




 R-FCN是一种针对Faster R-CNN的优化,旨在提高目标检测的速度。Faster R-CNN的耗时在于每个ROI区域都需要通过全连接层,而R-FCN提出位置敏感得分图的概念,将全连接层前移并结合ROI池化,减少了计算量。通过位置敏感ROI池化,保留空间信息的同时实现了加速。文章还介绍了如何通过位置敏感得分图进行目标定位和分类,从而实现高效的检测流程。
R-FCN是一种针对Faster R-CNN的优化,旨在提高目标检测的速度。Faster R-CNN的耗时在于每个ROI区域都需要通过全连接层,而R-FCN提出位置敏感得分图的概念,将全连接层前移并结合ROI池化,减少了计算量。通过位置敏感ROI池化,保留空间信息的同时实现了加速。文章还介绍了如何通过位置敏感得分图进行目标定位和分类,从而实现高效的检测流程。
R-FCN,全称为“Region-based fully convolutional network”,该文章的发表时间可以参见下图:
R-FCN关注点并不是检测精度,而是检测速度。可以参见下面的图来理解这个问题:
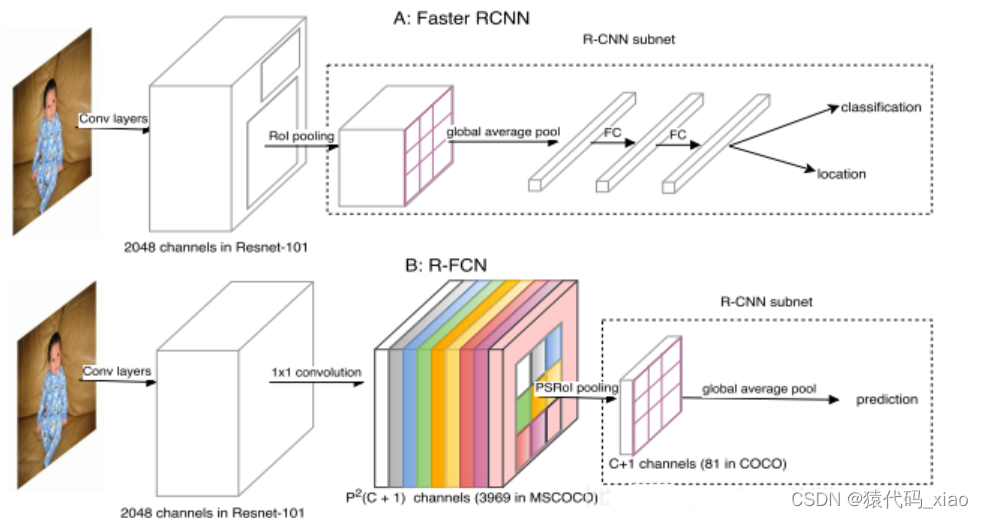
由图可见,Faster RCNN对每一个Roi区域,分别经过一个subnetwork,这个subnetwork包含了一次global average pool操作,两次FC操作。因为每一个Roi的计算并没有共享,所以这种网络结构是比较耗时的。
为了解决这个问题,比较直接的想法是,把这两层FC操作放到Roi pooling前面,这样的话,每一个Roi区域只需要经过global average pool操作即可,节约了计算量。但是,这样做带来了另外一个问题,由于global average pool操作得到的特征缺失了很多的空间域信息,如果直接用来回归坐标会导致定位精度不准。为了保留更多的空间域位置信息,R-FCN中提出了“position-sensitive score map”的概念。
假设我们只有一个特征图用来检测右眼。那么我们可以使用它定位人脸吗?应该可以。因为右眼应该在人脸图像的左上角,所以我们可以利用这一点定位整个人脸。

如果我们还有其他用来检测左眼、鼻子或嘴巴的特征图,那么我们可以将检测结果结合起来,更好地定位人脸。
现在我们回顾一下所有问题。在 Faster R-CNN 中,检测器使用了多个全连接层进行预测。如果有 2000 个
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1389
1389

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









