



背景
最近在学爬虫技术,顺便记录一下学习的过程,供各位小伙伴参考。
网络爬虫又称网络蜘蛛、网络机器人,它是一种按照一定的规则自动浏览、检索网页信息的程序或者脚本。网络爬虫能够自动请求网页,并将所需要的数据抓取下来。通过对抓取的数据进行处理,从而提取出有价值的信息。
第一个Python爬虫程序
本节编写一个最简单的爬虫程序,作为学习 Python 爬虫系列前的开胃小菜。
在使用 Python 编写爬虫程序之前,您需要提前做一些准备工作,这样在后续学习过程中才会得心应手。
知识准备
1) Python语言
Python 爬虫作为 Python 编程的进阶知识,要求学习者具备较好的 Python 编程基础。没基础的小伙伴,可以看看本公众号之前发的几篇入门文章。
同时,了解 Python 语言的多进程与多线程,并熟悉正则表达式语法,也有助于您编写爬虫程序。
注意:关于正则表达式,Python 提供了专门的 re 模块。
2) Web前端
了解 Web 前端的基本知识,比如 HTML、CSS、JavaScript,这能够帮助你分析网页结构,提炼出有效信息。
3) HTTP协议
掌握 OSI 七层网络模型,了解 TCP/IP 协议、HTTP 协议,这些知识将帮助您了解网络请求(GET 请求、POST 请求)和网络传输的基本原理。同时,也有助您了解爬虫程序的编写逻辑。
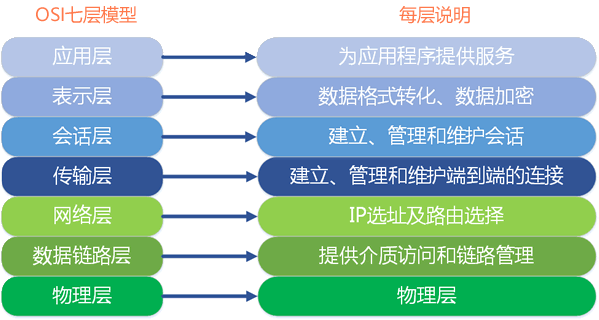
osi七层模型
图1:OSI 网络七层模型
环境准备
编写 Python 爬虫程序前,需要准备相应的开发环境,这非常的简单。首先您需要在您的电脑上安装 Python,然后下载安装 Pycharm IDE(集成开发环境)工具。
本教程使用 Windows 10 系统进行 Python 爬虫的讲解,当然您也可以使用其他系统,比如 Linux 或者 Mac。
下面使用 Python 内置的 urllib 库获取网页的 html 信息。注意,urllib 库属于 Python 的标准库模块,无须单独安装,它是 Python 爬虫的常用模块。
获取网页html信息
1) 获取响应对象
向百度(http://www.baidu.com/)发起请求,获取百度首页的 HTML 信息,代码如下:
#导包,发起请求使用urllib库的request请求模块
import urllib.request
# urlopen()向URL发请求,返回响应对象,注意url必须完整
response=urllib.request.urlopen('http://www.baidu.com/')
print(response)
上述代码会返回百度首页的响应对象, 其中 urlopen() 表示打开一个网页地址。注意:请求的 url 必须带有 http 或者 https 传输协议。
输出结果,如下所示:
<http.client.HTTPResponse object at 0x032F0F90>
上述代码也有另外一种导包方式,也就是使用 from,代码如下所示:
#发起请求使用urllib库的request请求模块
from urllib import request
response=request.urlopen('http://www.baidu.com/')
print(response)
2) 输出HTML信息
在上述代码的基础上继续编写如下代码:
import urllib.request
# urlopen()向URL发请求,返回响应对象
response=urllib.request.urlopen('http://www.baidu.com/')
#提取响应内容
html = response.read().decode('utf-8')
#打印响应内容
print(html)
输出结果如下,由于篇幅过长,此处只做了简单显示:
<!DOCTYPE html><!--STATUS OK--> <html><head><meta http-equiv="Content-Type" content="text/html;charset=utf-8"><meta http-equiv="X-UA-Compatible" content="IE=edge,chrome=1"><meta content="always" name="referrer"><meta name="theme-color" content="#2932e1"><meta name="description" content="全球最大的中文搜索引擎、致力于让网民更便捷地获取信息,找到...">...</html>
通过调用 response 响应对象的 read() 方法提取 HTML 信息,该方法返回的结果是字节串类型(bytes),因此需要使用 decode() 转换为字符串。程序完整的代码程序如下:
import urllib.request
# urlopen()向URL发请求,返回响应对象
response=urllib.request.urlopen('http://www.baidu.com/')
# 提取响应内容
html = response.read().decode('utf-8')
# 打印响应内容
print(html)
通过上述代码获取了百度首页的 html 信息,这是最简单、最初级的爬虫程序。后续我们还学习如何分析网页结构、解析网页数据,以及存储数据等。
常用方法
在本节您认识了第一个爬虫库 urllib,下面关于 urllib 做简单总结。
1) urlopen()
表示向网站发起请求并获取响应对象,如下所示:
urllib.request.urlopen(url,timeout)
urlopen() 有两个参数,说明如下:
-
• url:表示要爬取数据的 url 地址。
-
• timeout:设置等待超时时间,指定时间内未得到响应则抛出超时异常。
2) Request()
该方法用于创建请求对象、包装请求头,比如重构 User-Agent(即用户代理,指用户使用的浏览器)使程序更像人类的请求,而非机器。重构 User-Agent 是爬虫和反爬虫斗争的第一步。在下一节会做详细介绍。
urllib.request.Request(url,headers)
参数说明如下:
-
• url:请求的URL地址。
-
• headers:重构请求头。
3) html响应对象方法
bytes = response.read() # read()返回结果为 bytes 数据类型
string = response.read().decode() # decode()将字节串转换为 string 类型
url = response.geturl() # 返回响应对象的URL地址
code = response.getcode() # 返回请求时的HTTP响应码
4) 编码解码操作
#字符串转换为字节码
string.encode("utf-8")
#字节码转换为字符串
bytes.decode("utf-8")
我有个大胆的想法
小伙伴在平常有没有遇到以下这种情况:遇到技术难题时,网上教程一堆堆,优秀的很多,但也有很多是过时的,或者是copy来copy去,甚至错别字都没改。
感兴趣的小伙伴,赠送全套Python学习资料,具体看下方。

一、Python所有方向的学习路线
Python所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照下面的知识点去找对应的学习资源,保证自己学得较为全面。


二、Python必备开发工具
工具都帮大家整理好了,安装就可直接上手!
三、最新Python学习笔记
当我学到一定基础,有自己的理解能力的时候,会去阅读一些前辈整理的书籍或者手写的笔记资料,这些笔记详细记载了他们对一些技术点的理解,这些理解是比较独到,可以学到不一样的思路。

四、Python视频合集
观看全面零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。

五、实战案例
纸上得来终觉浅,要学会跟着视频一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

六、面试宝典


简历模板
若有侵权,请联系删除


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









