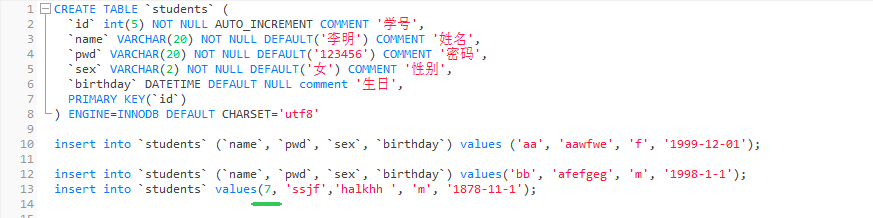 修改条目内容:
修改条目内容:


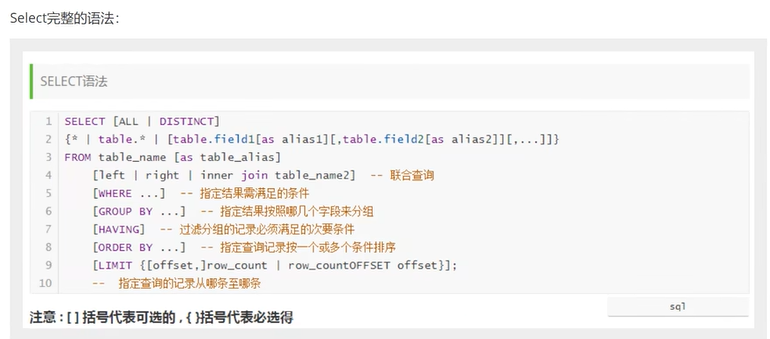
sql的查询:
sql查询的完整语法:

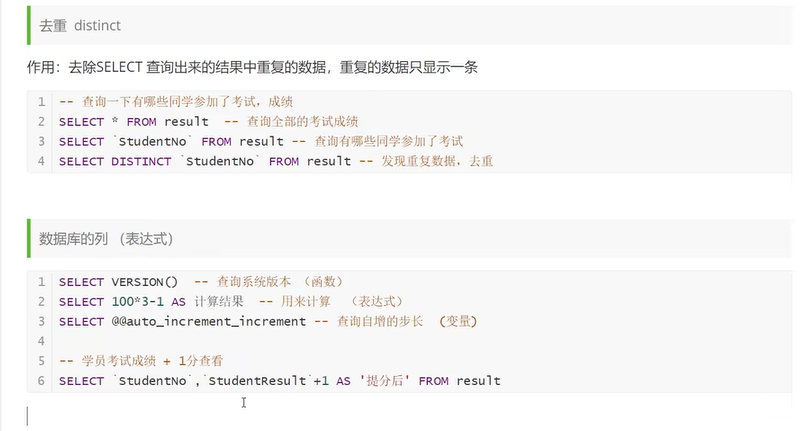
模糊查询:


join : 多表连接:
 就算是需要多表查询,也得两张表查询,然后拿查询结果和另一个需要的表再次连接 ,
就算是需要多表查询,也得两张表查询,然后拿查询结果和另一个需要的表再次连接 ,
 inner join 要求连接的两张表 得有相同的值才能连接在一起,返回的是左右两表有共同值的那些行
inner join 要求连接的两张表 得有相同的值才能连接在一起,返回的是左右两表有共同值的那些行
left join 会以左表为主,右表与左表尽力匹配,匹配不了也没办法,表的每一行依旧以左表为主,右表对应内容没有就Null 空着
使用区别:使用join 和 使用where 可能达成相同的结果,但是更建议使用join,原因如下:
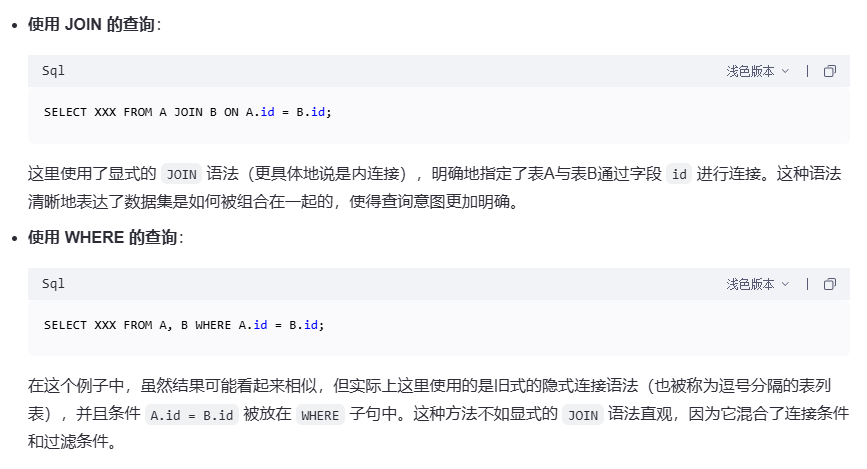

排序:
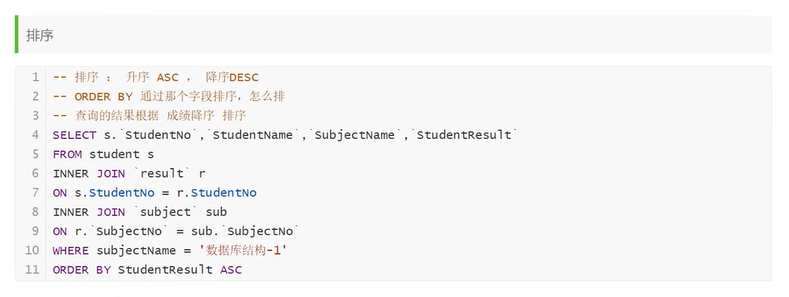

子查询一定要注意 子查询要写到 括号里 ,一定要把结果括起来

子查询还可以变得更加得嵌套,,,查询过程 由里及外
BUT,注意:select 中包含的项,必须要术语 from 后引入的表 或被 join 进来的表中

无论是子查询还是一顿连表,你都得首先明确:到底会用到哪些表
例如:现在要做的:查询 C语言 课程中,前5名同学的成绩信息,包括(学号,姓名,分数)
那么,根据 要查询的成绩信息的内容,判断他们的来源于哪张表格:学号、姓名 来源于 student 表格,分数来源于 result 表格,这时还需要注意,我们的查询条件中,C语言 这个项的内容 来源于 subject 这个表,因此,想查询该条内容,需要涉及 3个表格
【涉及表格有哪些 来源于 查询内容 + 查询条件】


分组&过滤
当分组后 再想过滤,那就得用 having 了

事务特性:
ACID :原子性,一致性,隔离性,持久性

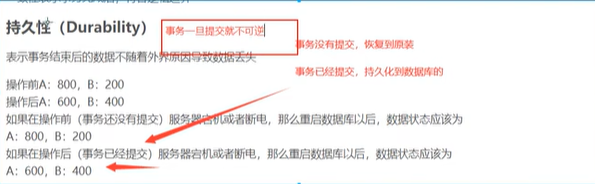
 事务的提交与回滚:
事务的提交与回滚:

一个创建事务、展示回滚的尝试:
 这个就要一个个执行,不然会出现问题报错:
这个就要一个个执行,不然会出现问题报错:
在一个事务中,SQL语句是按照它们被编写的顺序依次执行的。这意味着第一条语句完成后,第二条语句才会开始执行,以此类推,直到事务中的所有语句都被执行或者遇到错误导致事务回滚。
将SQL打包为一组事务的语法非常简单:



















 8172
8172

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









