



07 外连接(OUTER JOINs)
用LEFT/RIGHT/FULL JOINs 做多表查询
SELECT column, another_column, …
FROM mytable
INNER/LEFT/RIGHT/FULL JOIN another_table
ON mytable.id = another_table.matching_id
WHERE condition(s)
ORDER BY column, … ASC/DESC
LIMIT num_limit OFFSET num_offset;
小贴士?
这些Join也可以写作 LEFT OUTER JOIN, RIGHT OUTER JOIN, 或 FULL OUTER JOIN, 和 LEFT JOIN, RIGHT JOIN, and FULL JOIN 等价.

练习 do it — 请完成如下任务
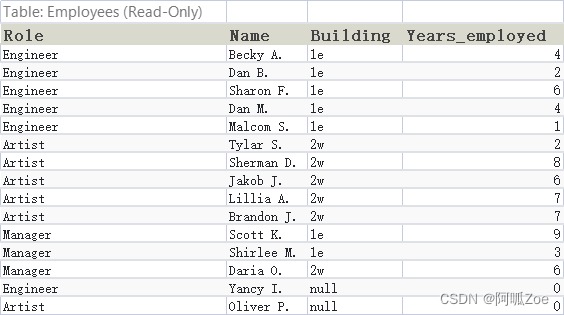
【复习】找到所有有雇员的办公室(buildings)名字
【复习】找到所有办公室里的所有角色(包含没有雇员的),并做唯一输出(DISTINCT)
【难题】找到所有有雇员的办公室(buildings)和对应的容量
08 关于特殊关键字 NULLs
在查询条件中处理 NULL
SELECT column, another_column, …
FROM mytable
WHERE column IS/IS NOT NULL
AND/OR another_condition
AND/OR …;
【复习】找到雇员里还没有分配办公室的(列出名字和角色就可以)
【难题】找到还没有雇员的办公室
09 在查询中使用表达式
每一种数据库(mysql,sqlserver等)都有自己的一套函数,包含常用的数字,字符串,时间等处理过程.具体需要参看相关文档。
当我们用表达式对col属性计算时,很多事可以在SQL内完成,这让SQL更加灵活,但表达式如果长了则很难一下子读懂。所以SQL提供了AS关键字, 来给表达式取一个别名.
AS使用别名
SELECT col_expression AS expr_description, …
FROM mytable;
实际上AS不仅用在表达式别名上,普通的属性列甚至是表(table)都可以取一个别名,这让SQL更容易理解.
属性列和表取别名的例子
SELECT column AS better_column_name, …
FROM a_long_widgets_table_name AS mywidgets
INNER JOIN widget_sales
ON mywidgets.id = widget_sales.widget_id;
练习 do it — 请完成如下任务
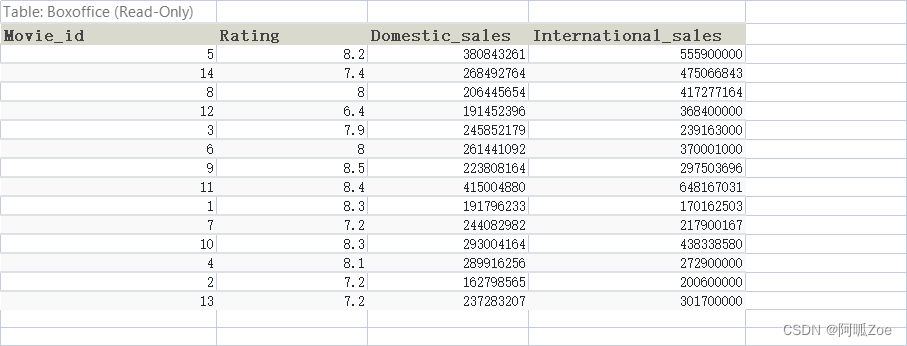
【计算】列出所有的电影ID,名字和销售总额(以百万美元为单位计算)
【计算】列出所有的电影ID,名字和市场指数(Rating的10倍为市场指数)
【计算】列出所有偶数年份的电影,需要电影ID,名字和年份
【难题】John Lasseter导演的每部电影每分钟值多少钱,告诉我最高的3个电影名和价值就可以

10 在查询中进行统计I (Pt. 1)
常见统计函数
下面介绍几个常用统计函数:

分组统计
GROUP BY 数据分组语法可以按某个col_name对数据进行分组,如:GROUP BY Year指对数据按年份分组, 相同年份的分到一个组里。如果把统计函数和GROUP BY结合,那统计结果就是对分组内的数据统计了.
GROUP BY 分组结果的数据条数,就是分组数量,比如:GROUP BY Year,全部数据里有几年,就返回几条数据, 不管是否应用了统计函数.
用分组的方式统计
SELECT AGG_FUNC(column_or_expression) AS aggregate_description, …
FROM mytable
WHERE constraint_expression
GROUP BY column;
练习 do it — 请完成如下任务
【统计】找出就职年份最高的雇员(列出雇员名字+年份)
【分组】按角色(Role)统计一下每个角色的平均就职年份
【分组】按办公室名字总计一下就职年份总和
【难题】每栋办公室按人数排名,不要统计无办公室的雇员
11 在查询中进行统计II
用HAVING进行筛选
SELECT group_by_column, AGG_FUNC(column_expression) AS aggregate_result_alias, …
FROM mytable
WHERE condition
GROUP BY column
HAVING group_condition;
HAVING 和 WHERE 语法一样,只不过作用的结果集不一样. 在我们例子数据表数据量小的情况下可能感觉 HAVING没有什么用,但当你的数据量成千上万属性又很多时也许能帮上大忙 .
小贴士?
如果你不用GROUP BY语法, 简单的WHERE就够用了.
练习 do it — 请完成如下任务
【统计】统计一下Artist角色的雇员数量
【分组】按角色统计一下每个角色的雇员数量
【分组】算出Engineer角色的就职年份总计
【难题】按角色分组算出每个角色按有办公室和没办公室的统计人数(列出角色,数量,有无办公室,注意一个角色如果部分有办公室,部分没有需分开统计)
12 查询执行顺序
完整的SELECT查询
SELECT DISTINCT column, AGG_FUNC(column_or_expression), …
FROM mytable
JOIN another_table
ON mytable.column = another_table.column
WHERE constraint_expression
GROUP BY column
HAVING constraint_expression
ORDER BY column ASC/DESC
LIMIT count OFFSET COUNT;
一个查询SQL的执行总是先从数据里按条件选出数据,然后对这些数据再次做一些整理处理,按要求返回成结果,让结果尽可能是简单直接的。因为一个 查询SQL由很多部分组成,所以搞清楚这些部分的执行顺序还挺重要的,这有助于我们更深刻的理解SQL执行过程.
查询执行顺序
1. FROM 和 JOINs
FROM 或 JOIN会第一个执行,确定一个整体的数据范围. 如果要JOIN不同表,可能会生成一个临时Table来用于 下面的过程。总之第一步可以简单理解为确定一个数据源表(含临时表)
2. WHERE
我们确定了数据来源 WHERE 语句就将在这个数据源中按要求进行数据筛选,并丢弃不符合要求的数据行,所有的筛选col属性 只能来自FROM圈定的表. AS别名还不能在这个阶段使用,因为可能别名是一个还没执行的表达式
3. GROUP BY
如果你用了 GROUP BY 分组,那GROUP BY 将对之前的数据进行分组,统计等,并将是结果集缩小为分组数.这意味着 其他的数据在分组后丢弃.
4. HAVING
如果你用了 GROUP BY 分组, HAVING 会在分组完成后对结果集再次筛选。AS别名也不能在这个阶段使用.
5. SELECT
确定结果之后,SELECT用来对结果col简单筛选或计算,决定输出什么数据.
6. DISTINCT
如果数据行有重复DISTINCT 将负责排重.
7. ORDER BY
在结果集确定的情况下,ORDER BY 对结果做排序。因为SELECT中的表达式已经执行完了。此时可以用AS别名.
8. LIMIT / OFFSET
最后 LIMIT 和 OFFSET 从排序的结果中截取部分数据.
结论
不是每一个SQL语句都要用到所有的句法,但灵活运用以上的句法组合和深刻理解SQL执行原理将能在SQL层面更好的解决数据问题,而不用把问题 都抛给程序逻辑.
练习 do it — 请完成如下任务
【复习】统计出每一个导演的电影数量(列出导演名字和数量) ✓
【复习】统计一下每个导演的销售总额(列出导演名字和销售总额)
【难题】按导演分组计算销售总额,求出平均销售额冠军(统计结果过滤掉只有单部电影的导演,列出导演名,总销量,电影数量,平均销量)
【变态难】找出每部电影和单部电影销售冠军之间的销售差,列出电影名,销售额差额


















 419
419

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









