



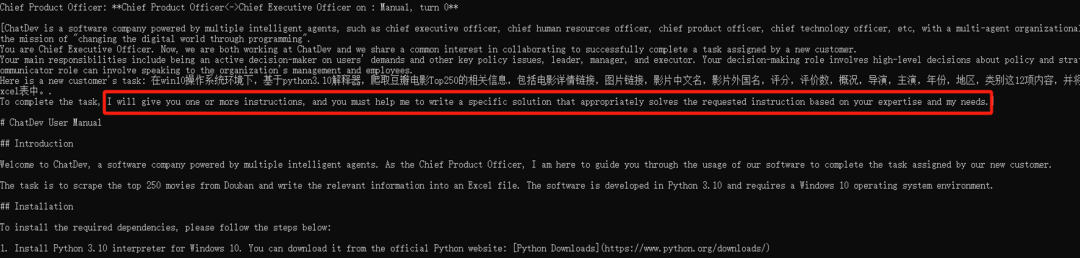
 文章讲述了作者使用Python在Windows环境中爬取豆瓣电影Top250信息的过程,涉及模型选择、爬虫设计、编码、测试和文档编写。遇到反爬问题后,通过调整请求头并改进URL拼接解决了问题。同时提到了ChatDev的GUI设计和局限性。
文章讲述了作者使用Python在Windows环境中爬取豆瓣电影Top250信息的过程,涉及模型选择、爬虫设计、编码、测试和文档编写。遇到反爬问题后,通过调整请求头并改进URL拼接解决了问题。同时提到了ChatDev的GUI设计和局限性。
写在前面
本优快云账号号专注于Python程序开发、数据分析、特征工程、机器学习、深度学习、人工智能等技术栈,涵盖数据科学、计算机视觉、自然语言处理等技术领域。
1、模型选择:GPT4
2、需求: 在win10操作系统环境下,基于python3.10解释器,爬取豆瓣电影Top250的相关信息,包括电影详情链接,图片链接,影片中文名,影片外国名,评分,评价数,概况,导演,主演,年份,地区,类别这12项内容,并将爬取的信息写入Excel表中。
(1)设计阶段:
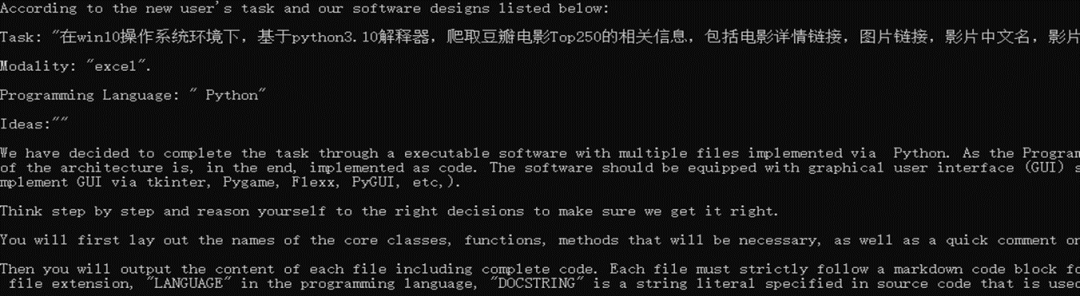
(2)编码阶段:
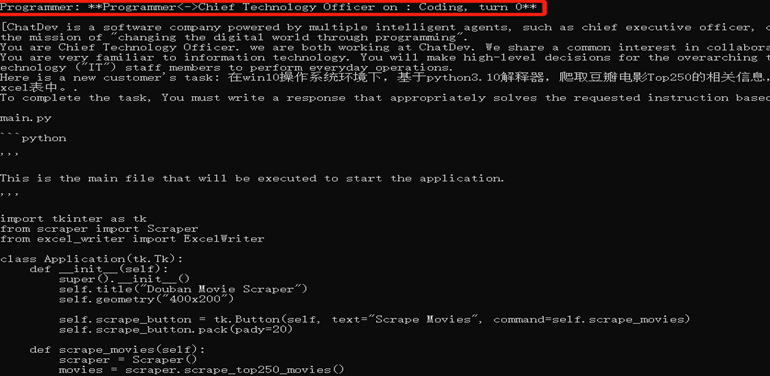
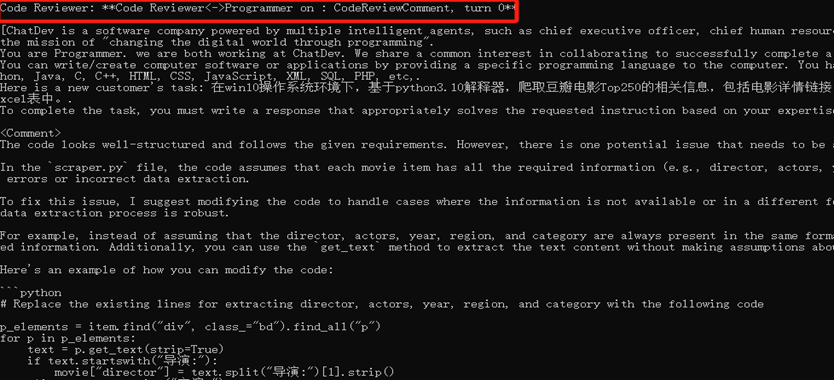
(3)测试阶段:
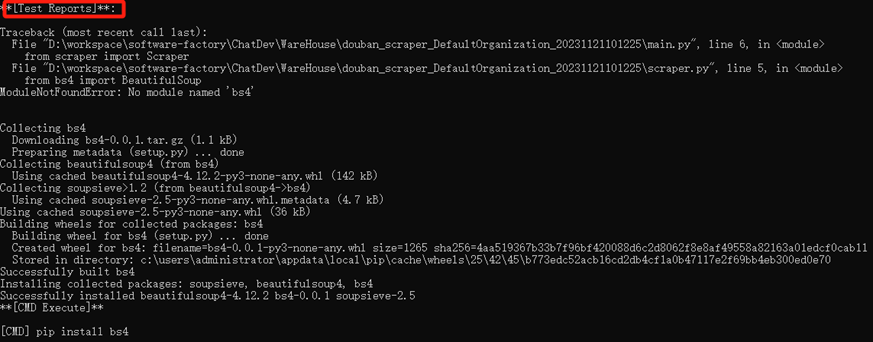
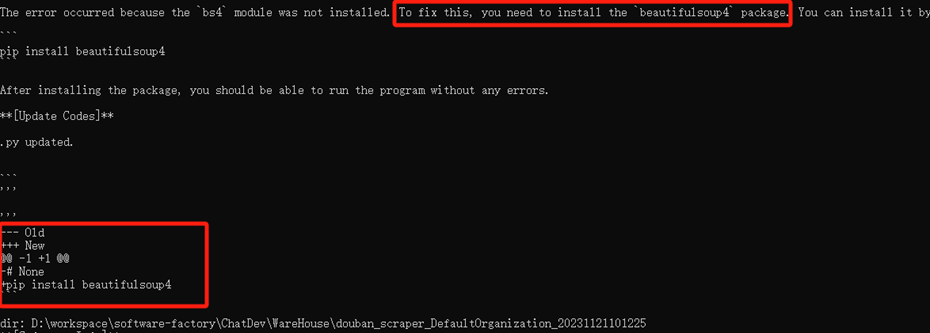
(4)文档阶段:
3、结果
运行main.py报错

4、原因分析
找下一页链接时解析出现错误
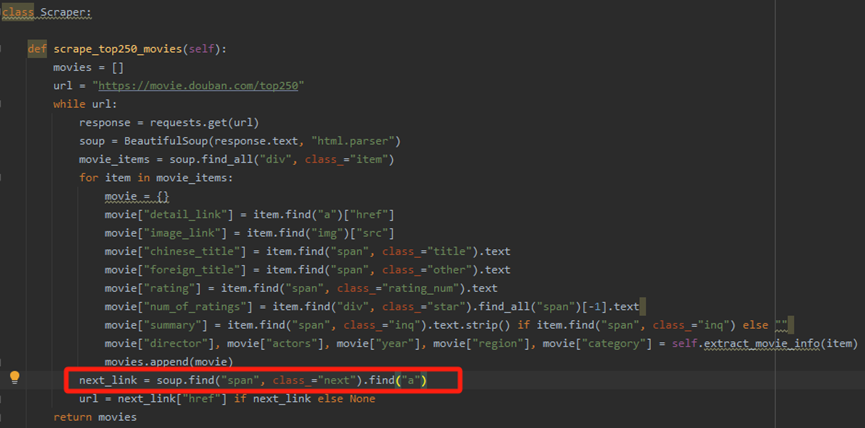
通过检查网页元素,发现这个解析应该没有问题,所以应该是更深层次的问题,发现网页请求并没有收到响应,应该是生成的代码没有添加请求头信息。对此我在request中增加了请求头参数
response = requests.get(url, headers=headers)
接着报错:

查看了一下代码
url = next_link["href"] if next_link else None
这句代码返回的url是"?start=25&filter="显然不是合理的下一页的url,需要一个基础url和解析得到的url进行拼接,我对此进行优化:
base_url = "https://movie.douban.com/top250"
url = base_url + next_link["href"] if url else None
程序可以运行,除了反爬的原因,得到如下结果

显然,最后几个字段信息全部在Director中,对这个信息的提取出现问题。我重新编写解析的代码,最终程序运行

5、总结
(1)ChatDev偏向GUI设计,它将我的需求用GUI形式展示了,运行主程序首先会弹出一个GUI。然后点击按钮运行整个程序。
(2)ChatDev有一个测试过程,更能够确保程序运行不报错,但是无法保证最终的是否返回结果,或者结果是否是用户所需要的。
(3)程序中的一些参数设置需要人工配置,比如发出网页请求,需要加入请求头部信息,否则无法返回网页信息,也就无法解析内容返回结果,而请求头信息是需要用户提供的。
(4)用户提出需求之后,无法参与到软件开发的过程中,无法参与反馈。
写在后面
免费电子书籍,带你入门人工智能:

感兴趣的小伙伴,赠送全套Python学习资料,包含面试题、简历资料等具体看下方。

一、Python所有方向的学习路线
Python所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照下面的知识点去找对应的学习资源,保证自己学得较为全面。


二、Python必备开发工具
工具都帮大家整理好了,安装就可直接上手!
三、最新Python学习笔记
当我学到一定基础,有自己的理解能力的时候,会去阅读一些前辈整理的书籍或者手写的笔记资料,这些笔记详细记载了他们对一些技术点的理解,这些理解是比较独到,可以学到不一样的思路。

四、Python视频合集
观看全面零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。

五、实战案例
纸上得来终觉浅,要学会跟着视频一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

六、面试宝典


简历模板
若有侵权,请联系删除

















 568
568

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









