




 本文介绍了一种使用Python爬取B站Python相关视频的方法,包括如何定位API接口、构造URL参数实现多页爬取,并提供了具体代码实现,涵盖视频标题、作者、播放量等信息的抓取。
本文介绍了一种使用Python爬取B站Python相关视频的方法,包括如何定位API接口、构造URL参数实现多页爬取,并提供了具体代码实现,涵盖视频标题、作者、播放量等信息的抓取。
Flag:一天一爬虫。
这篇是转的:https://blog.youkuaiyun.com/sixkery/article/details/81946308
亲测有效,
对转载网站的分析做进一步分析补充:
分析页面:
如何获取api?
这次我直接打开开发者工具,切换到Network下查找api,要点击Python旁边的搜索按钮,不然Network一片空白,
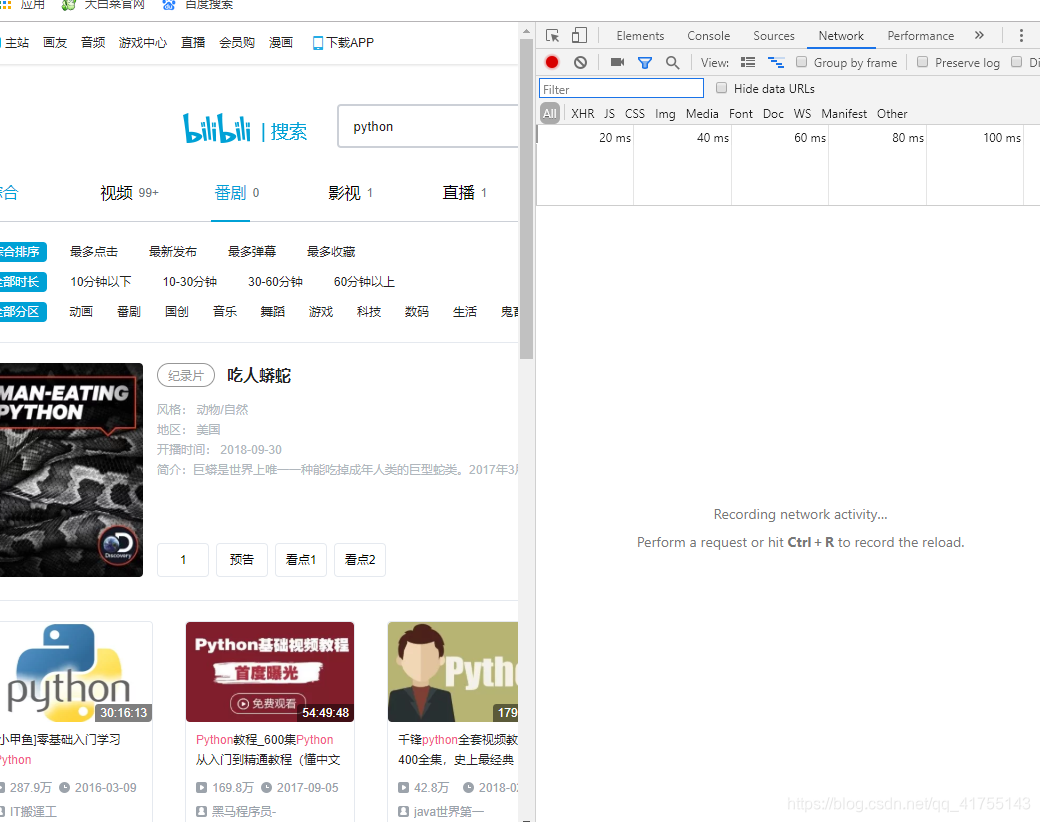
点击搜索之后:
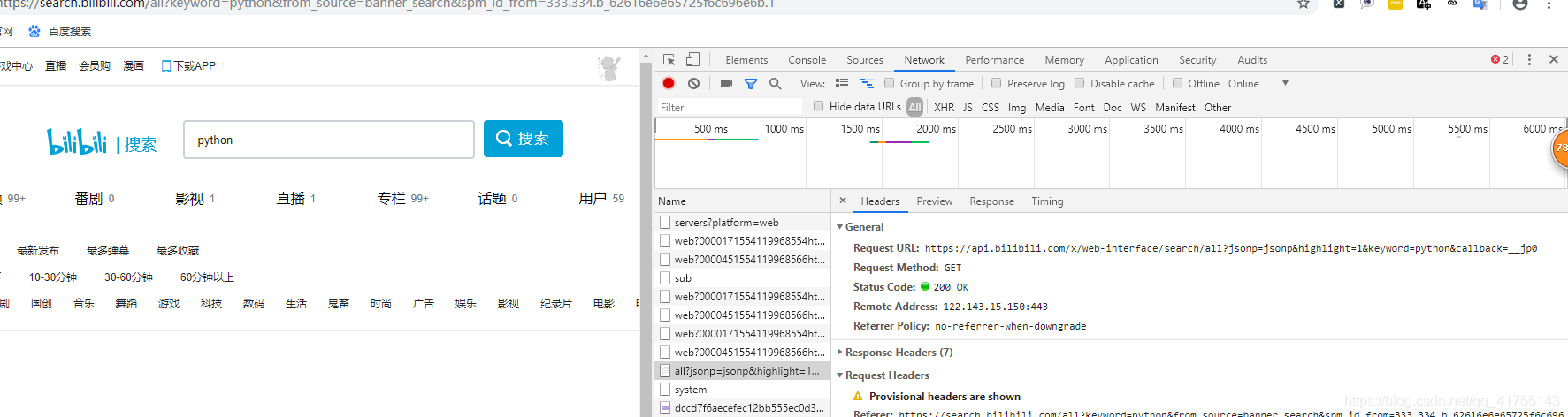
会在其中找到,一个以api开头的网址,但是我们不能用此url作为我们爬取的对象,因为此url,没有包含page={},无法多页爬取,
此url只搜集这一页的视频信息。
此url
https://api.bilibili.com/x/web-interface/search/all?jsonp=jsonp&highlight=1&keyword=python&callback=__jp0然后,
依次点击尝试,
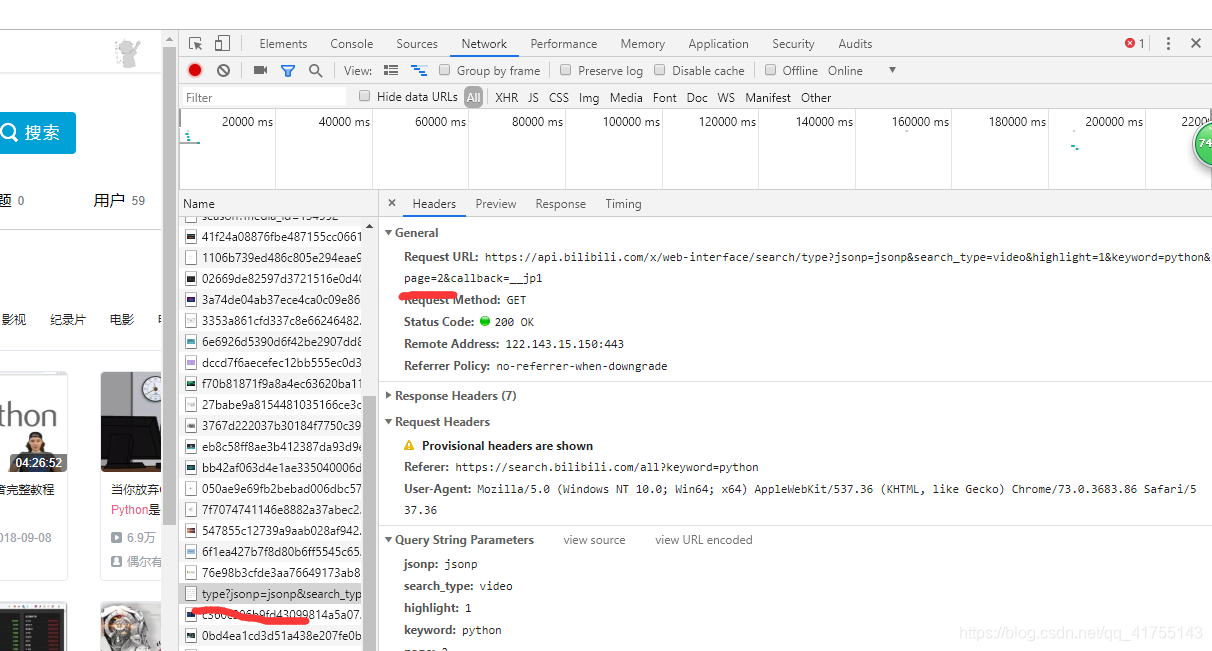
找到page,意味着可以多页爬取了,然后就是构造url。
代码:
import requests
import json, re, time
from requests.exceptions import RequestException
class Spider():
def get_page(self, page):
try:
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64)'
' AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36',
}
url = 'https://api.bilibili.com/x/web-interface/search/type?jsonp=jsonp&&search_type=video&highlight=1&keyword=python&page={}'.format(
page)
r = requests.get(url, headers)
if r.status_code == 200:
return r.text
else:
print(r.status_code)
except RequestException:
print('请求失败')
return None
def parse_page(self, html):
# 转换成JSON对象,好操作
data = json.loads(html)
results = data.get('data').get('result')
for result in results:
# 获取图片地址
image_url = result['pic']
# 获取视频地址
video_url = result['arcurl']
# 获取作者
video_author = result['author']
# 获取视频标题,中间有额外的字符,用re替换一下
video_title = result['title']
video_title = re.sub('<em class="keyword">[Pp]ython</em>', 'Python', video_title)
# 获取播放量
video_play = result['play']
# 获取上传时间,这里将时间戳转换成标准格式
video_date = result['pubdate']
timestr = time.localtime(video_date)
video_date = time.strftime('%Y-%m-%d %H-%M-%S', timestr)
print(image_url, video_url, video_title, video_play, video_date)
def run(self):#爬取前三页
for i in range(1, 3):
html = self.get_page(i)
self.parse_page(html)
def main():
spider = Spider()
spider.run()
if __name__ == '__main__':
main()爬取结果,
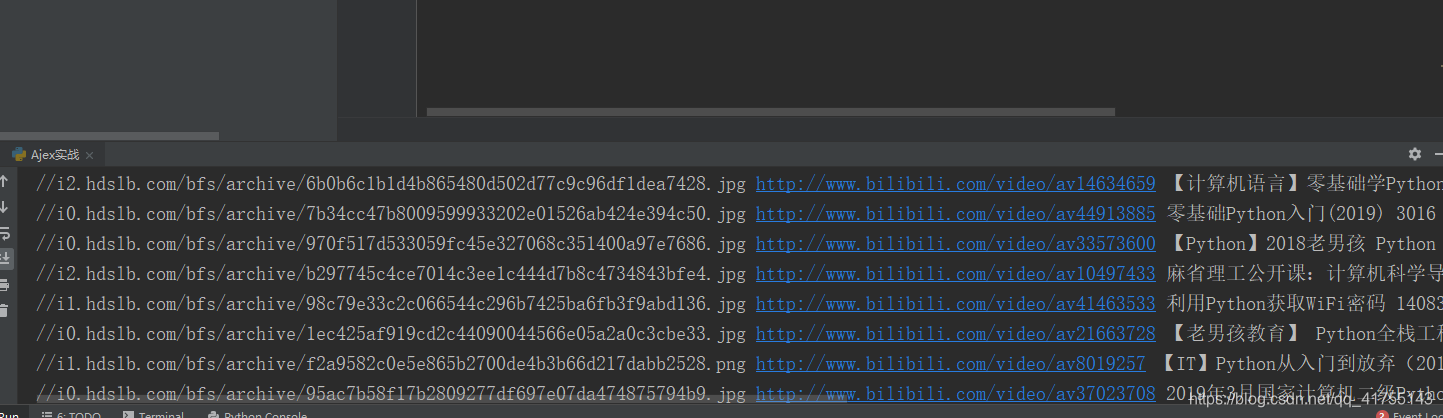
本来想爬一下那个all的api,奈何能力不够,找代理池,换header都解决不了问题,,
此处先贴上代码,以后解决。
import requests
import json, re, time
from requests.exceptions import RequestException
import random
import urllib as ulb
class Spider():
def get_page(self):
try:
my_headers = [
"Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.95 Safari/537.36",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_9_2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/35.0.1916.153 Safari/537.36",
"Mozilla/5.0 (Windows NT 6.1; WOW64; rv:30.0) Gecko/20100101 Firefox/30.0",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_9_2) AppleWebKit/537.75.14 (KHTML, like Gecko) Version/7.0.3 Safari/537.75.14",
"Mozilla/5.0 (compatible; MSIE 10.0; Windows NT 6.2; Win64; x64; Trident/6.0)",
'Mozilla/5.0 (Windows; U; Windows NT 5.1; it; rv:1.8.1.11) Gecko/20071127 Firefox/2.0.0.11',
'Opera/9.25 (Windows NT 5.1; U; en)',
'Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; .NET CLR 1.1.4322; .NET CLR 2.0.50727)',
'Mozilla/5.0 (compatible; Konqueror/3.5; Linux) KHTML/3.5.5 (like Gecko) (Kubuntu)',
'Mozilla/5.0 (X11; U; Linux i686; en-US; rv:1.8.0.12) Gecko/20070731 Ubuntu/dapper-security Firefox/1.5.0.12',
'Lynx/2.8.5rel.1 libwww-FM/2.14 SSL-MM/1.4.1 GNUTLS/1.2.9',
"Mozilla/5.0 (X11; Linux i686) AppleWebKit/535.7 (KHTML, like Gecko) Ubuntu/11.04 Chromium/16.0.912.77 Chrome/16.0.912.77 Safari/535.7",
"Mozilla/5.0 (X11; Ubuntu; Linux i686; rv:10.0) Gecko/20100101 Firefox/10.0 "
]
headers =random.choice(my_headers)
url = 'https://api.bilibili.com/x/web-interface/search/all?jsonp=jsonp&highlight=1&keyword=python&callback=__jp0'
proxies = {
'https': 'https://114.99.7.122:8752'}
proxy_list = [
'183.95.80.102:8080',
'123.160.31.71:8080',
'115.231.128.79:8080',
'166.111.77.32:80',
'43.240.138.31:8080',
'218.201.98.196:3128'
]
# 随机从IP列表中选择一个IP
proxy = random.choice(proxy_list)
# 基于选择的IP构建连接
urlhandle = ulb.request.ProxyHandler({'http': proxy})
opener = ulb.request.build_opener(urlhandle)
ulb.request.install_opener(opener)
r = requests.get(url, headers,proxies=proxies)
if r.status_code == 200:
return r.text
else:
print(r.status_code)
except RequestException:
print('请求失败')
return None
def parse_page(self, html):
print(html)
# 转换成JSON对象,好操作
# data = json.loads(html)
# print(data)
# results = data.get('data').get('result')
# results=data.get('data').get('result').get('video')
# for result in results:
# author_=result['author']
# print(author_)
# # 获取图片地址
# image_url = result['pic']
# # 获取视频地址
# video_url = result['arcurl']
# # 获取作者
# video_author = result['author']
# # 获取视频标题,中间有额外的字符,用re替换一下
# video_title = result['title']
# video_title = re.sub('<em class="keyword">[Pp]ython</em>', 'Python', video_title)
# # 获取播放量
# video_play = result['play']
# # 获取上传时间,这里将时间戳转换成标准格式
# video_date = result['pubdate']
# timestr = time.localtime(video_date)
# video_date = time.strftime('%Y-%m-%d %H-%M-%S', timestr)
# print(image_url, video_url, video_title, video_play, video_date)
def run(self):#爬取前三页
html = self.get_page()
self.parse_page(html)
# for i in range(1, 3):
# html = self.get_page(i)
# self.parse_page(html)
def main():
spider = Spider()
spider.run()
if __name__ == '__main__':
main()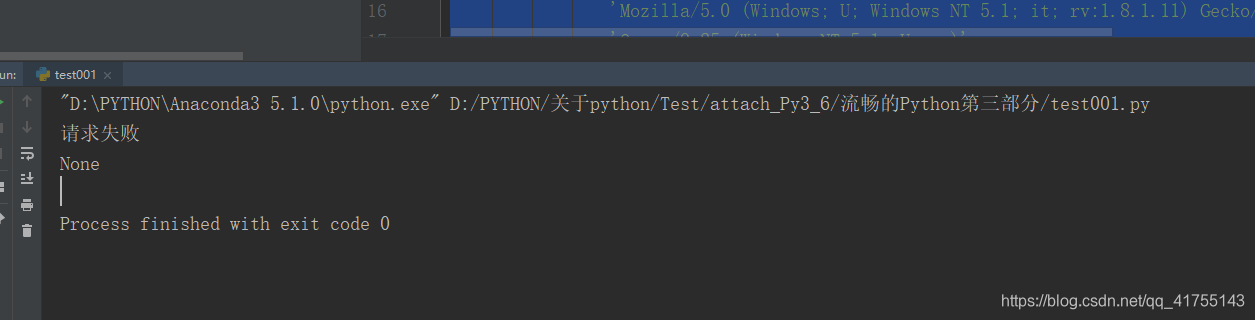

















 5万+
5万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









