




 本文深入解析BatchNormalization(BN)技术,它通过在神经网络中引入标准化和缩放平移层,有效提升训练效率。BN首先对加权和进行标准化处理,然后通过可训练的缩放和平移系数进行还原,以保持信息并降低梯度爆炸或消失的问题。BN不仅稳定了网络训练,还允许损失函数控制各层的还原程度,是现代深度学习模型中的关键组件。
本文深入解析BatchNormalization(BN)技术,它通过在神经网络中引入标准化和缩放平移层,有效提升训练效率。BN首先对加权和进行标准化处理,然后通过可训练的缩放和平移系数进行还原,以保持信息并降低梯度爆炸或消失的问题。BN不仅稳定了网络训练,还允许损失函数控制各层的还原程度,是现代深度学习模型中的关键组件。
1 简介
Batch Normalization 技巧于 2015 年被谷歌提出以来,能够有效提升网络训练效率。众所周知,在神经网络训练前对输入像素进行标准化处理,能够有效降低模型的训练难度。受此启发,既然能够对输入层进行标准化处理,那么隐藏层为什么不可以标准化? 因此,对每层加权和进行标准化,然后再通过缩放平移来“适度还原”。这样,既保证了不过分破坏输入信息,又降低了由于各 batch 之间各位置点像素分布的剧烈变化所带来的学习难度。
2 采用 BN 的神经网络
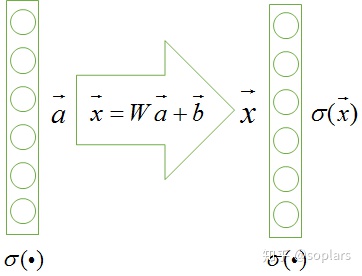
一个经典神经网络的某个隐藏层如图上图所示。上一层的激活输出(本层的输入)为 a → \mathop{a}\limits ^{\rightarrow} a→,经过本层加权和 W ⋅ a → + b → W\cdot\mathop{a}\limits ^{\rightarrow}+\mathop{b}\limits ^{\rightarrow} W⋅a→+b→ 处理后,获得加权和 x → \mathop{x}\limits ^{\rightarrow} x→,然后经本层激活后得到输出 ρ ( x → ) \rho({\mathop{x}\limits ^{\rightarrow}}) ρ(x→)。

采用 BN 的神经网络结构如上图所示,主要步骤如下:
- 求出本层的加权和 x → \mathop{x}\limits ^{\rightarrow} x→;
- 进行标准化求出 x → ^ \hat{\mathop{x}\limits ^{\rightarrow}} x→^;
- 进行缩放和平移求出 y → \mathop{y}\limits ^{\rightarrow} y→,然后对其进行激活 ρ ( y → ) \rho({\mathop{y}\limits ^{\rightarrow}}) ρ(y→)。
3 BN 的前向传播
在 BN 的前向传播过程中,先对加权和进行标准化处理(先减去均值,然后除以标准差),然后进行缩放平移,最后经过激活得到输出。整个过程如下图所示
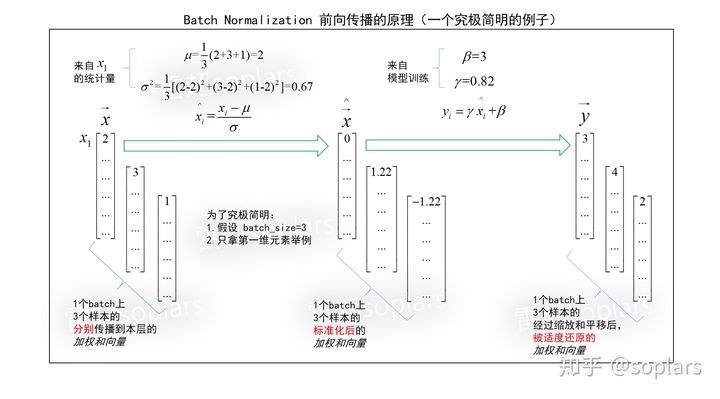
3.1 标准化
标准化:对于一组数据中的每个数据,先减去其均值再除以其标准差,把该组数据转换为一个均值为 0,方差为 1 的标准正态分布。只需求得均值
μ
\mu
μ 和方差
σ
2
\sigma^{2}
σ2 ,便可进行标准化
x
^
i
=
x
i
−
μ
σ
2
(
1
)
\hat{x}_i = \frac{x_i-\mu}{\sigma^{2}} ~~~~~~~~(1)
x^i=σ2xi−μ (1)
为避免分母为 0,可以给分母增加一个非常小的数
ϵ
\epsilon
ϵ
x
^
i
=
x
i
−
μ
σ
2
+
ϵ
(
2
)
\hat{x}_i = \frac{x_i-\mu}{\sqrt{\sigma^{2}+\epsilon}} ~~~~~~~~(2)
x^i=σ2+ϵxi−μ (2)
3.2 缩放平移
对式(1)进行变换,不难得到
x
i
=
σ
x
^
i
+
μ
(
3
)
x_i=\sigma\hat{x}_i +\mu ~~~~~~~~(3)
xi=σx^i+μ (3)
仿照式(3),构造缩放平移公式为
y
i
=
γ
x
^
i
+
β
(
4
)
y_i=\gamma\hat{x}_i +\beta ~~~~~~~~(4)
yi=γx^i+β (4)
显然,
γ
\gamma
γ 是对
x
^
i
\hat{x}_i
x^i 的缩放,
β
\beta
β 是对
γ
x
^
i
\gamma\hat{x}_i
γx^i 的平移。如果
γ
=
σ
\gamma=\sigma
γ=σ,
β
=
μ
\beta=\mu
β=μ,那么必然有
y
i
=
x
i
y_i=x_i
yi=xi,即对变换后的数据还原成功。(注意,
γ
\gamma
γ 和
β
\beta
β 都是向量,推导表明它们是可训练的)
- 只要损失函数有需要,公式 (4) 赋予了它左右 BN 层还原程度的能力,上限是完全还原;
- 具体对每一层还原多少,是由损失函数对每一层的这两个系数的梯度决定的;
- 损失通过梯度来控制还原的程度。
3.3 实现效果
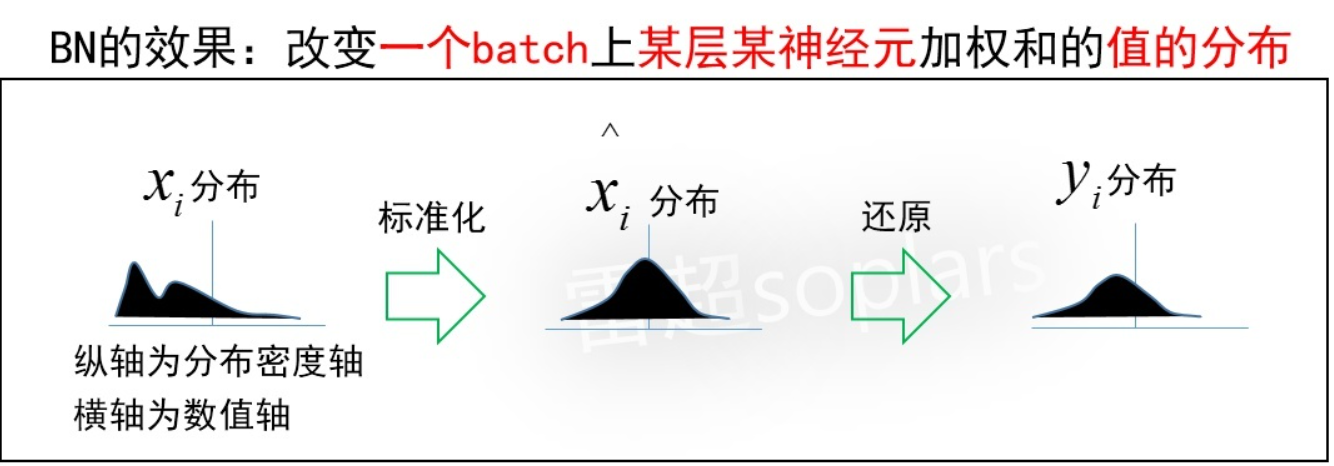
对于某一层 x → \mathop{x}\limits ^{\rightarrow} x→ 来说,它的每个元素值 x i x_i xi 在一个 batch 上的分布是一个任意的未知分布。BN 把它标准化为了一个标准正态分布。但这样是否太过暴力?如果所有输入样本被层层改变分布,相当于输入信息都已损失,网络将无法训练。因此,需要对标准正态分布再进行一定程度的还原操作,即缩放平移。最终使得这个数值分布得以兼顾保留有效信息,加速梯度训练。
4 总结
简言之,Batch Normalization 就是在加权和后加了一个标准化层和一个还原层:
- 标准化层,将一个 mini-batch 上的该层该神经元的数值处理为标准正态分布(均值为0,方差为1);
- 还原层,引入缩放系数、平移系数,用梯度控制还原程度。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









