




LLaMA现在已经是开源社区里炙手可热的模型了,但是原文中仅仅介绍了其和标准Transformer的差别,并没有一个全局的模型介绍。因此打算写篇文章,争取让读者不参考任何其他资料把LLaMA的模型搞懂。
结构
如图所示为LLaMA的示意图,由Attention和MLP层堆叠而成
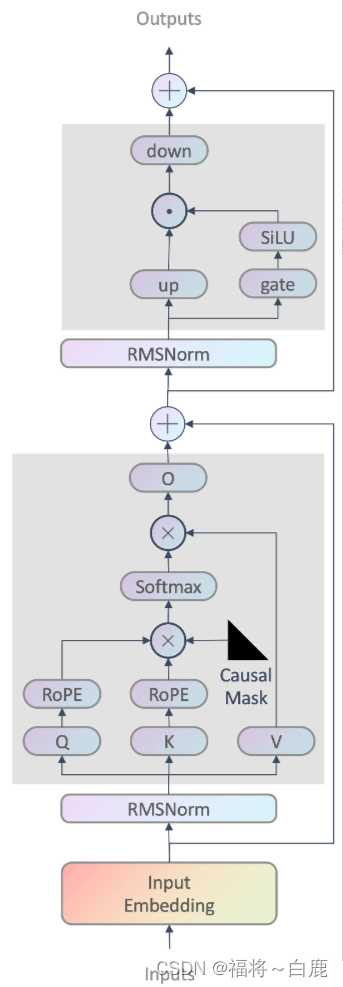
LLaMA模型主要由Attention和MLP层堆叠而成,具有以下特点:
1、前置的RMSNorm:RMSNorm是一种归一化技术,用于稳定模型的训练过程,提高模型的收敛速度。
2、Q、K上的RoPE旋转式位置编码:位置编码用于捕捉序列中的位置信息,RoPE旋转式位置编码能够有效地处理长序列,提高模型的性能。
3、Causal mask:该机制保证每个位置只能看到前面的tokens,确保了模型的自回归性质。
4、使用了Group Query Attention:通过使用分组查询注意力(GQA),LLaMA能够在保持性能的同时,降低模型的计算复杂度,提高推理速度。
5、MLP表达式:down(up(x) * SILU(gate(x))),其中down, up, gate都是线性层
LLaMA各个不同大小的结构设置如下表所示。其中最大的65B的LLaMA用了2048张80GB的A100,batch size为4百万,训练一次需要21天。
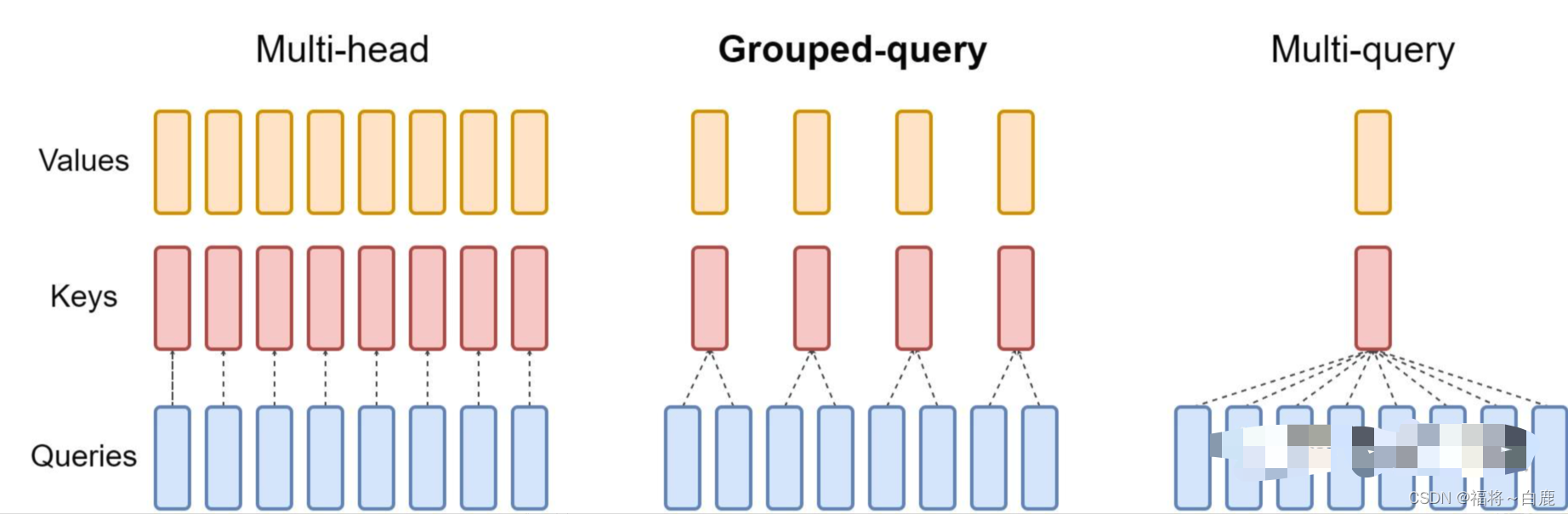
Group Query Attention(V2 only)
自回归模型生成回答时,需要前面生成的KV缓存起来,来加速计算。多头注意力机制(MHA)需要的缓存量很大,Multi-Query Attention指出多个头之间可以共享KV对。Group Query Attention没有像MQA一样极端,将query分组,组内共享KV,效果接近MHA,速度上与MQA可比较。p.s. 这个技术falcon已经用上了,当时falcon说自己用的是multi query attention,因为当group=1时,GQA和MQA是等价的。falcon支持设置不同的G。
RMSNorm
这是在BERT、GPT等模型中广泛使用的LayerNorm:

RMSNorm(root mean square)发现LayerNorm的中心偏移没什么用(减去均值等操作)。将其去掉之后,效果几乎不变,但是速度提升了40%。最终公式为:

注意除了没有减均值,加偏置以外,分母上求的RMS而不是方差。
LLaMA在 Attention Layer和MLP的输入上使用了RMSNorm,相比在输出上使用,训练会更加稳定。
SwiGLU
LLaMA没有使用ReLU,而是使用了SwiGLU,有时也被称为SiLU。公式为:
,效果类似平滑版的ReLU:

RoPE
LLaMA使用了Rotary Position Embedding。对于Q的第m个位置向量q,通过以下方法注入位置编码:

class LlamaRotaryEmbedding(torch.nn.Module):
def  最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 513
513

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









