




- 前言
现在我们来讲讲kettle如何整合hive进行操作
- 准备环境
开启hiveserver2服务
cd /export/servers/hive-1.1.0-cdh5.14.0 nohup bin/hive --service hiveserver2 &
连接hive
hive
创建并切换数据库
create database test;
use test;
创建表
create table a(a int,b int) row format delimited fields terminated by ',' stored as TEXTFILE; show tables;
创建数据文件
vim a.txt
1,11
2,22
3,33
从文件加载数据到表
load data local inpath '/root/a.txt' into table a;
查询表
select * from a;
修改权限,因为下面有些操作需要权限
hadoop fs -chmod -R 777 /tmp/hadoop-yarn
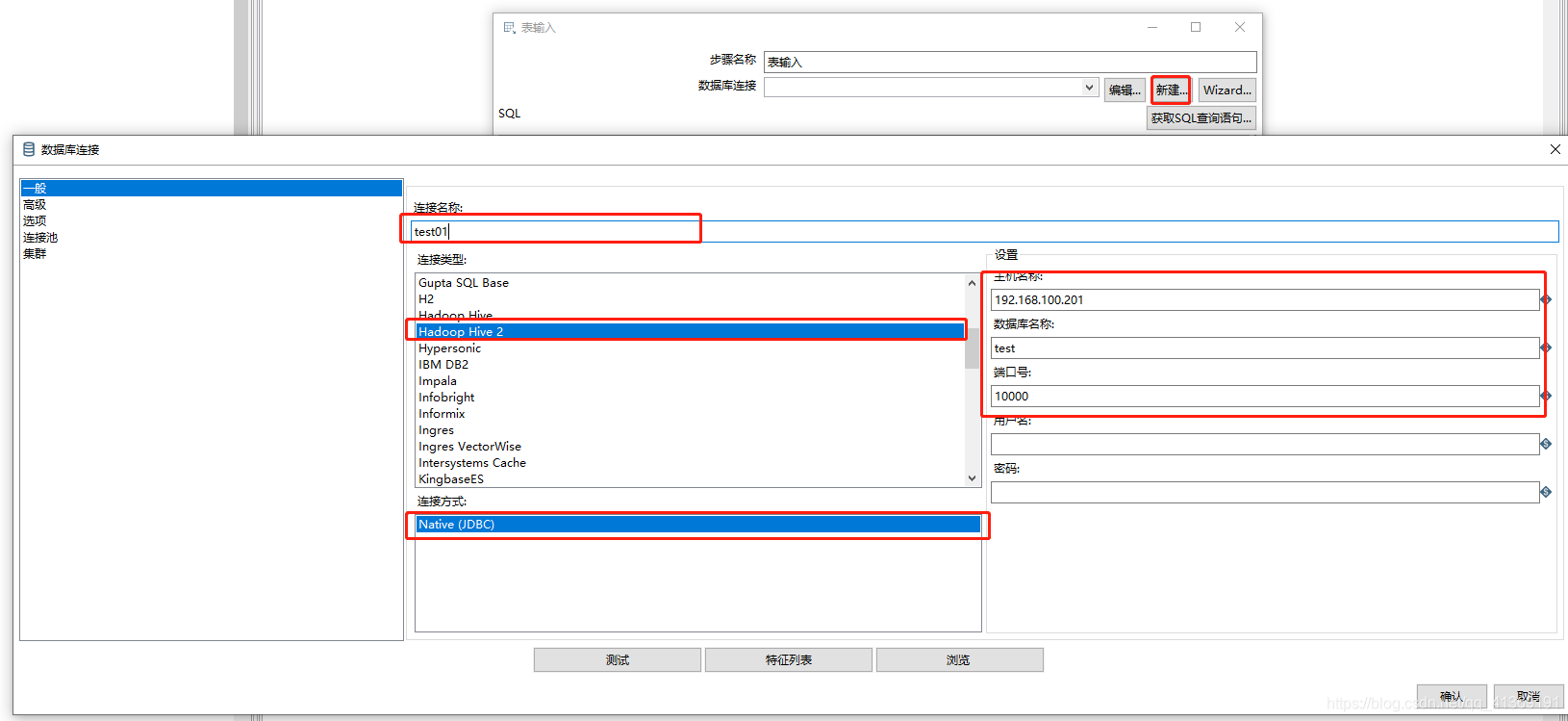
- kettle与Hive整合
从虚拟机下载Hadoop的jar包
sz /export/servers/hadoop-2.6.0-cdh5.14.0/share/hadoop/common/hadoop-common-2.6.0-cdh5.14.0.jar
把jar包放置在\data-integration\lib目录下
重启kettle,重新加载生效
- 从hive中读取数据到Excel
hive数据库是通过jdbc来进行连接,可以通过表输入控件来获取数据,从hive数据库的test库的a表中获取数据,并把数据保存到Excel中。
拖拽一个表输入组件、一个Excel输出组件、并按住Shift拖动鼠标连接两个组件
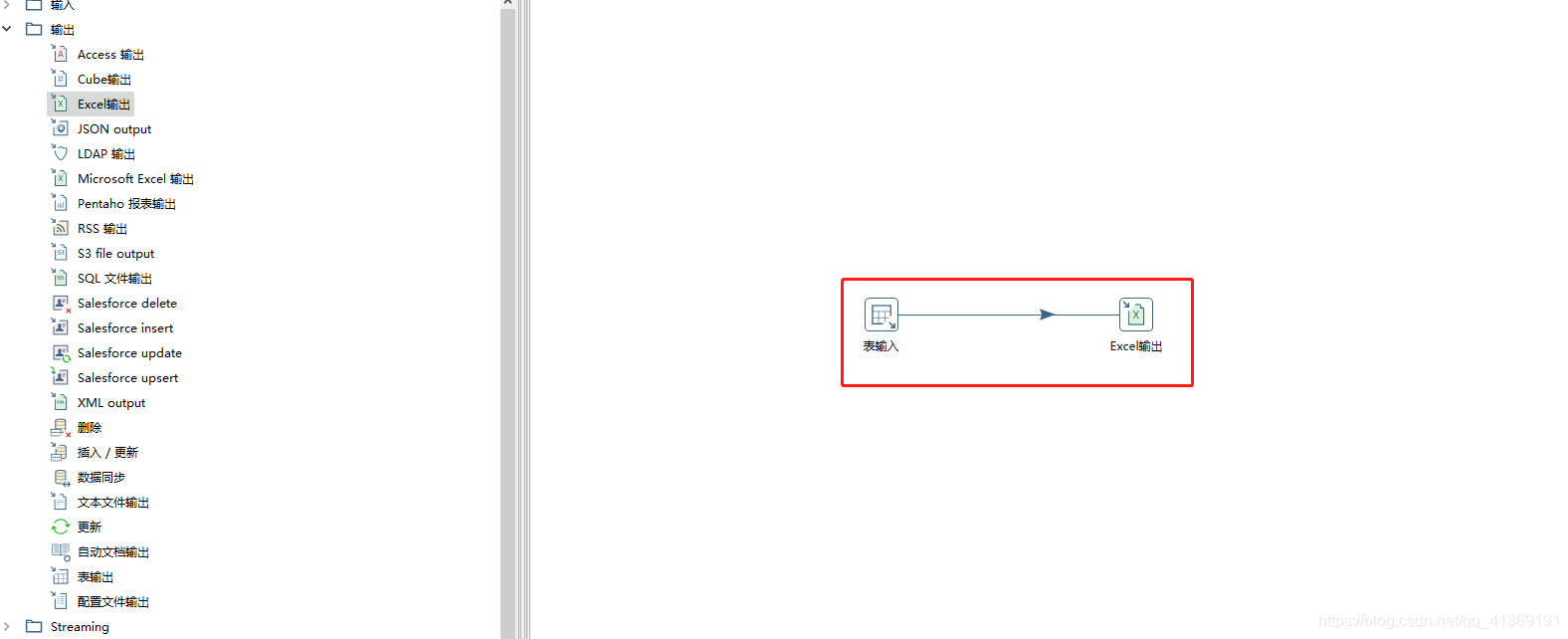
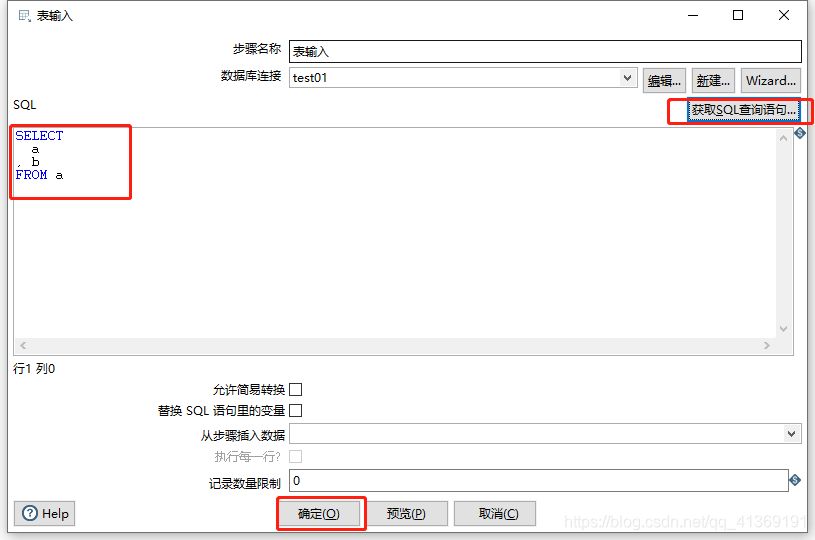
配置表输入组件
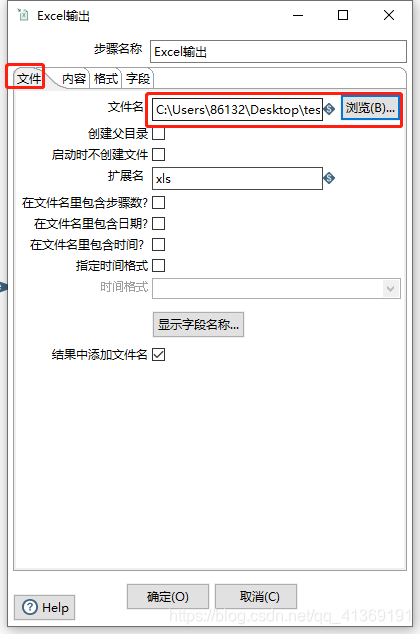
配置Excel输出组件
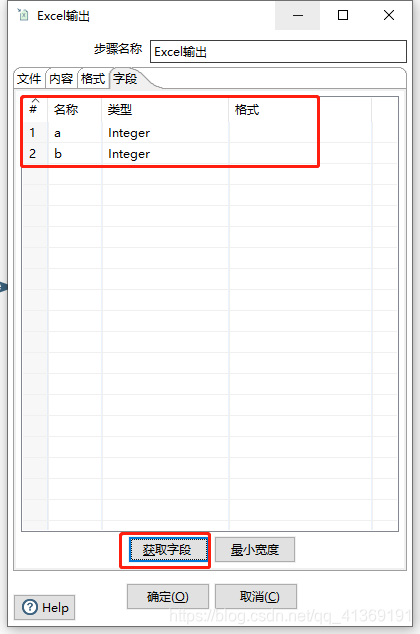
点击三角形箭头执行
- 从Excel中读取数据到hive
拖拽一个Excel输入组件、一个表输出组件、并按住Shift拖动鼠标连接两个组件

配置Excel输入组件
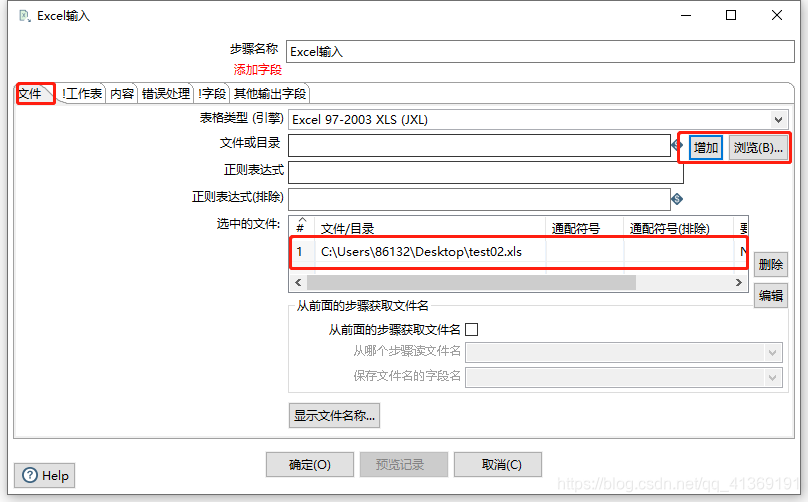
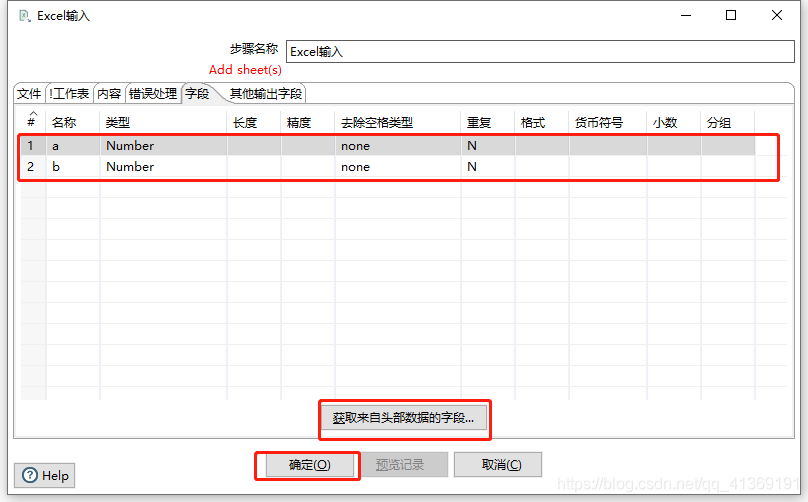
配置表输出组件
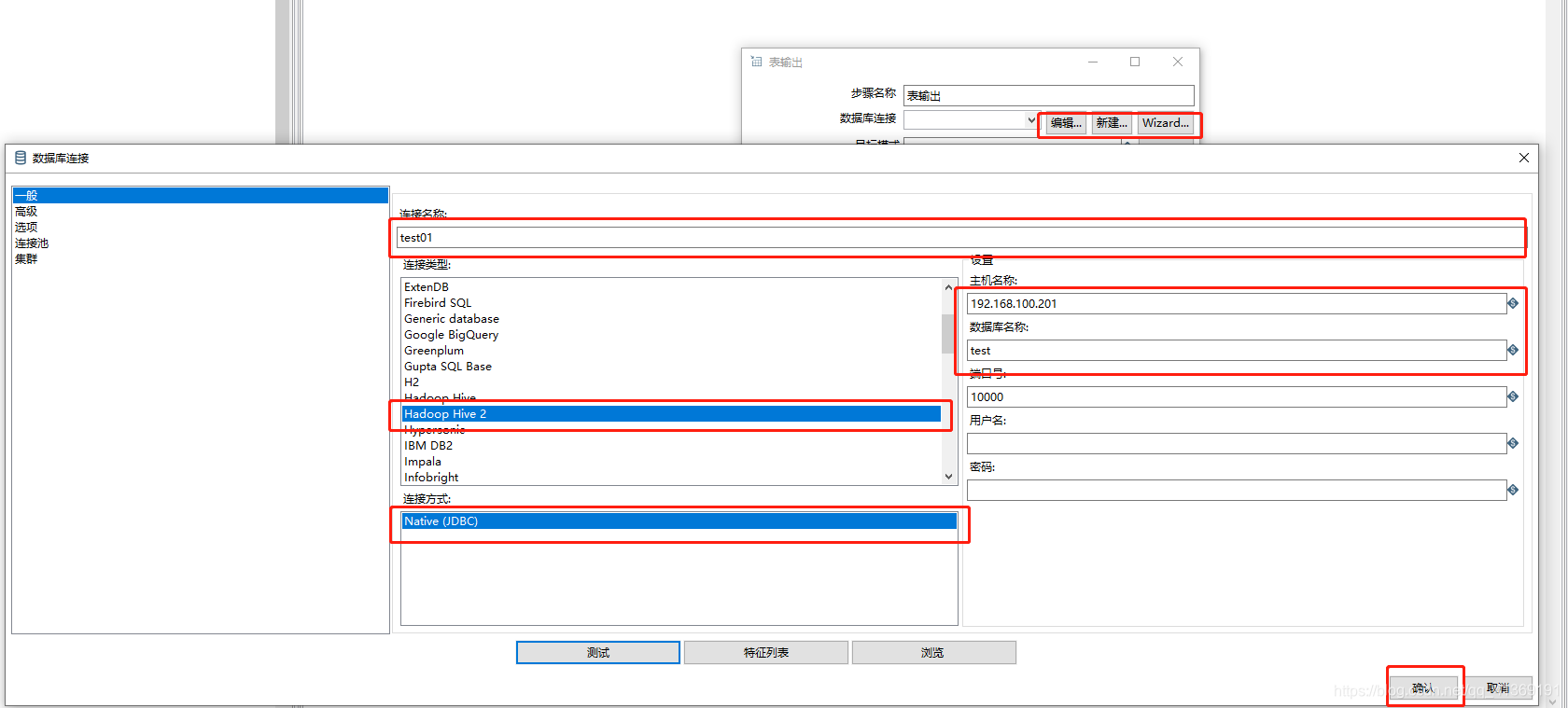
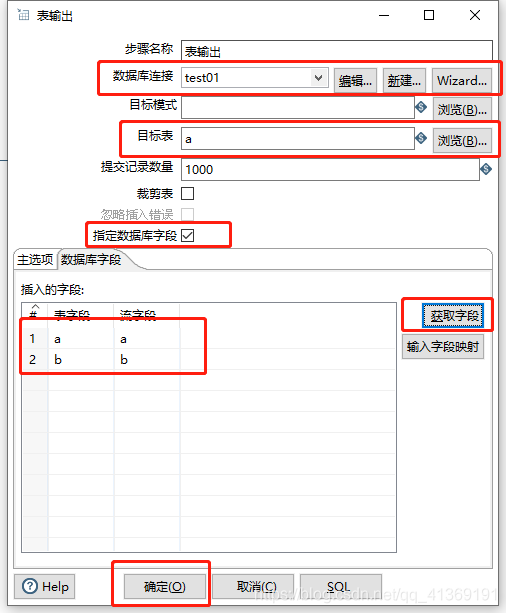
点击三角形箭头执行

















 3151
3151

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









