




 本文深入解析Java集合框架,包括各种集合的特点及应用场景,ArrayList与LinkedList的对比,哈希表及哈希冲突解决方法,以及HashMap的工作原理等核心知识点。
本文深入解析Java集合框架,包括各种集合的特点及应用场景,ArrayList与LinkedList的对比,哈希表及哈希冲突解决方法,以及HashMap的工作原理等核心知识点。
-
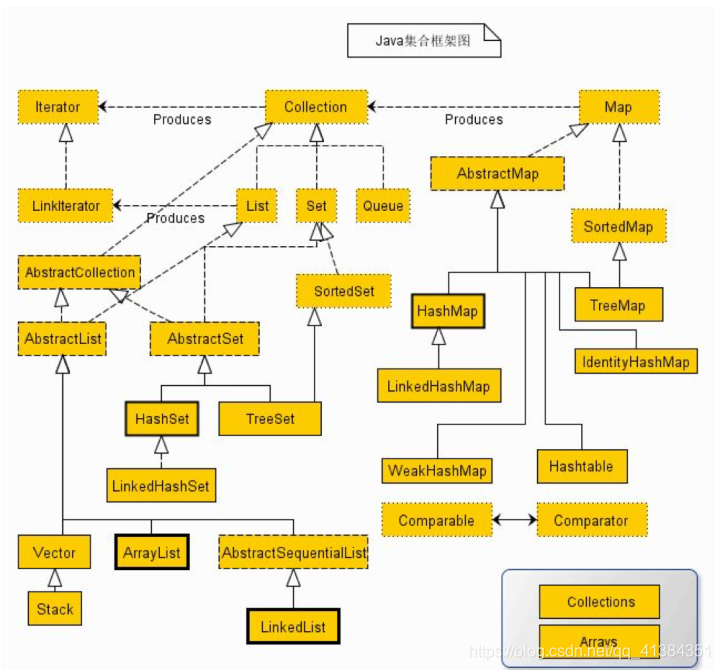
集合框架图(要求掌握基础接口和子接口及其各个实现类的特点)
-
各种集合的源码解读及特有方法了解
-
每种集合的特点及应用场景?
-
ArrayList和LinkedList的异同点?
a.相同点:
继承关系:List接口下的实现类具有List提供的方法
有序性:数据都是插入有序
重复性:元素是可以重复的
null值:可以存储null值
安全性:都是非线程安全的集合(都可能会出现并发性异常)
b.不同点:
数据结构:ArrayList底层是数组。LinkedList底层是双向链表
特有方法:LinkedList因为实现了Deque双向队列接口,具有特有的方法:例如addFirst() 、 addLast()()
效率:ArrayList访问效率高,移动、删除效率低, LinkedList 插入、删除效率高,访问效率低 -
ArrayList和数组的区别?
a. 初始化大小 :数组必须指定大小,ArrayList不需要指定大小,因为它可以动态扩容
b. 存储数据类型:数组可以存储引用类型和基本类型,ArrayList只能存储引用类型。
ArrayList比数组更加灵活 -
迭代器的概念,自定义实现方式及三种方法?
Iterator是一种设计模式,其作用是就是提供一种方法对一个容器/集合对象中的各个元素进行访问,而又不暴露该对象容器的内部细节
在Java中,有很多的数据容器,对于这些的操作有很多的共性,Java采用了迭代器来为各种容器提供了公共的操作接口。
这样使得对容器的遍历操作与其具体的底层实现相隔离,达到解耦的效果。
自定义迭代器类需要具有iterator方法,需要实现iterable接口(implements Iterator)
迭代器接口提供的方法:
boolean hasNext() 判断集合中还有没有可以被取出的元素,如果有返回true
next() 取出集合中的下一个元素
remove() 删除元素 -
集合产生的并发异常问题?
详细点击→:并发异常ConcurrentModificationException -
iterator和ListIterator的异同?
1. ListIterator有add()方法,可以向List中添加对象,而Iterator不能添加。
2. ListIterator和Iterator都有hasNext()和next()方法,可以实现顺序向后遍历,
但是ListIterator有hasPrevious()和previous()方法,可以实现逆向(顺序向前)遍历。
3. ListIterator可以定位当前的索引位置,nextIndex()和previousIndex()可以实现
4. 都可实现删除对象,但是ListIterator的set()方法可以实现对象的修改。Ilerator仅能遍历,不能修改。
-
什么是哈希表,什么是哈希函数,哈希冲突?怎么解决哈希冲突?
哈希表:通过关键码来映射到一个值的数据结构
哈希函数:键与值映射的一个映射关系
哈希函数有两种方法:
1. 直接寻址法: f (x) = kx+b(k、b为常数)

2. 除留余数法: f (x) = x%k(k<=m) (m为存储位置的长度)

哈希冲突的解决办法:
1. 链地址法:
把同一位置的数据,通过链表链接在当前位置下。
2. 探测法:
①线性探测:从第一个位置开始查找,若这个位置没有元素,则将数据插入,否则查找下一个,查到最后一个位置再返回到第一个位置再查找。
②随机探测:一个随机数,探测这个随机数的位置是否有元素,无则将数据插入,有则以当前位置+随机数为下一个位置继续查找。 -
HashMap的三种遍历方式?
a.通过键值对遍历:(hashMap.entrySet().iterator())
先将hashMap实例转化为set实例(类型为map.entry<>),
Iterator<Map.Entry<String,String>> iterator = hashMap.entrySet().iterator();
while(iterator.hasNext()){
Map.Entry<String,String> next = iterator.next();
String key = next.getKey();
String value = next.getValue();
System.out.print(key+":"+value+".");
}
b.通过键来遍历 (hashMap.keySet().iterator())
Iterator iterator1 = hashMap.keySet().iterator();
while(iterator1.hasNext()){
String next = iterator1.next();
System.out.print(next+".");
}
c.通过值来遍历 ( hashMap.values().iterator())
Iterator iterator2 = hashMap.values().iterator();
while(iterator2.hasNext()){
String next = iterator2.next();
System.out.print(next+" ");
} -
HashMap的工作原理 (实质上就是问它的put()方法)?
HashMap基于hashing原理,当我们将键值对传递给put()方法时,它调用键对象的hashCode()方法来计算hashcode,
让后找到bucket位置来储存值对象。当获取对象时,通过键对象的equals()方法找到正确的键值对,
然后返回值对象。HashMap使用链表来解决碰撞问题,当发生碰撞了,对象将会储存在链表的下一个节点中。
HashMap在每个链表节点中储存键值对对象。当两个不同的键对象的hashcode相同时 ,它们会储存在同一个bucket位置的链表中。键对象的equals()方法用来找到键值对。
源码步骤:
第一次插入元素,需要对数组进行初始化,数组长度为2的指数, 判断key为null或者非null
当key不为null时通过key哈希(hashing)来找到数据存在的索引位置,遍历该位置下的链表,(判断key是否存在,存在则替换value,不存在创建新的entry)
当key为null时,存在数组的索引为0的位置,遍历该位置下的链表,查看key为null的节点是否存在,
存在的话,将value的值更新为传入的value,若该链表下不存key为null的节点,则创建新的entry节点插入该链表。 -
HashTable和 HashMap的异同点?
相同点:
1.底层数据结构相同,数组+链表
2.key都不能重复
3.插入元素不能保证有序
4.通过key进行哈希
不同点:
1.安全性问题
HashTable中的方法都有Synchronized修饰,线程安全:在多线程访问情况下,
2.继承关系:
hashMap继承AbstractMap
hashTable继承Dictionary
3.扩容方式:
HashMap为2倍(2table.length),HashTable为2的倍数+1[(2table.length)+1]
4.null值:
HashTable的键值不能为空。hashMap键值可以为空
5.默认值:
hashTable数组默认大小11
hashMap数组默认大小16
6.hash算法不同
7.效率不同:
hashMap在单线程下效率高
hashTable在单线程下效率低 -
HashTable为什么是线程安全的?如何让HashMap在多线程下具有安全性?
HashTable保证线程安全的原理:
hashTable中添加Syncnized关键字,该关键字是一个互斥锁。目的是同一时刻只能有一个线程对资源进行访问
在hashMap中,对put,get等一般方法添加Syncnized关键字,修饰的是类对象,该对象调用put操作,即为该对象添加了一个即为该 hashTable对象添加了一个互斥锁,同时只能有一个线程访问hashtable,从而保证添加元素不会出现异常,
底层操作系统提供的数组机制》从用户切换到内核态运行,当前的线程被阻塞住。
hashMap怎样具有线程安全性:使用集合工具类collection可以使hashMap线程安全。 collection.SyncnizedMap -
HashMap和LinkedHashMap的不同点?
1.继承关系不同:LinkedHashMap继承hashMap
2.Entry节点不同:LinkedHashMap节点新加了before和after
3.新增成员属性:header和accessOrder
accessOrder为默认值false的话:插入有序
accessOrder为true的话:访问有序 -
WeakHashMap涉及的重点?(四种Java引用)
4种Java引用:强引用 弱引用 软引用 虚引用 (这些过程会引起垃圾回收)
强引用: 一个对象如果只有强引用,那么垃圾回收器不会回收这个对象,
即使内存不足的情况下,JVM宁愿抛出内存不足的异常都不会回收这个对象。
直到对象为空,才可以回收
软引用: 一个对象只有软引用,如果内存充足的情况下,垃圾回收器则不会回收垃圾。
如果内存不足,垃圾回收器会回收该对象
弱引用: 所作用的对象一旦发生垃圾回收,该引作用的对象就会被回收掉,
弱引用和软引用的对象比较,生命力更短
虚引用: 虚引用无法左右对象的生命周期。用来检测当前对象有没有被回收掉
- 什么是红黑树?
1.每个节点都只能是红色或黑色
2.根节点是黑色
3.每个叶子节点(null节点或者空节点)是黑色
4.一个节点是红色,则两个子节点是黑色,也就是说一条路径上不能出现相邻的两个红色节点
5.从任一节点到其每个叶子的所有路径都包含相同数目的黑色节点。
- Comparator和Comparable接口是干什么的,区别是什么?
Comparator和Comparable是比较器类
相同点:
都是Java的接口,用来对自定义类进行大小比较
不同点:
1.使用不同:Comparator定义在类外部,Comparable定义在类内部
2.提供的接口不同:实现Comparator需要覆盖compare方法,实现Comparable要覆盖compareTo方法。
用Comparable 简单, 只要实现Comparable接口的对象直接就成为一个可以比较的对象,但是需要修改源代码。
用Comparator 的好处是不需要修改源代码, 而是另外实现一个比较器, 当某个自定义的对象需要作比较的时候,把比较器和对象一起传递过去就可以比大小了, 并且在Comparator 里面用户可以自己实现复杂的可以通用的逻辑,使其可以匹配一些比较简单的对象

















 2462
2462

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









