




注:如有理解不对的地方请指正
LayoutLMv1
- 标题:LayoutLM: Pre-training of Text and Layout for Document Image Understanding
- 链接:https://arxiv.org/abs/1912.13318
- 论文概要:该模型主要针对文档信息的处理,传统处理方式只使用文本信息,而本模型加入了布局信息(即文本的位置坐标)和视觉信息,并使用MVLM和MDC训练策略预训练了一个大模型,在下游任务取得SOTA结果。
- 预训练数据集:IIT-CDIP,包含6M份扫描文档,11M张图片,每个文档有对应的文本和元数据存储在xml文件中。(原始IIT-CDIP数据集没有布局信息,本文使用OCR重新对数据进行预处理)
- 评估数据集:FUNSD、SROIE、RVL-CDIP
- 模型规模:base版本和large版本,类比bert(base:110M,large:330M)
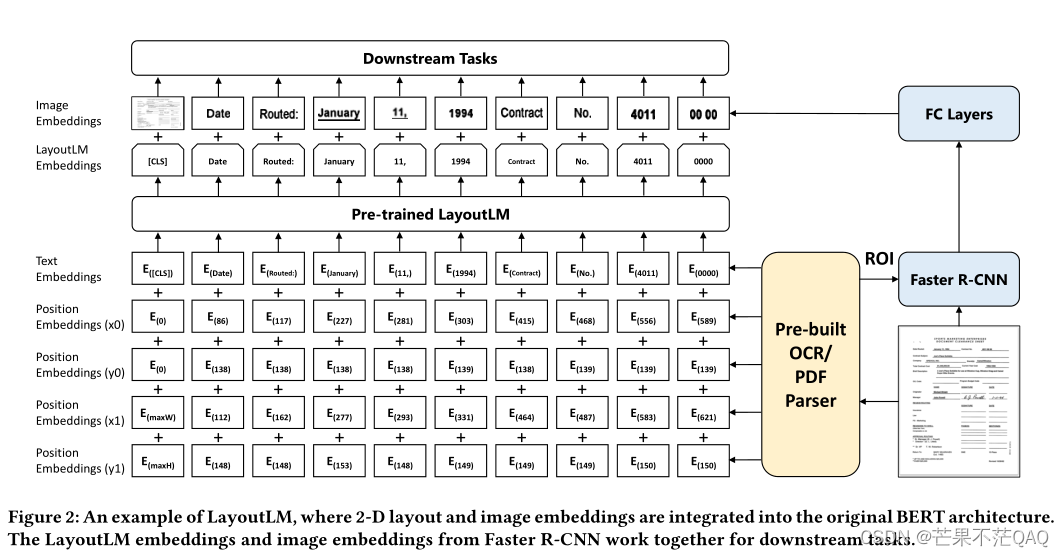
- 模型架构
- 文本嵌入:同bert,分词方法也同(WordPiece)
- 布局嵌入
- 以bert作为backbone,并添加四个新的输入,分别对应token左上角( x 0 x_0 x0, y 0 y_0 y0)坐标和右下角( x 1 x_1 x1, y 1 y_1 y1)坐标,文档页面左上角为原点,坐标取整数;
- x 0 x_0 x0和 x 1 x_1 x1共用一张嵌入表, y 0 y_0 y0和 y 1 y_1 y1共用一张嵌入表;
- CLS位置则用整个文本块的边界框坐标;
- 视觉嵌入
- 用FasterRCNN提取扫描件的视觉特征,将其与bert的输出融合,以此来做下游任务;
- FasterRCNN的backbone使用ResNet-101;
- CLS位置则将整幅图像视为感兴趣区域(ROI);
- 文本和对应布局信息都是用OCR得到的,OCR使用开源平台Tesseract;
- 预训练策略
- MVLM:Masked Visual-Language Model;以bert的MLM策略掩盖掉token,但保留对应的布局信息,借助布局信息和上下文信息预测对应token;
- MDC:Multi-label Document Classification;对文档进行分类,但文档标签不易获取,在预训练期间该策略可选(在下游任务上证实是有效的);
- 微调策略
- 对于序列标注任务,将每个token的最终输出连接到全连接层,再使用softmax得到每个标签的概率,计算交叉熵损失,不使用典型的CRF方法;
- 训练细节
- 用bert初始化除2维位置嵌入以外的部分;
- 由于不同文档的大小不同,将坐标统一缩放到0-1000,缩放后坐标取整数;
- 8块V100训练的,批次大小为80,Adam初始学习率为5e-5,使用线性衰减学习率;
- base在11M文档上训练一周期用80小时,large用170小时;
- 疑问
- 下游任务微调说端到端,但视觉部分更新吗?答:应该不会,因为在Layout2中反复强调会更新视觉部分;
LayoutLMv2
-
标题:LayoutLMv2: Multi-modal Pre-training for Visually-rich Document Understanding
-
论文概要:相比于v1更好的融入了视觉信息,以及视觉、文档和布局信息的对齐,引入空间自注意力编码,提出两种新的损失TIA和TIM,在下游任务取得新的SOTA结果。
-
预训练数据集:IIT-CDIP,同v1
-
评估数据集:FUNSD、CORD 、SROIE、Kleister-NDA 、RVL-CDIP、DocVQA
-
模型规模:base版本(200M)和large版本(426M)
-
模型架构
- 文本嵌入:同bert,分词方法也同(WordPiece)
- 视觉嵌入
- 用ResNeXt101-FPN来提取视觉特征,并与文本嵌入一起拼接到输入中;
- 将图片统一缩放到224*224大小,经过backbone后平均池化成固定大小W*H(7*7),再展平得到长度为49的序列,再经过一个线性层映射到与文本嵌入相同的维度;
- 额外增加一维位置嵌入,与文本一维位置嵌入共享参数;
- 片段嵌入使用C表示(相当于多了一个);
- ResNeXt-FPN参与更新;
- 布局嵌入
-
除左上角和右下角的(x,y)坐标外,额外增加宽w和高h嵌入;
-
布局嵌入与v1中四个坐标相加不同,这里拼接六个位置嵌入为一个输入,每个位置嵌入维度为隐层维度/6;
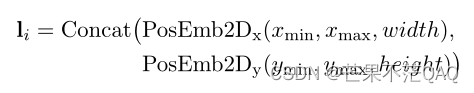
-
图像经backbone得到长度为49的序列,将其视为把原图切分成49个块,视觉部分的布局嵌入使用每个块的布局信息;
-
对于[CLS], [SEP]和[PAD],布局信息使用(0,0,0,0,0,0)表示;
-
- 空间感知自注意机制的多模态编码器
-
正常的自注意力将输入视为q、k、v,q和k点积后得到每个v的权重;
-
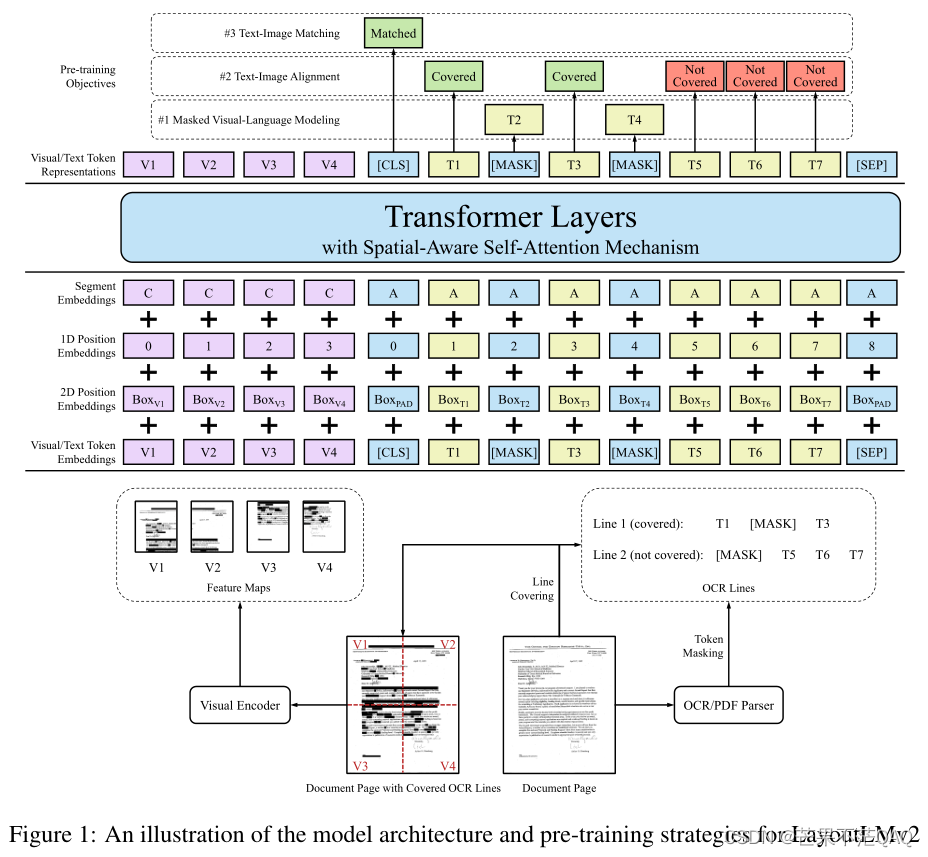
本文为了将显式的引入一维和二维的相对位置信息,在q和k点积计算完权重后,将位置信息作为偏差项加上,即
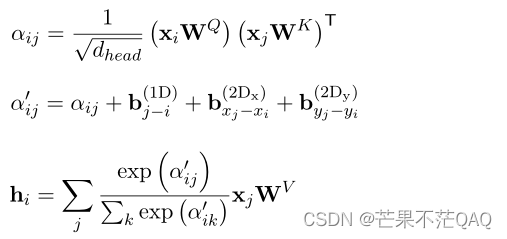
-
这些偏差项不同的注意力头之间是不同的,但在所有的层中都是相同的;
-
-
预训练策略
- MVLM:Masked Visual-Language Model;与v1中相同,为了避免视觉信息泄露,在送入视觉backbone之前,将对应掩码token的视觉区域掩盖掉;
- TIA:Text-Image Alignment
- 随机选择一些文本行,覆盖对应图像区域(为了避免与MVLM混淆,这里用覆盖(cover));
- 在编码器最后一层设置一个分类层,预测是否被覆盖,即[Convered]、[Not Convered],计算二元交叉熵损失;
- 由于图像分辨率有限,且一些符号和图本身就像被覆盖了一样,所以采用行级别;
- 当同时被mask和cover时,不计算TIA损失,为了防止学习到mask到cover的映射;
- TIM:Text-Image Matching
- 用CLS预测文本和图像是否来自同一文档,计算二元交叉熵损失;
- 常规为正样本,被另一文档的页面替换或直接删除作为负样本;
- 负样本执行相同的mask和cover操作,负样本的TIA标签全都为[Convered];
-
训练细节
- 文本嵌入层使用UniLMv2初始化;
- ResNeXt101-FPN使用了在PubLayNet上训练的MaskRCNN模型的backbone;
- 如果一个页面的文本太长,则使用文本序列的随机滑动窗口,视觉部分全部送入(不确定);
- MVLM中mask策略同v1;TIA中,随机15%的行被覆盖;TIM中,随机15%的图像被替换,5%被丢掉;
- Adam优化器学习率2e-5,权重衰减0.01,(β1, β2) = (0.9, 0.999),学习率前10%热启动,然后线性衰减;
- base训练5周期,批次大小为64;large训练20周期,批次2048;
LayoutXLM
-
标题:LayoutXLM: Multimodal Pre-training for Multilingual Visually-rich Document Understanding
-
论文概要:LayoutLMv2的多语言版本,在模型方面只针对多语言的不同做了些小的改动,主要说明预训练数据集和验证数据集的制作细节。
-
预训练数据集:IIT-CDIP和大量互联网上公开可用的电子版PDF文件
-
评估数据集:XFUND;为了评估模型,本文提出一个人工标注的多语言表单理解数据集XFUND,包含中文、日语、西班牙语、法语、意大利语、德语、葡萄牙语七种语言,每个都标注了键值对;
-
模型规模:base版本(345M)和large版本(625M),嵌入层大了
-
模型架构:同v2,只是用多语言进行预训练;
- 布局嵌入:与v2中以单词级别取布局信息不同,由于各种语言的切分方式差异,这里取字符级别,通过合并一个token中每个字符的边界框来得到最终的边界框坐标;
-
预训练数据集
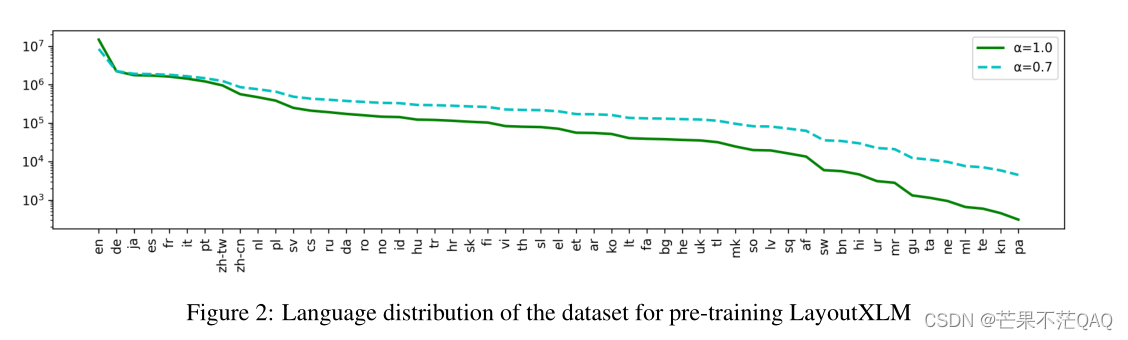
- 使用了53种语言,下图为各语言的分布;
- 根据Common Crawl的政策,并只收集电子版pdf,不收集扫描件。因为电子版可以直接解析各字符坐标,节省了使用OCR的费用;
- 使用PyMuPDF开源PDF解析器提取文本、布局和图像,丢弃少于200字符的数据;
- 使用BlingFire库中的语言检测器,并按语言拆分数据。再使用CCNet模型检测,如果某个语言的得分超过0.5,则将其分类为对应的语言,否则将其视为不清晰的PDF而丢弃;
- 对每个batch使用与XLM相同的方式采样各个语言的数据,概率 p l ∝ ( n l / n ) α p_l ∝(n_l/n)α pl∝(nl/n)α;
- 再加上IIT-CDIP中的800万份扫描的英文文档,共计3000万份文档;
-
XFUND表单评估数据集
- 标注了键值对,即对应着语义实体识别和关系提取任务;
- 在获取数据集时,为防止真实世界的敏感信息泄露,只保留文档的模板并手动填写合成信息,一部分打印,一部分手写;
- 表单最终被扫描成文档图像,为了进一步用OCR处理;
- XFUND包括7种语言和1393个完全注释的表单,每种语言包括199个表单,其中训练集包括149个表单,测试集包括50个表单;
-
训练细节
- 用InfoXLM初始化文本嵌入层;
- 用64块V100训练;
-
微调细节
- 为了验证多语言理解的能力,设计了三种任务
- 特定语言微调,特定语言测试
- 只用英语微调,即用FUNSD来微调,所有语言测试
- 所有语言微调,所有语言测试
- 为了验证多语言理解的能力,设计了三种任务
LayoutLMv3
-
标题:LayoutLMv3: Pre-training for Document AI with Unified Text and Image Masking
-
论文概要:相比于之前版本,文本的布局信息使用了片段级别,一段文本共用一组坐标。视觉借鉴了ViT的方法,丢掉了CNN,减少了参数以及省去了很多的预处理步骤。使用了两种新的损失MIM和WPA,在下游任务取得新的SOTA结果。
-
预训练数据集:IIT-CDIP,同v1
-
评估数据集:FUNSD、CORD 、DocVQA 、RVL-CDIP、PubLayNet
-
模型规模:base版本(133M)和large版本(368M)
-
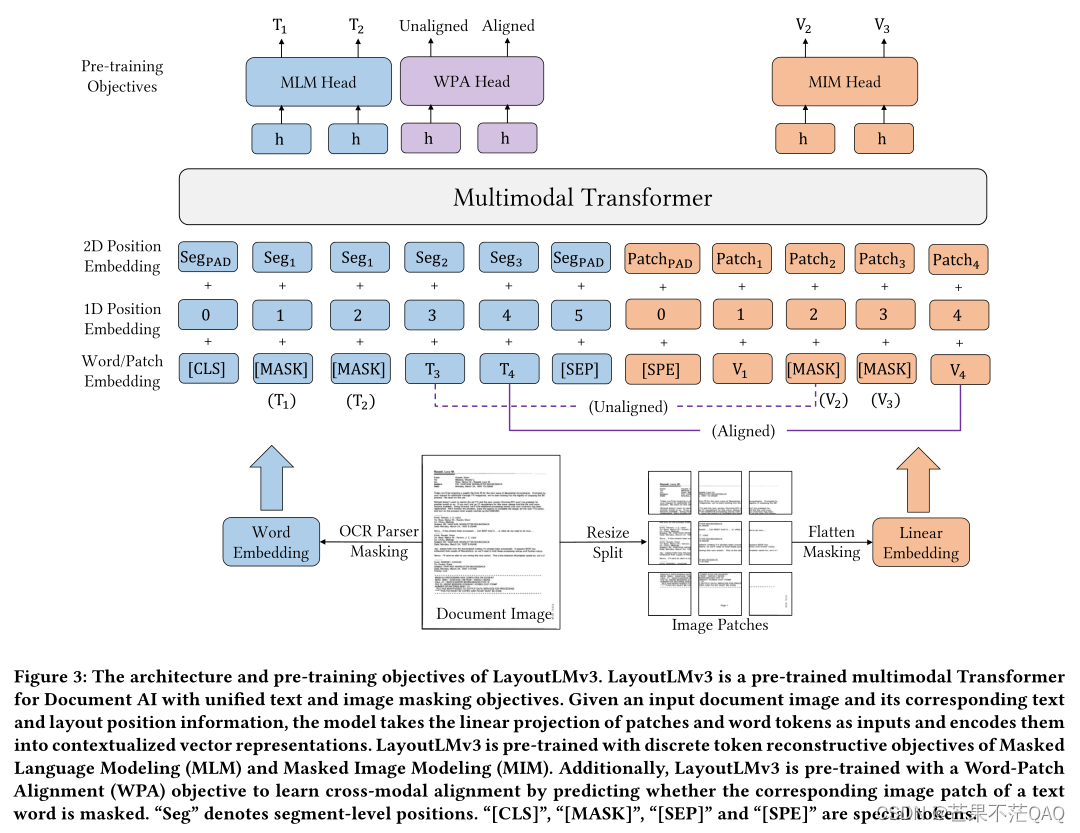
模型架构
- 文本嵌入:同v2,使用BPE分词,RoBERTa初始化词嵌入
- 布局嵌入:同v2,与v1和v2中用单词级别的布局位置不同,这里用片段级别(segment-level ),即一个ocr框中的文本共用一组坐标,如一行、或表格中的一个单元格(推测),因为它们通常表达相同的语义。
- 视觉嵌入:不再使用CNN结构的网络
- 类似ViT,将图片缩放到224*224,然后将其切分成多个16*16大小的patches,共14*14=196个(224/16=14),每个patch使用卷积线性投影成和文本嵌入同样的维度(使用卷积是为了将通道合并),再将其展平变成序列,加上[CLS]的嵌入,视觉部分长度恒定为197个;
- 视觉部分也增加一维位置嵌入,因为实验部分没有看到2维位置嵌入有明显的改进;
- 视觉部分的二维布局嵌入是将patch平均映射到文本的布局,即每个patch布局坐标大小为1000/14=71,那第一个位置的视觉布局嵌入为(0,0,71,71),第二个位置是(71,0,142,71);
- 空间感知自注意机制的多模态编码器:同v2
-
预训练策略
- MLM:Masked Language Modeling;使用span掩码策略,掩盖掉30%的文本token,掩盖的span长度服从泊松分布(λ=3);
- MIM:Masked Image Modeling
- 用分块掩码策略随机掩盖掉40%的图像token,用交叉熵损失驱动其重建被掩盖的图像区域;
- 图像token的标签来自一个图像tokenizer,通过图像vocab将密集图像的像素转化成离散token,相比于低级高噪声的细节部分,更促进学习高级特征;
- 相当于MLM应用到了图像上;
- WPA:Word-Patch Alignment
- MLM和MIM分别进行掩码,彼此之间没有对齐;
- 每个文本token都对应着一个图像patch,预测文本对应的图像块是否被屏蔽;
- 文本和图像同时没有被掩码,则对应[aligned]标签;
- 否则,对应[unaligned]标签;
- 当文本token被掩码时,不参与WPA损失计算,防止学习mask与图像块的对应关系;
- 用两层全连接,输入上下文文本和图像信息,即每个位置的文本token,和与之对应图像块的编码器输出,输出是否对齐,
-
训练细节:为了节省缓存,能用的trick都用了
- 分布式、混合精度、梯度累计、梯度检查点;
- 用RoBERTa初始化,视觉tokenzier部分用DiT初始化(一个自监督文档图像的预训练模型);
- 视觉tokenizer词汇表大小为8192,随机初始化其余参数;
- Adam优化器,批次大小2048,执行500000个step,权重衰减0.01,(β1, β2) = (0.9, 0.98);
- base模型学习率1e-4,前4.8%热启动;large模型学习率5e-5,前10%热启动;


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









