



【最终版,之后就只在这上面增加修改了】
1. 深度学习模型是一个端到端的模型
深度学习模型是一个端到端的模型,输入的内容是原始的特征:图片的像素,语音的波形等。深度学习模型包含了对于特征的提取与选择,然后将提取选择后的特征作为输入,进入到处理模型中
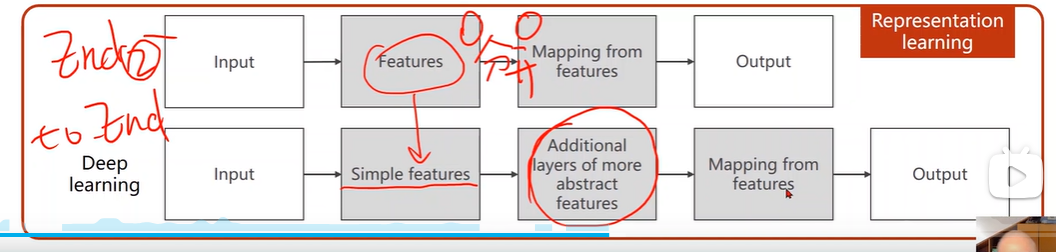 2. 反向传播:
2. 反向传播:
注意:有两条路径可以到达e,换句话说,e 有两个方式共同计算获得,那么,求e的导数,就通过对 c 对 d 两种方式求得
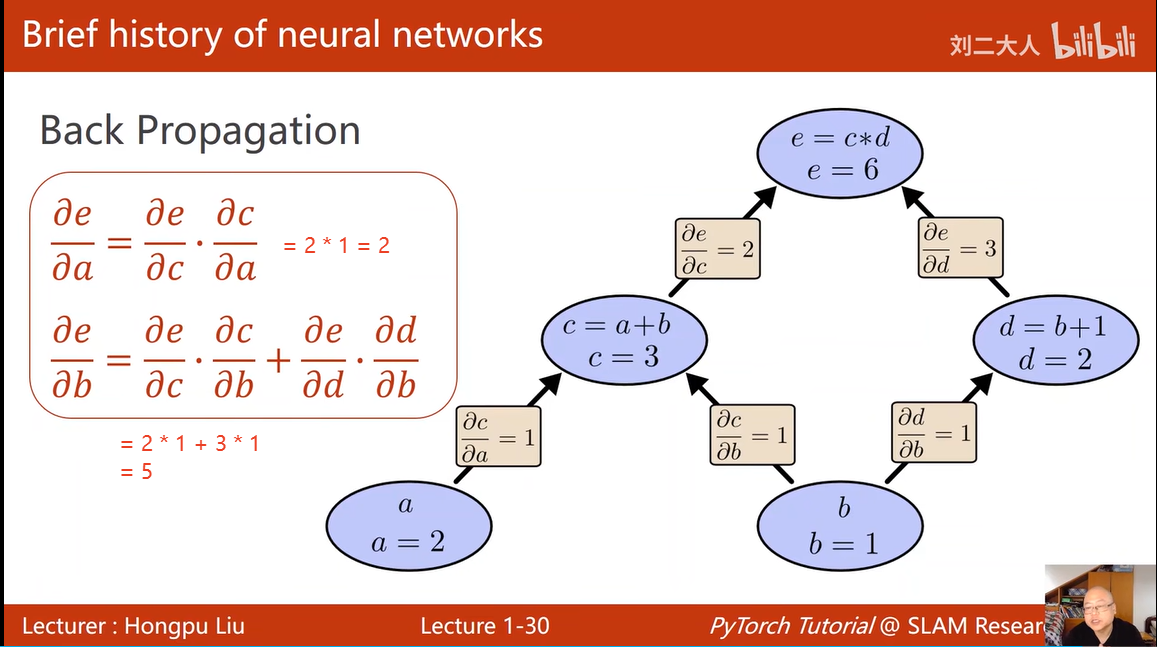
3. 什么是动态图,动态在哪里?
在训练过程中,可以:一边做运算,一边计算图构建出来,等计算结束,计算图就可以释放了,
所以每一次都可以构造出不同的图,
4. 损失函数 和 代价函数
损失函数式针对一个样本的,代价函数是针对全部训练样本的

5. fullbatch minibatch SGD
由于full batch 可以使用矩阵计算 实现样本之间的并行,因此,计算效率高,但是计算准确率较低,因为可能陷在鞍点无法移动
而 随机梯度 只采用一个样本进行训练计算,无法并行,效率低,但是由于引入了随机性,因此可以准确率增加(因为一定程度上避免了鞍点)
注意:由于深度学习中的实践一般都是minibatch,因此,现在深度学习中的代码中,会把 minibatch 简写为 batch
6. 正向传播 & 反向传播
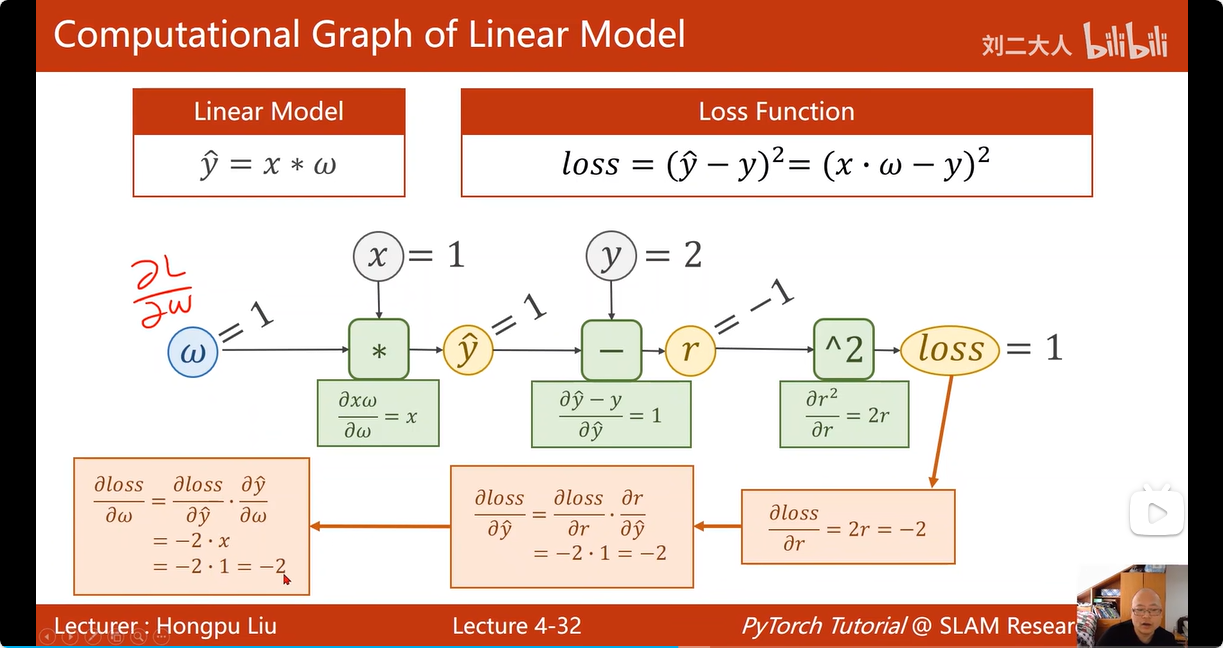 计算反向传播过程时,若当前计算操作的偏导数如果有变量,那么,将当前该变量的数值带入既可
计算反向传播过程时,若当前计算操作的偏导数如果有变量,那么,将当前该变量的数值带入既可
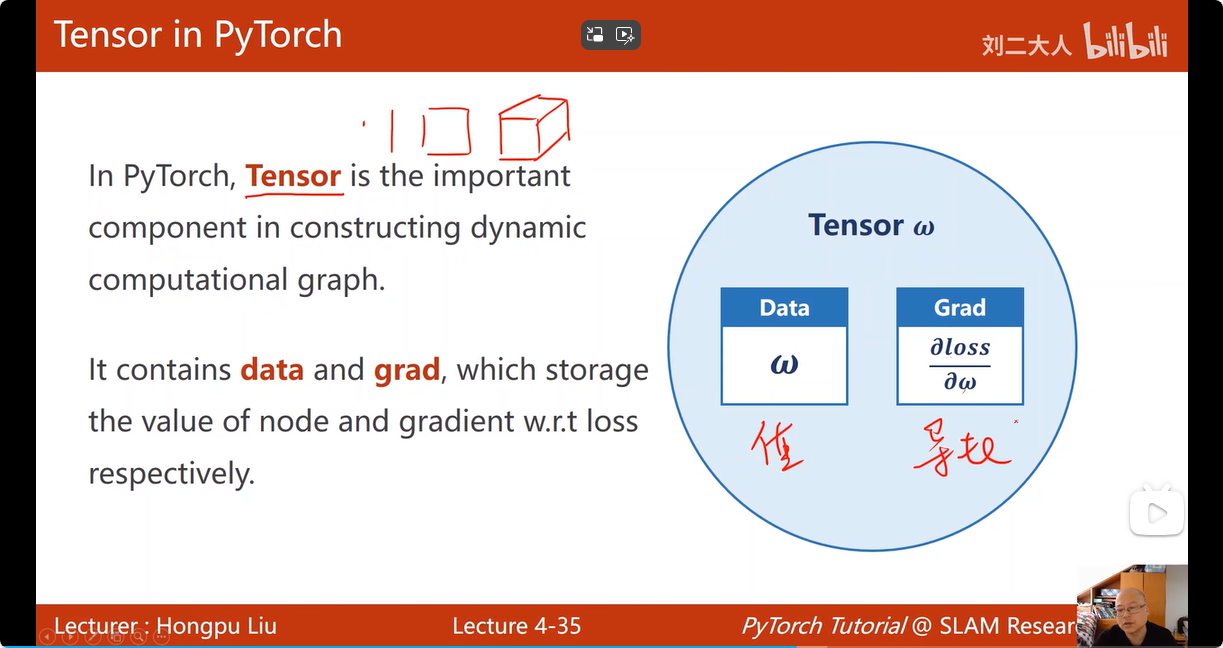
7. 反向传播在pytorch中的实现依靠: tensor类
tensor 类中有两个成员:一个用于存放该变量的数值:data,另一个用于存放Loss对于该变量关于损失函数的梯度:grad
默认的tensor被我们创建后,是不需要计算梯度的,如果这个tensor是一个需要被我们反向传递更新的变量,那么就要 代码指定 :w.requires_grad = True
8. 关于tensor变量 requires_grad 属性的 “传递”与 梯度更新
由于W是一个需要被求出梯度的变量,因此,通过W计算得来的y_pred也被pytorch认为requires_grad=True,而不用手动设置了,同样的,loss返回值也同样保持了requires_grad=True属性
下图这2段函数 是在构造计算图,而不是在执行计算
tensor 类型的数据可以调用 backward() 这个函数,如下图所示,Loss这个tensor调用 .backward() 成员函数,会自动得把计算图上获得loss的这条计算链路上的所有requires_grad=True的tensor 的梯度都求出来。然后将各个tensor求出的梯度存放到对应的tensor 的grad 成员中。(backward 的作用是:计算梯度并存放梯度)
然后!注意,在 loss.backward() 执行完后,计算图就被释放了!然后在下一次循环的时候,loss再根据程序,就是代码中对应的 l = loss(x, y) 生成一个新的计算图。这样实现的原因是,每次的计算图可能都不一样,每次重新定义计算图更灵活。
注意,由于tensor中的成员:grad也是一个tensor,为了避免出现tensor中的grad成员在执行计算的时候,以tensor类型进行计算,出现计算符重载,进行tensor类型的计算,生成计算图。因此调用tensor的成员data,获得tensor中的数值内容,对于grad来说,就是梯度值大小。【在tensor数据更新时,一定要注意!】
.item() 也有这个作用,将一个将包含单一数值的张量转换为 Python 的基本数据类型(如 float 或 int)

同时注意:给计算更新一次的参数W中的grad成员数值清零是必须的,不然,例如图中所示,第一次更新计算得到 L1,根据L1计算获得w的梯度,不加以清零,第二次更新计算得到L2,那么,根据L2计算获得的 w的梯度 就会与之前计算出的 相加,将
作为 w 的新梯度 ,这显然不符合我们的期待,因此需要及时对上一次计算出的梯度结果清零,避免影响下一次的w参数更新
总的来说,流程为:先计算损失loss,然后 根据loss调用 .backward 计算梯度,根据梯度计算模型各个参数的更新
9. 利用pytorch工具实现模型更新:



step() 会根据所有 待更新变量中 保存的梯度 以及 预先设置好的学习率,自动进行更新
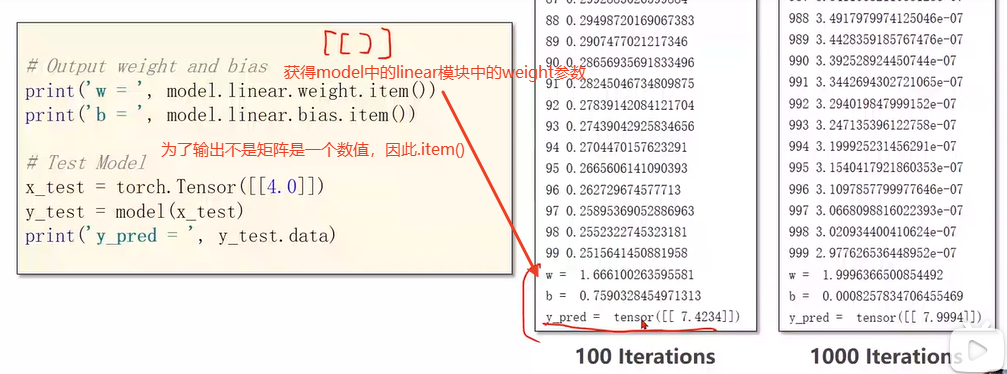 10. 线性模型在pytorch中的完整流程:
10. 线性模型在pytorch中的完整流程:

11. 分类问题的损失函数:
由于分类问题不再是判断预测值和真实值之间的差距,而是判断样本预测值的分布和真实值的分布是否一致
判断分布采用的判断方式有多种,如KL散度、交叉熵等
对于logistic回归的损失函数就是 计算 预测概率为1和预测概率为0的样本预测值 和 真实值分布的交叉熵
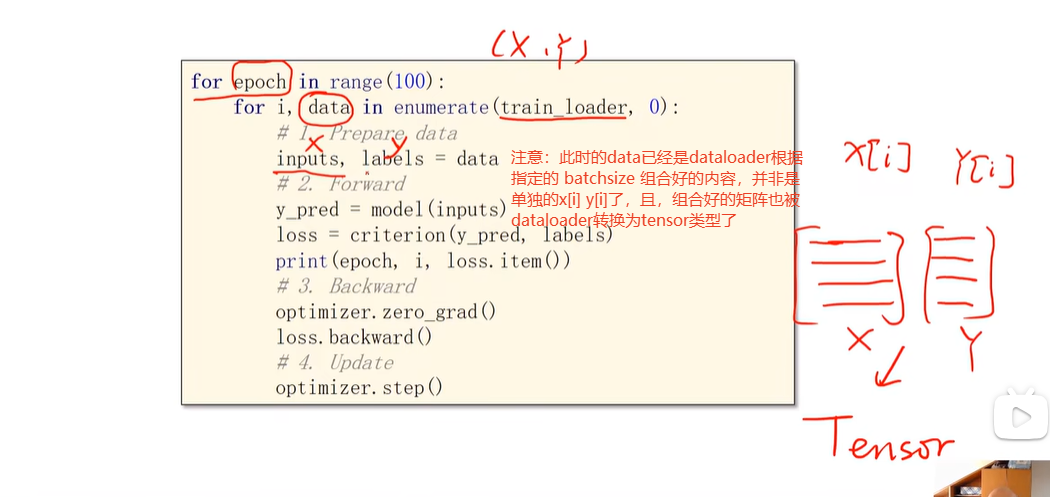
12. epoch batchsize iteration 概念:
正因为把样本组织为多个minibatch,因此当前的循环变成了两层的嵌套循环,最外层表示训练的轮次(对整个iteration,对整个训练样本),内层对每一个minibatch中的全部样本进行迭代

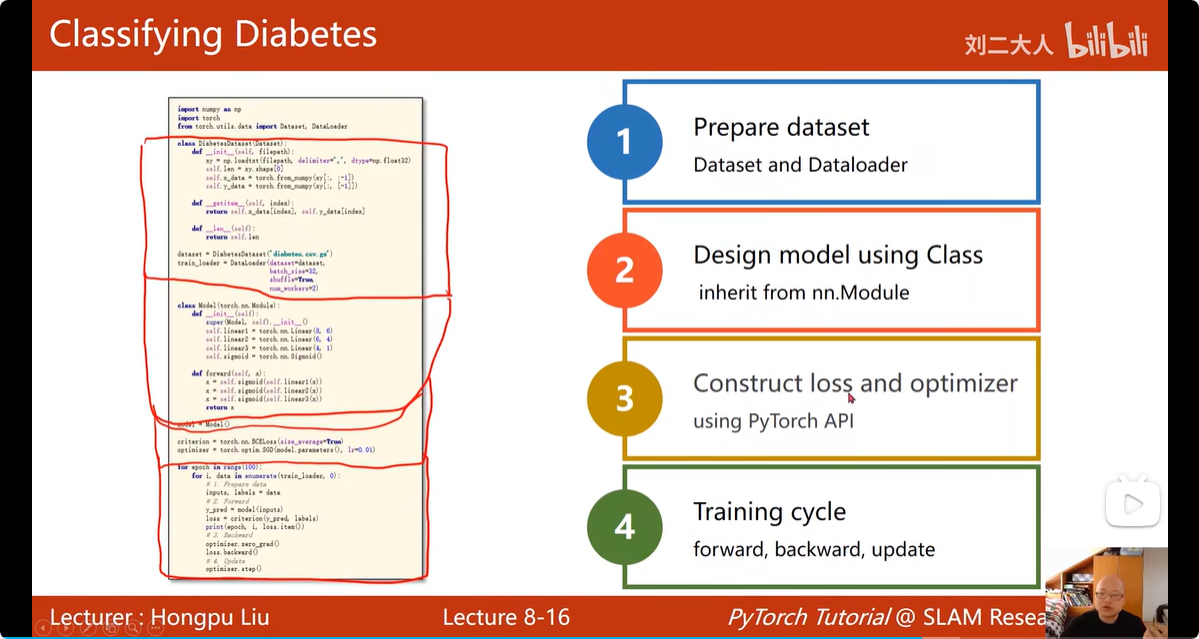
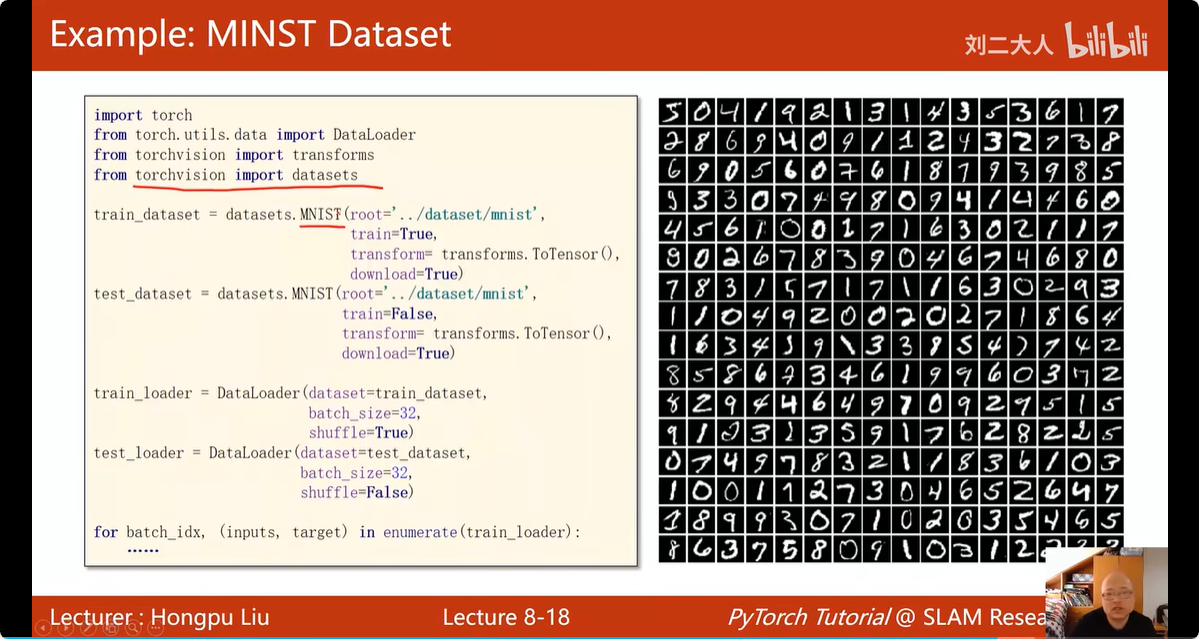
13. Dataset 和 Dataloader
要先将数据组织为dataset 类型,然后才能将dataset作为参数,使用Pytorch实现的dataloader
Dataset 抽象类,只能继承,不能实例化
Dataloader 可以实例化
其中 num_workers=2 含义是CPU中采用几个线程同时进行读数据操作
13.1 抽象类Dataset 中要实现多个抽象函数,重点说一下__getitem__() ,对于比较小的数据集,可以选择将数据全加载到内存中,依次编号,但是对于较大的数据集,比如很多张的图片这种数据集,__getitem__() 就得返回数据的文件名,调用到这个文件的时候,返回文件名,根据文件名字到对应的文件夹去找(从磁盘中现读入)

在使用 PyTorch 构造自定义数据集(继承 torch.utils.data.Dataset)时,__getitem__() 方法 返回 一个样本的数据对,也就是某一条 data_x 和对应的 data_y。
在 __getitem__() 中,self.data_x 和 self.data_y 只是约定俗成的名字,没有任何硬性要求。只是__getitem__()确实需要返回两个变量,分别是一条样本的 X 值和 y 值
Dataloader 会自动帮你 组合多个样本形成 batch



 总的来说:
总的来说:
对于现成的
我一直有些混乱的 时序预测 一段时间步 如何生成 数据集:
先上代码:
def generate_sales_data(n=200, seed=42):
np.random.seed(seed)
time = np.arange(n)
sales = 100 + 0.5 * time + 20 * np.sin(2 * np.pi * time / 30) + np.random.normal(0, 5, size=n)
return sales.reshape(-1, 1)
# ----- 2. 数据集类 -----
class SalesDataset(Dataset):
def __init__(self, series, input_len=60, pred_len=1):
self.input_len = input_len
self.pred_len = pred_len
self.series = torch.tensor(series, dtype=torch.float32)
def __len__(self):
return len(self.series) - self.input_len - self.pred_len + 1
def __getitem__(self, idx):
src = self.series[idx : idx + self.input_len]
tgt = self.series[idx + self.input_len : idx + self.input_len + self.pred_len]
return src, tgt
PyTorch 的 DataLoader(..., shuffle=True) 会打乱索引顺序,从数据集中 随机采样多个样本组成一个 batch。

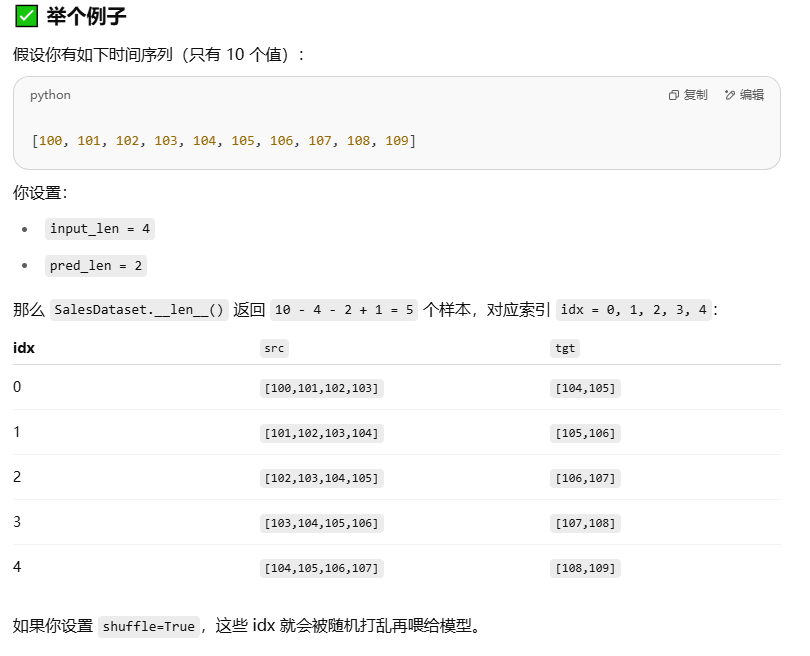 就比如,shuffle=True,于是获得了随机的idx 序列[2, 4, 1, 0, 3]
就比如,shuffle=True,于是获得了随机的idx 序列[2, 4, 1, 0, 3]
那么,假设batchsize=2, 数据就会被分为:
# batch 0:
2 [102,103,104,105] [106,107]
4 [104,105,106,107] [108,109]
# batch 1:
1 [101,102,103,104] [105,106]
0 [100,101,102,103] [104,105]
# batch 2:
3 [103,104,105,106] [107,108]

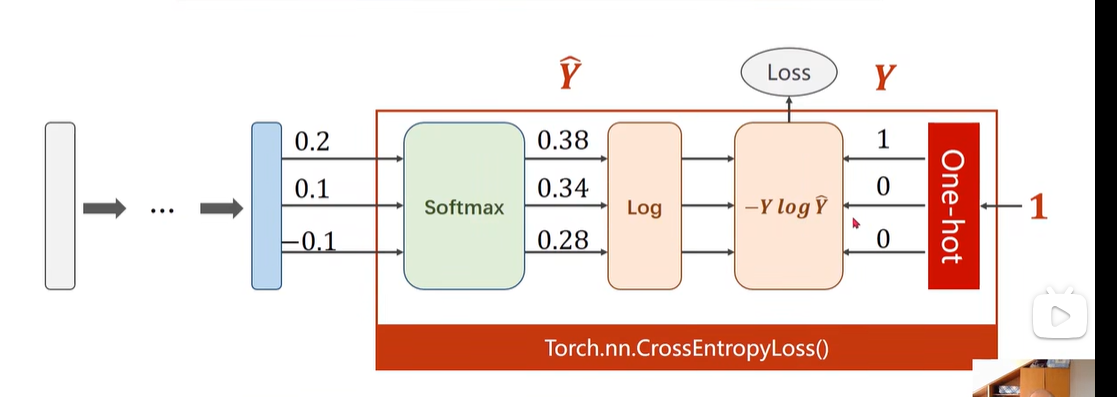
14. 多分类问题:
最后要将输出传到 CossEntropyLoss里:先进入softmax,然后取 log 进行计算,因此,我们在多分类问题中,最后一层就不要加激活函数了,在 CossEntropyLoss 里 就已经自己带着了
将train和test分开组织为一个函数:




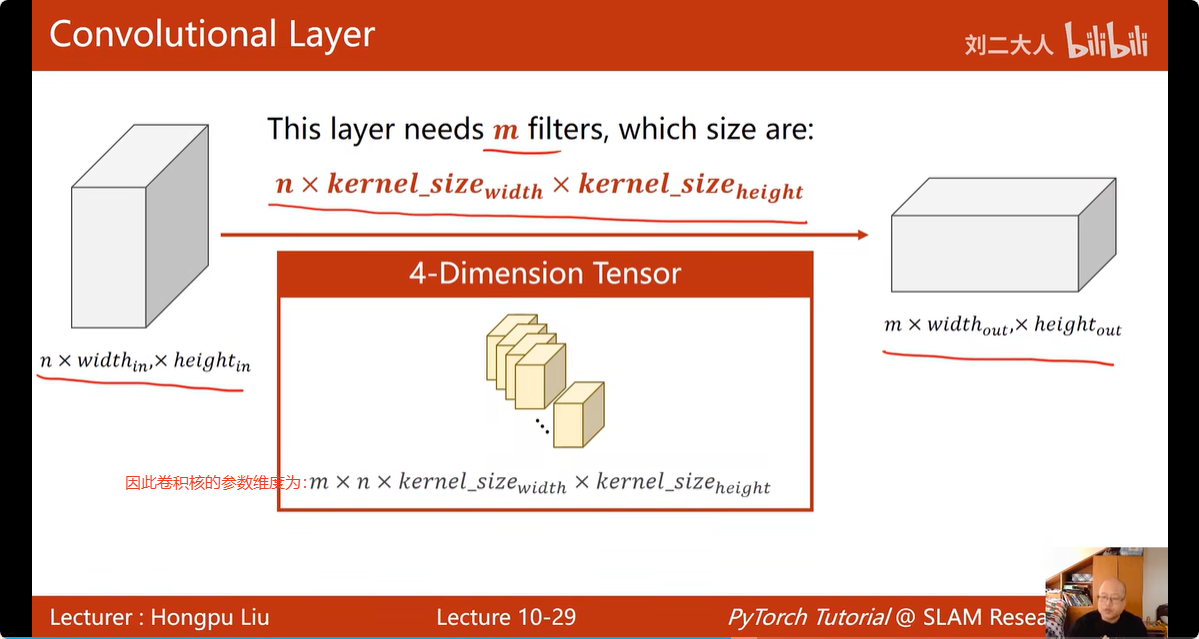
15. 卷积运算:
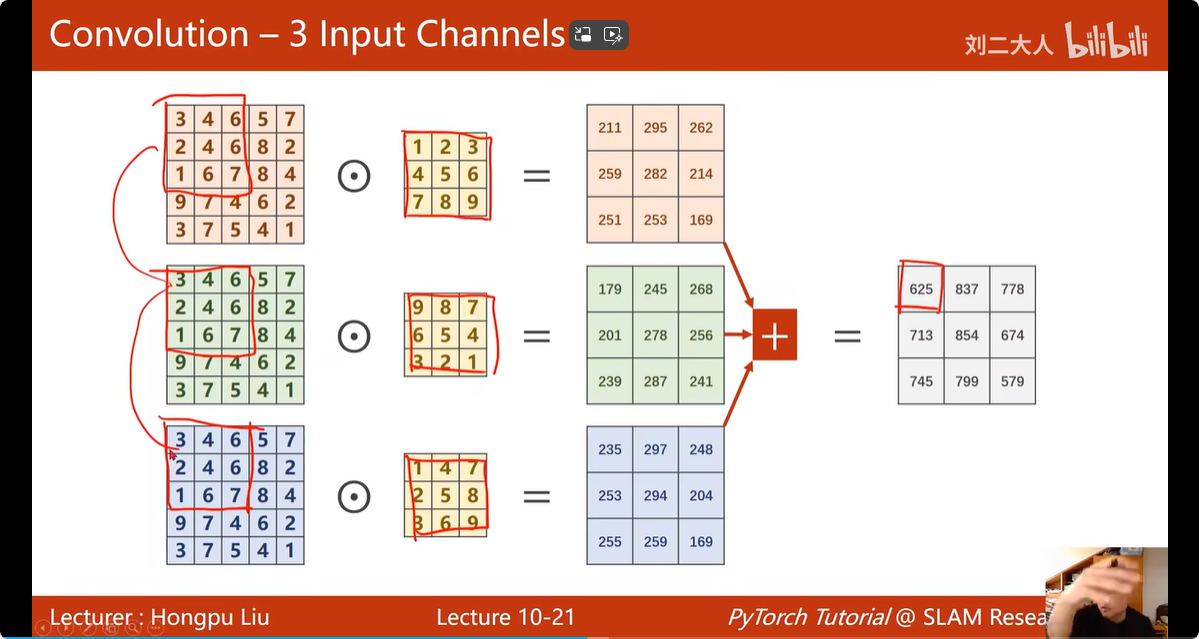
对于输入,输入的通道数 = 卷积核的通道数,例如,输入图片为3通道,RGB;卷积核也有3个通道,每个颜色的 通道配一个卷积核
矩阵经过一个卷积核的处理,得到了一层的数据(一个通道)
矩阵经过多个卷积核的处理,就可以得到多层的数据(多个通道)
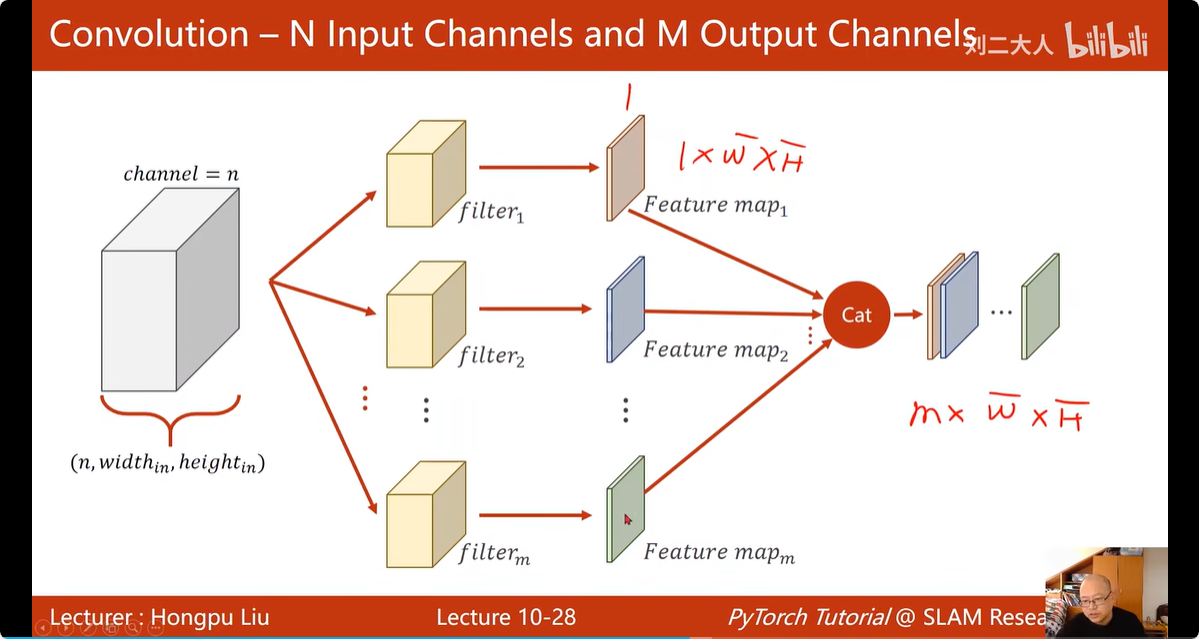
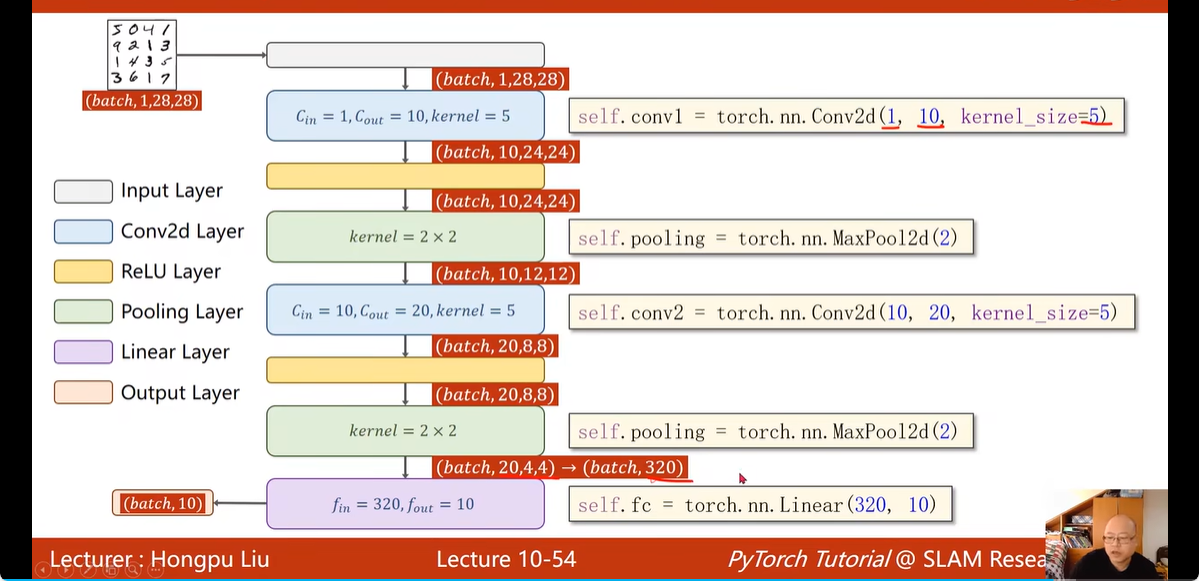
16. 卷积分类器:

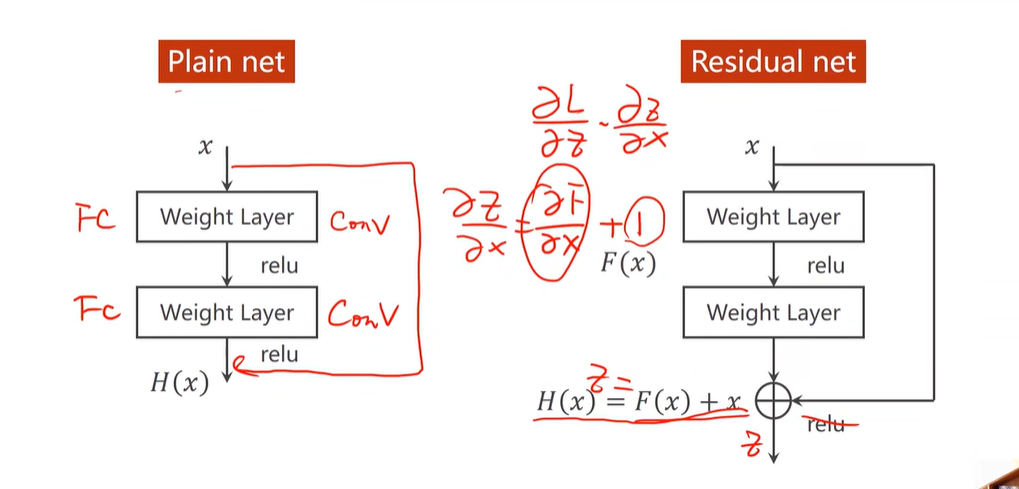
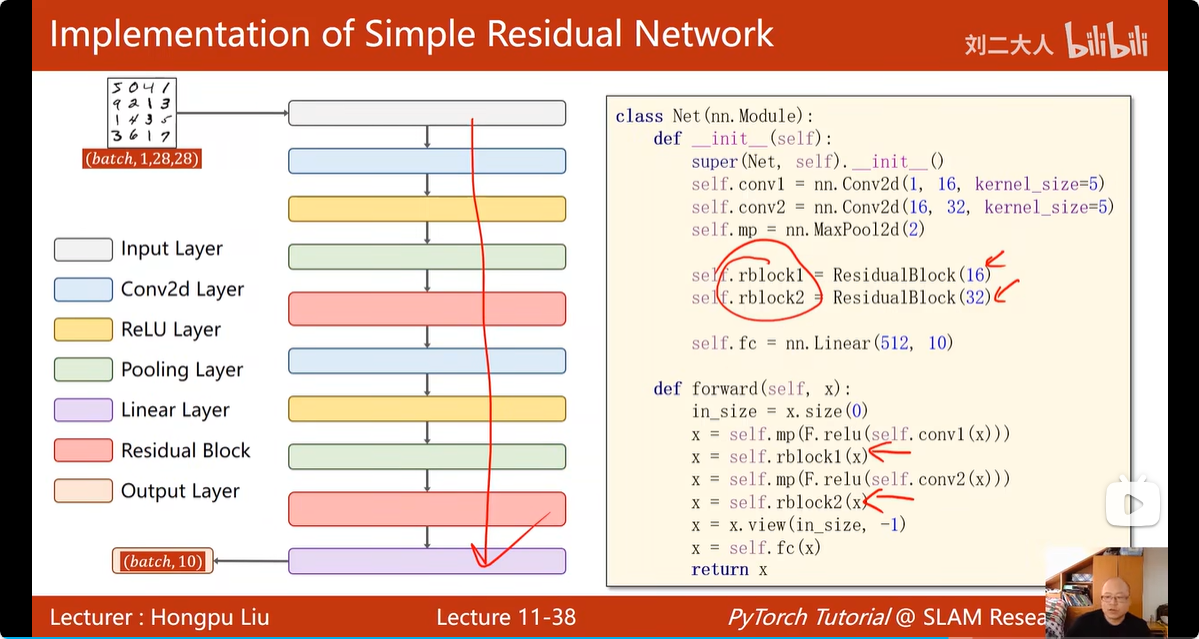
17. 跳连接:
可以看出梯度相较于之前多了一个1,所以,梯度不再是一堆小于1的数值相乘,而是大于1的数值相乘,不再会梯度消失了

17. RNN:
一方面是为了捕捉线性顺序,之前的情形对之后的情形有影响,还可以减少参数:下图的这些RNN cell 都是可以参数共享的,都是一样的参数
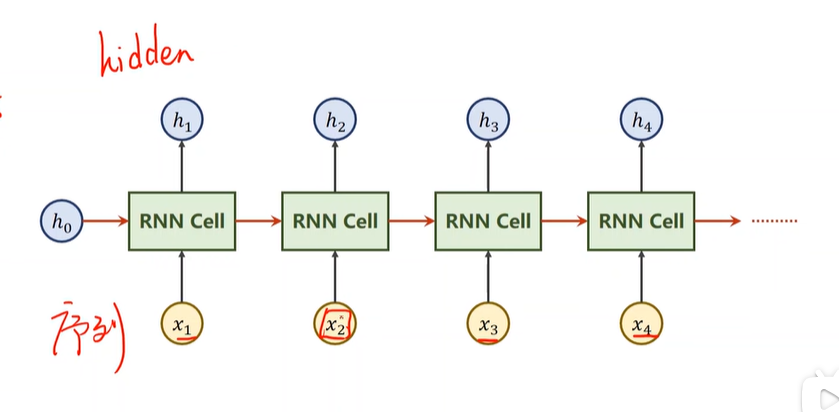
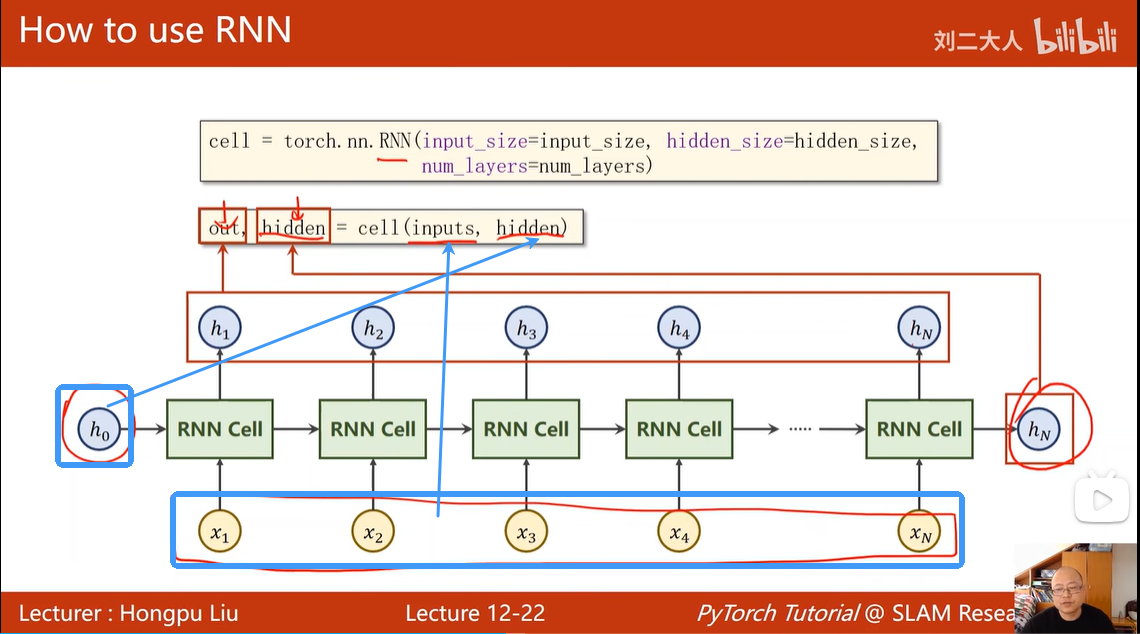
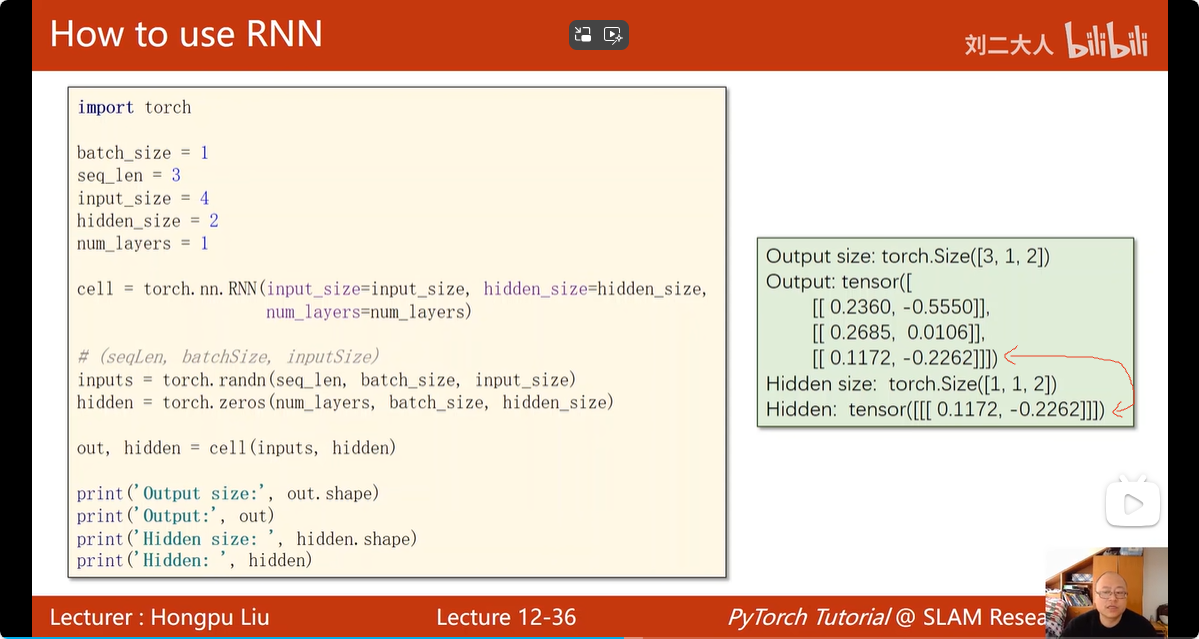
torch.nn.RNN 的输入输出:
BRNN
当RNN双向的时候,需要输入的语句是全部获得才能参与训练预测;
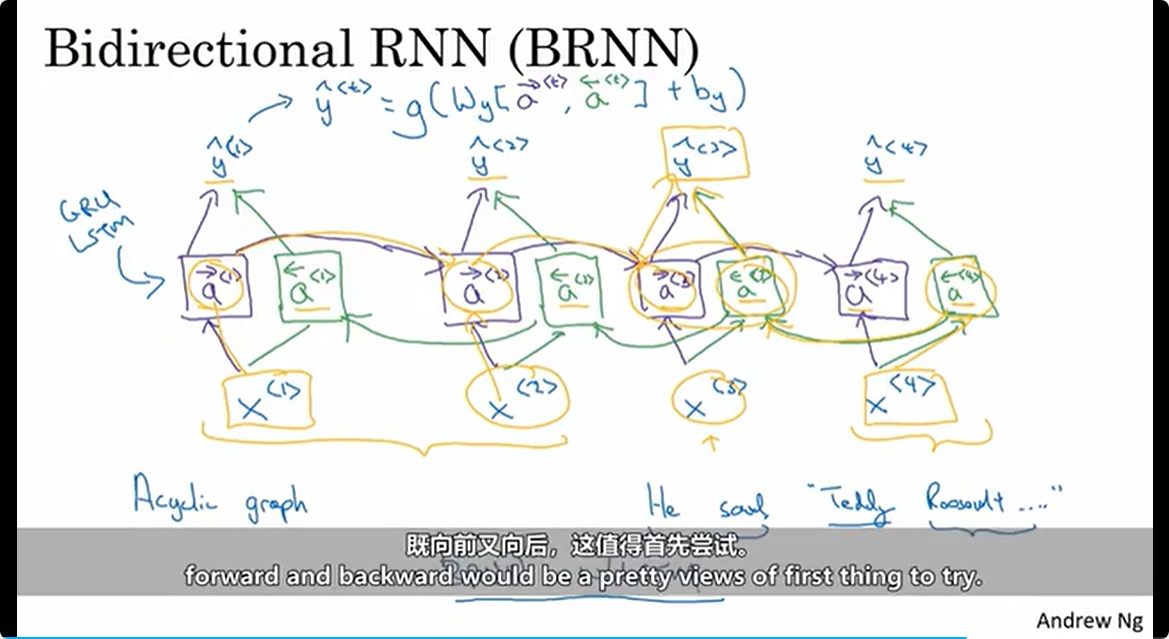 BRNN的返回参数:
BRNN的返回参数: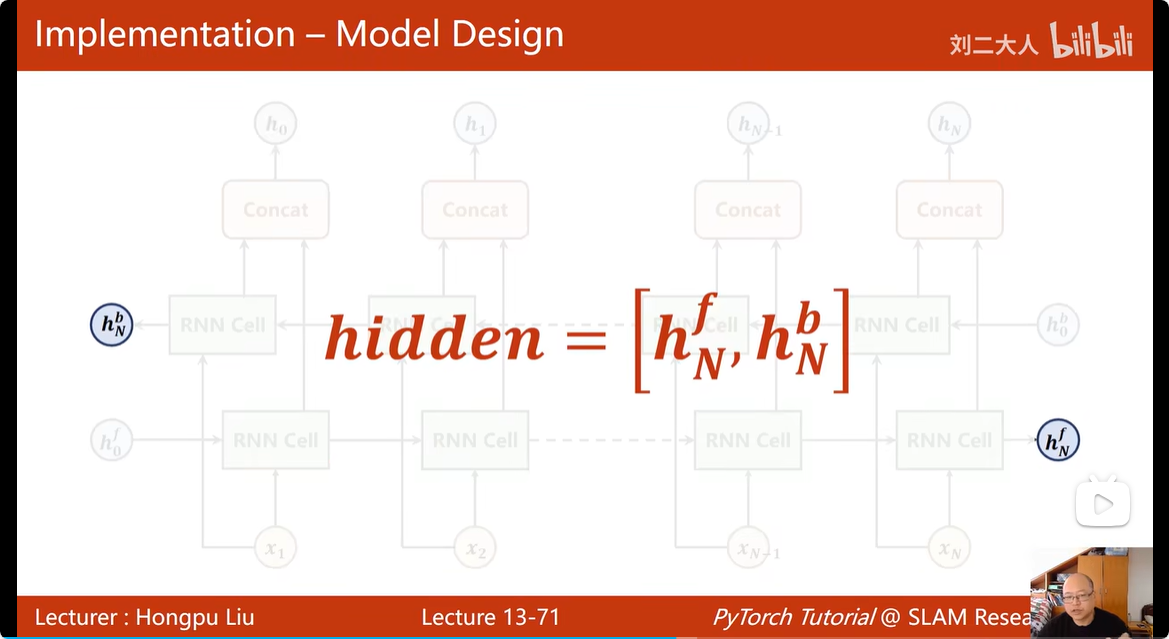
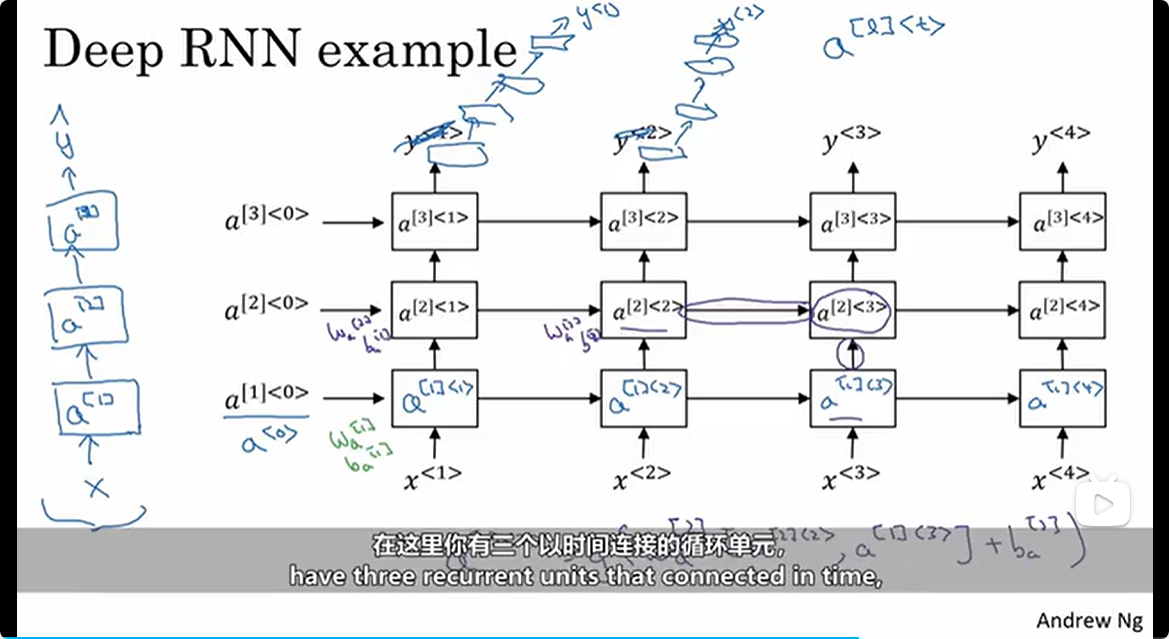
深度RNN 和其他模型的组合
对于3层的深度RNN,其每一个时间步的输出o,接着被传入到新的模型当中,例如3层 全连接层,但是 深度RNN输出的 o 后接的全连接层 并不会 在时间步 之间互相连接,如下图所示


















 8万+
8万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









