







 文章详细探讨了在MySQL中,左连接和内连接在不同索引策略下的查询效率。通过创建和删除索引来测试,得出结论:对于左连接,右表的索引能更有效地优化查询;对于内连接,左右两表的索引都能提升效率。建议在连接字段上建立索引以优化查询性能。
文章详细探讨了在MySQL中,左连接和内连接在不同索引策略下的查询效率。通过创建和删除索引来测试,得出结论:对于左连接,右表的索引能更有效地优化查询;对于内连接,左右两表的索引都能提升效率。建议在连接字段上建立索引以优化查询性能。
下面的内容转载一个大佬的https://blog.youkuaiyun.com/PacosonSWJTU/article/details/84167069写的非常好,有事实有论据哈哈!

– 1、建表
drop table if exists dept_tbl;
create table dept_tbl (
rcrd_id int unsigned primary key auto_increment comment '记录编号'
, dept_id int unsigned not null comment '部门编号'
) engine = innodb default charset=utf8 comment '部门表'
;
drop table if exists emp_tbl;
create table emp_tbl (
rcrd_id int unsigned primary key auto_increment comment '记录编号'
, emp_id int unsigned not null comment '员工编号'
, dept_id int unsigned comment '部门编号'
) engine = innodb default charset=utf8 comment '员工表'
;
– 2、造数据;
insert into dept_tbl(dept_id) values (floor(1+(rand()*20)));
insert into dept_tbl(dept_id) values (floor(1+(rand()*20)));
insert into dept_tbl(dept_id) values (floor(1+(rand()*20)));
insert into dept_tbl(dept_id) values (floor(1+(rand()*20)));
insert into dept_tbl(dept_id) values (floor(1+(rand()*20)));
insert into dept_tbl(dept_id) values (floor(1+(rand()*20)));
insert into dept_tbl(dept_id) values (floor(1+(rand()*20)));
insert into dept_tbl(dept_id) values (floor(1+(rand()*20)));
insert into dept_tbl(dept_id) values (floor(1+(rand()*20)));
insert into dept_tbl(dept_id) values (floor(1+(rand()*20)));
insert into emp_tbl(emp_id, dept_id) values (floor(1+(rand()*10000)), floor(1+(rand()*50)));
insert into emp_tbl(emp_id, dept_id) values (floor(1+(rand()*10000)), floor(1+(rand()*50)));
insert into emp_tbl(emp_id, dept_id) values (floor(1+(rand()*10000)), floor(1+(rand()*50)));
insert into emp_tbl(emp_id, dept_id) values (floor(1+(rand()*10000)), floor(1+(rand()*50)));
insert into emp_tbl(emp_id, dept_id) values (floor(1+(rand()*10000)), floor(1+(rand()*50)));
insert into emp_tbl(emp_id, dept_id) values (floor(1+(rand()*10000)), floor(1+(rand()*50)));
insert into emp_tbl(emp_id, dept_id) values (floor(1+(rand()*10000)), floor(1+(rand()*50)));
insert into emp_tbl(emp_id, dept_id) values (floor(1+(rand()*10000)), floor(1+(rand()*50)));
insert into emp_tbl(emp_id, dept_id) values (floor(1+(rand()*10000)), floor(1+(rand()*50)));
insert into emp_tbl(emp_id, dept_id) values (floor(1+(rand()*10000)), floor(1+(rand()*50)));
– 3、查看索引
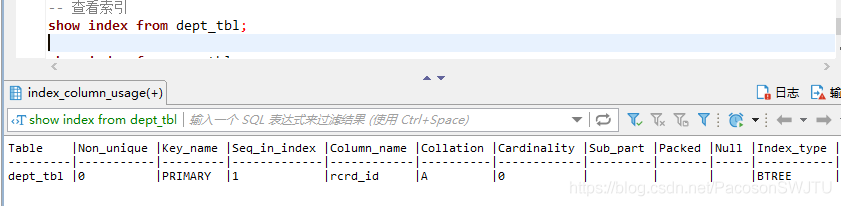
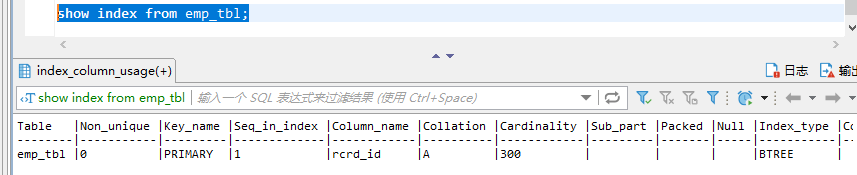
– 4、左连接
– 4.1、在左右表的连接字段dept_id上均未建索引的情况下,测试其扫描类型type和扫描行数rows
explain
select a.rcrd_id
, a.dept_id
, b.rcrd_id
, b.emp_id
, b.dept_id
from dept_tbl a
left join emp_tbl b
on a.dept_id = b.dept_id
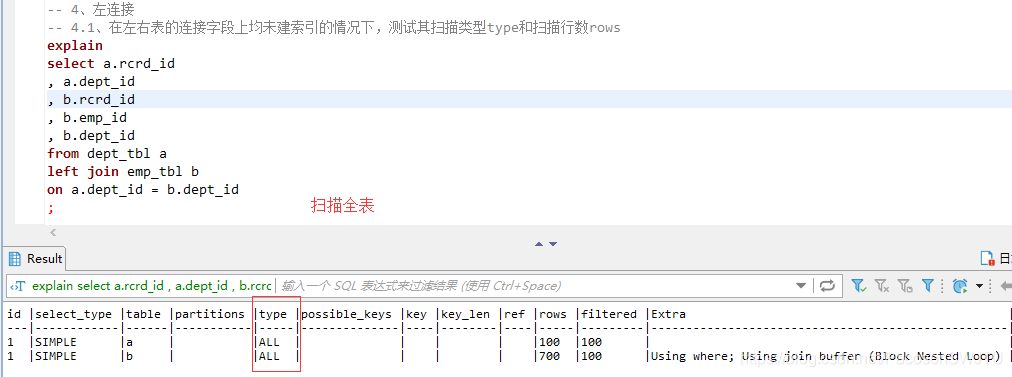
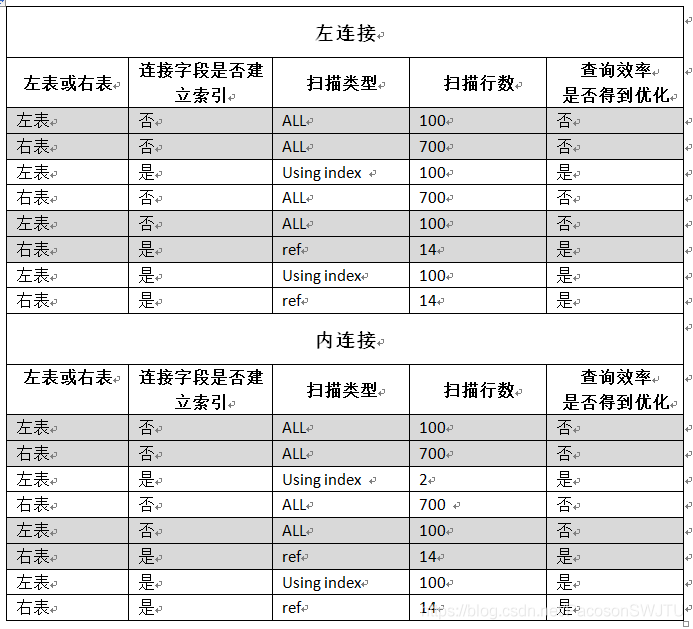
– 【结论4.1】 在左右表的连接字段dept_id上均未建索引的情况下:左连接使用全表扫描的方式查询左右表;
– 4.2、仅在左表连接字段dept_id上建索引,测试左连接的扫描类型type和扫描行数rows
alter table dept_tbl
add key `idx_dept_id` (`dept_id`)
;
explain
select a.rcrd_id
, a.dept_id
, b.rcrd_id
, b.emp_id
, b.dept_id
from dept_tbl a
left join emp_tbl b
on a.dept_id = b.dept_id
;
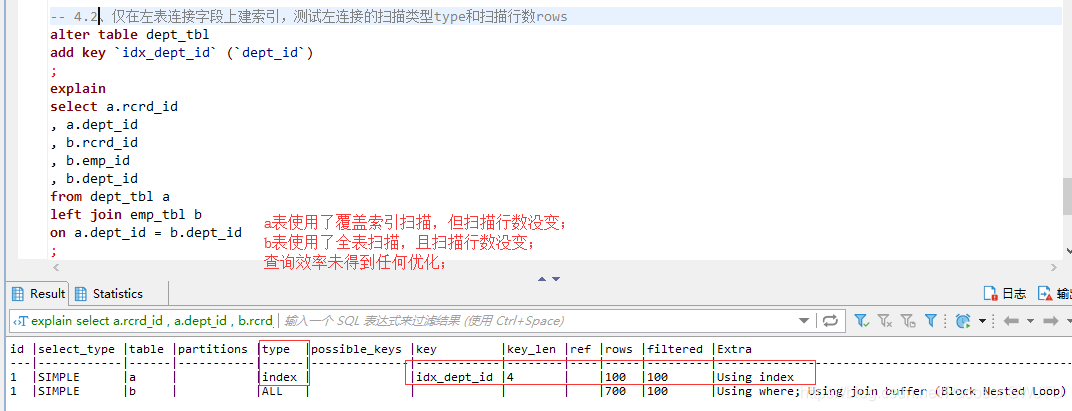
–【结论4.2】仅在左表连接字段dept_id上建索引: a表使用了覆盖索引扫描,但扫描行数没变,查询效率得到优化;b表使用了全表扫描,且扫描行数没变,查询效率未得到优化;
– 4.3、仅在右表连接字段dept_id上建索引,测试左连接的扫描类型type和扫描行数rows
alter table dept_tbl
drop key `idx_dept_id`
;
alter table emp_tbl
add key `idx_dept_id` (`dept_id`)
;
explain
select a.rcrd_id
, a.dept_id
, b.rcrd_id
, b.emp_id
, b.dept_id
from dept_tbl a
left join emp_tbl b
on a.dept_id = b.dept_id
;
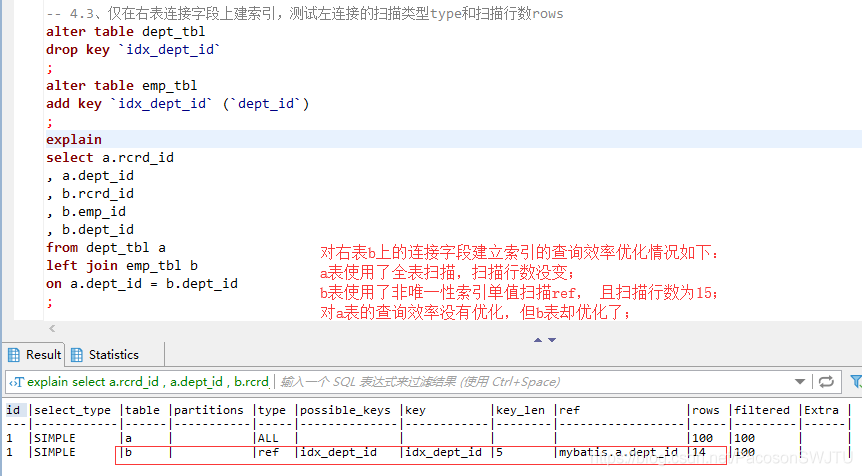
–【结论4.3】仅在右表连接字段dept_id上建索引: 对右表b上的连接字段建立索引的查询效率优化情况如下:
a表使用了全表扫描,扫描行数没变;b表使用了非唯一性索引单值扫描ref, 且扫描行数为15;对a表的查询效率没有优化,但b表却优化了;
– 4.4、在左表和右表的连接字段dept_id上都建索引,测试左连接的扫描类型type和扫描行数rows
alter table dept_tbl
add key `idx_dept_id` (`dept_id`)
;
alter table emp_tbl
add key `idx_dept_id` (`dept_id`)
;
explain
select a.rcrd_id
, a.dept_id
, b.rcrd_id
, b.emp_id
, b.dept_id
from dept_tbl a
left join emp_tbl b
on a.dept_id = b.dept_id
;
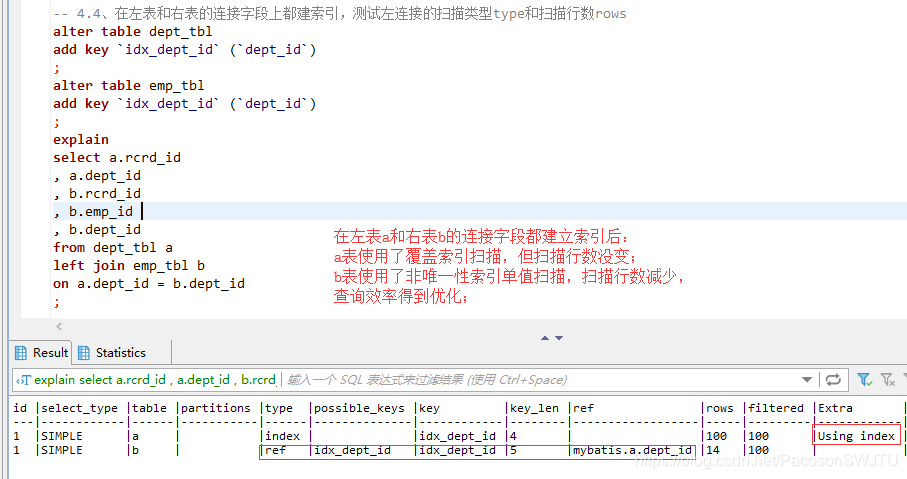
– 【结论4.4】在左表a和右表b的连接字段dept_id上都建索引后: a表使用了覆盖索引扫描,但扫描行数没变;b表使用了非唯一性索引单值扫描ref,扫描行数减少,查询效率得到优化;
– 5、内连接
– 5.0 查看索引
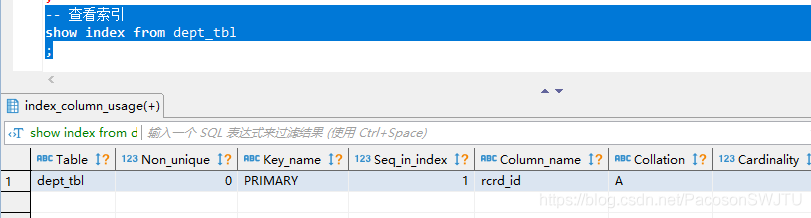
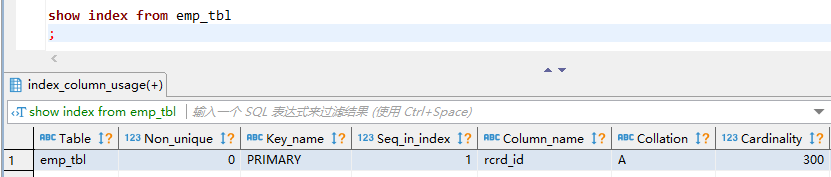
– 5.1、在左右表的连接字段dept_id上均未建索引的情况下,测试其扫描类型type和扫描行数rows
explain
select a.rcrd_id
, a.dept_id
, b.rcrd_id
, b.emp_id
, b.dept_id
from dept_tbl a
inner join emp_tbl b
on a.dept_id = b.dept_id
;
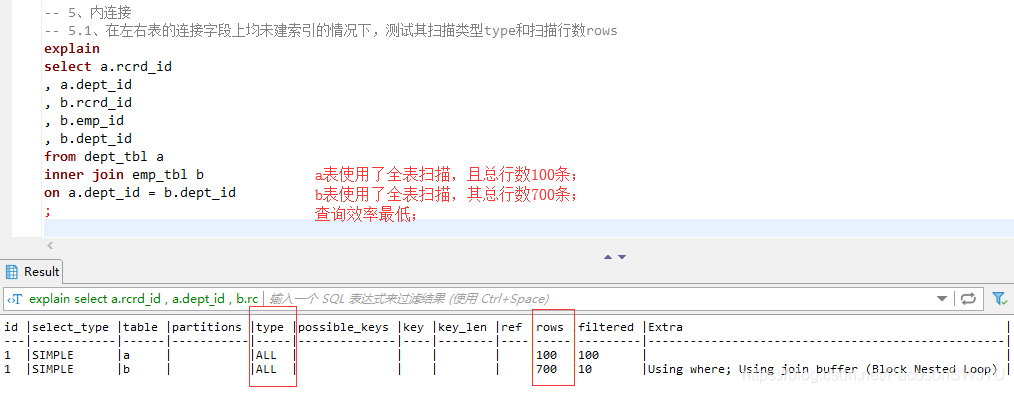
– 【结论5.1】在左右表上的连接字段均不建索引:a表使用了全表扫描,且总行数100条;b表使用了全表扫描,其总行数700条,这时的查询效率最低;
– 5.2、仅在左表连接字段dept_id上建索引,测试内连接的扫描类型type和扫描行数rows
alter table dept_tbl
add key `idx_dept_id` (`dept_id`)
;
explain
select a.rcrd_id
, a.dept_id
, b.rcrd_id
, b.emp_id
, b.dept_id
from dept_tbl a
inner join emp_tbl b
on a.dept_id = b.dept_id
;
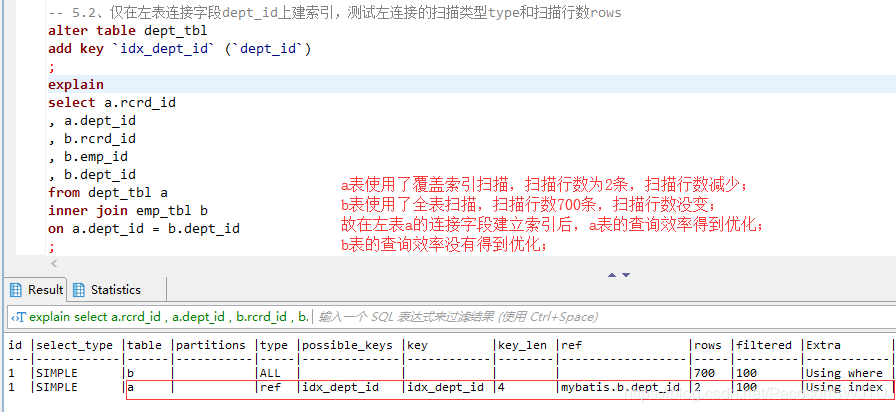
– 【结论5.2】 仅在左表连接字段上建索引: a表使用了覆盖索引扫描,扫描行数为2条,扫描行数减少;b表使用了全表扫描,扫描行数700条,扫描行数没变;故在左表a的连接字段建立索引后,a表的查询效率得到优化;
b表的查询效率没有得到优化;
– 5.3、仅在右表emp_tbl的连接字段dept_id上建索引,测试内连接的扫描类型type和扫描行数rows
alter table dept_tbl
drop key `idx_dept_id`
;
alter table emp_tbl
add key `idx_dept_id` (`dept_id`)
;
explain
select a.rcrd_id
, a.dept_id
, b.rcrd_id
, b.emp_id
, b.dept_id
from dept_tbl a
inner join emp_tbl b
on a.dept_id = b.dept_id
;
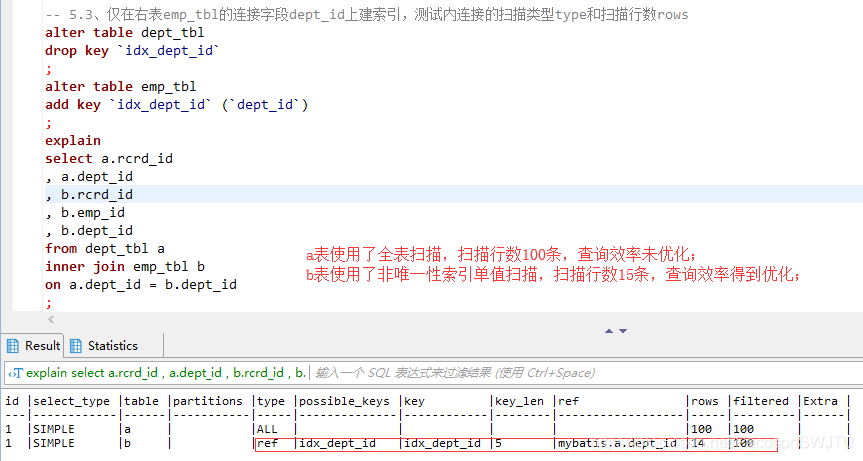
– 【结论5.3】仅在右表emp_tbl,即b表的连接字段dept_id上建索引: a表使用了全表扫描,扫描行数100条,查询效率未优化; b表使用了非唯一性索引单值扫描,扫描行数15条,查询效率得到优化;故在右表b的连接字段建立索引后,a表的查询效率没有得到优化;b表的查询效率得到优化;
– 5.4、在左表和右表的连接字段上都建索引,测试内连接的扫描类型type和扫描行数rows
alter table dept_tbl
add key `idx_dept_id` (`dept_id`)
;
alter table emp_tbl
add key `idx_dept_id` (`dept_id`)
;
explain
select a.rcrd_id
, a.dept_id as a_dept_id
, b.rcrd_id
, b.emp_id
, b.dept_id as b_dept_id
from dept_tbl a
inner join emp_tbl b
on a.dept_id = b.dept_id
;
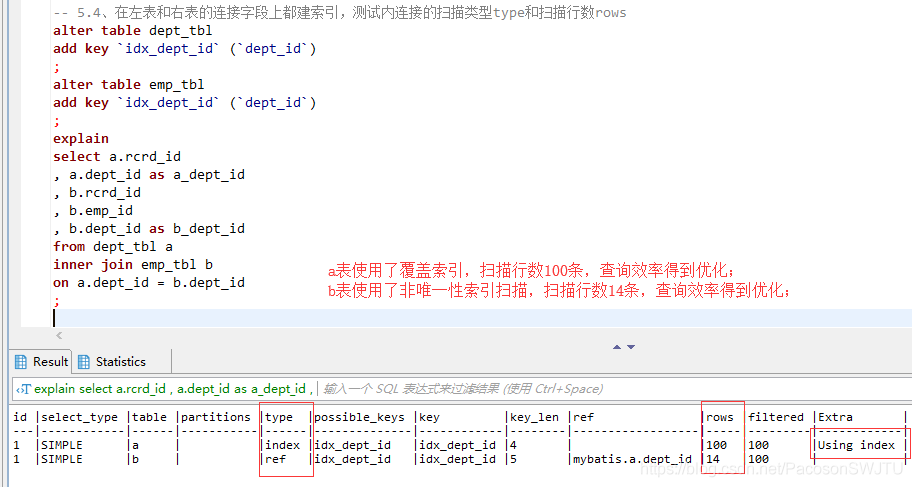
– 【结论5.4】 在左表和右表的连接字段上都建索引: 左表即a表使用了覆盖索引,扫描行数100条,查询效率得到优化; 右表即b表使用了非唯一性索引扫描,扫描行数14条,查询效率得到优化;
【总结论】
1、对于左连接:
1.1、在左表和右表的连接字段上都不建立索引:左右表都是全表扫描,查询效率最低;
1.2、仅在左表的连接字段上建立索引:左表使用了覆盖索引扫描,扫描行数没变,查询效率得到优化;b表使用了全表扫描,且扫描行数没变,查询效率未得到优化;
1.3、仅在右表连接字段上建索引: 左表表使用了全表扫描,扫描行数没变,查询效率未得到优化;右表使用了非唯一性索引单值扫描ref,扫描行数减少,查询晓得得到优化;
1.4、在左表和右表的连接字段上都建索引后: 左表使用了覆盖索引扫描,扫描行数没变,查询效率得到优化;右表使用了非唯一性索引单值扫描ref,扫描行数减少,查询效率得到优化;
2、对于内连接
2.1、在左表和右表的连接字段上都不建立索引:左右表都是全表扫描,查询效率最低;
2.2、仅在左表的连接字段上建立索引: 左表使用了覆盖索引扫描,扫描行数减少,查询效率得到优化;右表使用了全表扫描,扫描行数没变,查询效率没有得到优化;
2.3、仅在右表连接字段上建索引: 左表使用了全表扫描,扫描行数没变,查询效率未优化; 右表使用了非唯一性索引单值扫描,扫描行数减少,查询效率得到优化;
2.4、在左表a和右表b的连接字段上都建索引后:左表使用了覆盖索引,扫描行数不变,查询效率得到优化;右表使用了非唯一性索引扫描,扫描行数减少,查询效率得到优化;
3、全文总结论:
【关于左连接的结论补充】
补充1:由于非唯一性索引单值扫描ref 的查询效率高于索引扫描index的查询效率, 所以左连接建议优先在右表的连接字段添加索引,当然最好是左表也加上;
补充2:还有一个本质问题是左连接时左表是主表,无论右表如何,左表的记录都会出现在查询结果中,即无论索引怎么建立,都要遍历左表的所有记录行数;


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









