






 文章讨论了并发设计中的进程与线程选择,包括多进程和多线程的优缺点。多进程提供了更好的鲁棒性,但可能导致效率和可扩展性的下降;多线程则在创建和切换成本上较低,能提升性能,但可能降低鲁棒性。此外,文章提到了线程模型(用户线程,内核线程和混合线程模型),调度类(时间共享和实时调度)以及任务和消息基础架构对性能的影响。最后,文章指出,选择应基于应用需求,如资源管理,实时性要求和性能优化。
文章讨论了并发设计中的进程与线程选择,包括多进程和多线程的优缺点。多进程提供了更好的鲁棒性,但可能导致效率和可扩展性的下降;多线程则在创建和切换成本上较低,能提升性能,但可能降低鲁棒性。此外,文章提到了线程模型(用户线程,内核线程和混合线程模型),调度类(时间共享和实时调度)以及任务和消息基础架构对性能的影响。最后,文章指出,选择应基于应用需求,如资源管理,实时性要求和性能优化。
Chapter 5. Concurrency Design Dimensions
5.2 Processes versus Threads
Section 5.1 描述了并行服务器的好处,它可以使用多线程或多进程实现。这一维度主要的权衡涉及鲁棒性,效率,和可拓展性。
Multiprocessing。 进程是一个 OS 实体,它提供上下文用于执行程序指令。进程管理某些资源,例如虚拟内存,I/O handles,和 signal handles,并通过 memory management unit (MMU) 硬件避免受到其他进程的影响。由 UNIX 上的 fork() 或 Win32 上的 CreateProcess() 创建的进程同时执行在与调用方不同的地址空间中。这些机制将在 Chapter 8 中详细展开。
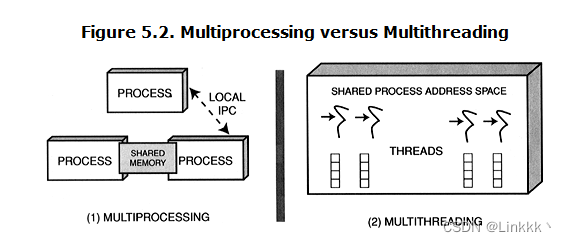
早期出现的操作系统,例如 BSD UNIX,提供仅有一条控制线程的进程。这种单线程进程模型能提高鲁棒性,因为如果没有程序员的显式干预,进程间不会彼此干扰。例如,进程仅能通过共享内存和本地 IPC 机制彼此合作,如图 5.2 所示。
然而,单线程进程很难用来开发某些特定类型的应用,特别是高性能或实时服务器。需要彼此间相互通讯或负责管理请求的服务器必须使用某种形式的 IPC,这增加了它们的复杂性。同样也很难在多进程下实施高效率,细粒度的调度和进程优先级的控制。
Multithreading。 为了缓和上述提到的关于进程的问题,大部分 OS 平台现在支持一个进程中有多个线程。线程是一个指令序列,在进程保护域的上下文中按步执行,如图 5.2 (2) 所示。除了指令指针,线程还管理某些其他资源,例如运行时函数栈,一组寄存器,信号掩码,优先级,和线程特定的数据。如果有多个 CPU 可用,多线程服务器中的服务能并行执行。在很多版本的 UNIX 中,线程由 pthread_create() 产生,在 Win32 中由 CreateThread() 产生。
- Thread creation and context switching。 因为线程较进程维护的状态更少,线程创建和上下文切换较进程的开销也更低。例如,进程范围内资源,比如虚拟地址映射和缓存,当进程内的线程间进行切换时,不需要改变。
- Synchronization。 当调度和执行一个应用线程时,内核模式和用户模式间的切换可能是不必要的。同样,线程内同步通常比进程间同步的成本更低,因为被同步的对象对进程来说是局部的,因此可能不需要内核干预 (用户空间的线程实现?)。相反,进程间线程同步通常涉及 OS 内核。
- Data copying。 线程能使用进程局部内存共享信息,它有下列好处:
- 较使用共享内存或局部 IPC 机制进行进程间通讯更有效率,因为数据不需要通过内核进行拷贝。
- 在进程局部内存中使用 C++ 对象更简单,因为类虚表的布局在进程局部内存中没有问题。
例如,引用存在于进程局部内存的通用数据类型的合作数据库服务,如果使用多线程实现的话,较使用多进程要更简单更有效率。
作为这些优化的结果,多线程通常能显著提升应用的性能。例如,I/O 绑定的应用能从多线程中获益,因为计算密集的服务能与磁盘和网络操作重叠。然而,OS 平台支持多线程,不意味着所有的应用都应该是多线程的。当使用多线程实现并行应用时,有以下限制:
- Performance degradation。 一个常见的错误概念是线程固有地提升应用性能。然而,很多情况下线程不会提升性能,因为:
- 单处理器上计算边界的应用不会从多线程中获益,因为计算和通讯不能并行进行。
- 细粒度的锁定策略可能产生高的同步开销,阻止应用从并行处理中完全获益。
- Reduce robustness。 为了减少上下文切换和同步的开销,线程彼此间很少或没有 MMU 保护。通过单个进程地址空间内的线程执行所有任务可能减少应用的鲁棒性,因为:
- 相同地址空间内的几个线程彼此间没有很好的保护。进程中的一个服务故障可能会破坏运行于进程中其他线程上的服务共享的全局数据。反过来,这可能产生不正常的结果,使整个进程崩溃,或者造成应用无限挂起。
- 在一个线程中调用的某个 OS 函数可能会对整个进程造成不良的边界效应;例如,UNIX
exit()和 Win32ExitProcess()函数就有终止进程中所有线程的边际效应。
- Lack of fine-grained access control。 在大多数操作系统中,进程是访问控制的粒度。因此,多线程的另一个限制是一个进程中的所有线程共享相同的用户 ID 和对文件及其他被保护的资源的访问特权。为了阻止对未授权资源的意外或故意的访问,其安全机制基于进程所有权的网络服务,例如 TELNET,通常运行在单个进程中。
5.3 Process/Thread Spawning Strategies
生成线程和进程有几种策略。在不同的场景下使用不同的策略来优化并行服务器的性能,借此使开发者能调整服务器的并行级别以匹配客户端需求和可用的 OS 处理资源。正如下述,不同的策略以资源耗费的增加交换启动开销的降低。
Eager spawning。 这一策略在服务器创建期间预生成一个或多个 OS 进程或线程。这些 “warm-started” 执行资源形成一个 pool,通过增加服务启动的开销来提升响应速度。这个 pool 可以被静态或动态地拓展或收缩,取决于不同的因素,例如可用的 CPU 数量,当前机器负载,或者客户端请求队列的长度。图 5.3 (1) 描述了一个线程的 eager spawning 策略。这一设计使用 Half-Sync/Half-Async 模式,它将来自 I/O 层的请求喂给线程池中的 worker。
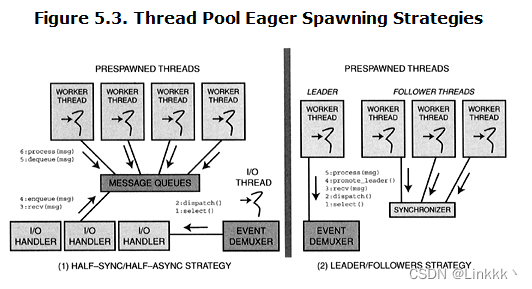
另一个可选的 eager spawning 策略是使用 Leader/Followers 模式管理线程池,正如图 5.3(2) 所示。这一模式定义了一个高效并行模型,多个线程轮流共享一组事件源来检测,解多路复用,分发,和处理事件源上出现的服务请求。当对池中的线程来说,对请求的处理没有同步或顺序的约束,Leader/Followers 模式能被用于替代 Half-Sync/Half-Async 模式以提升性能。
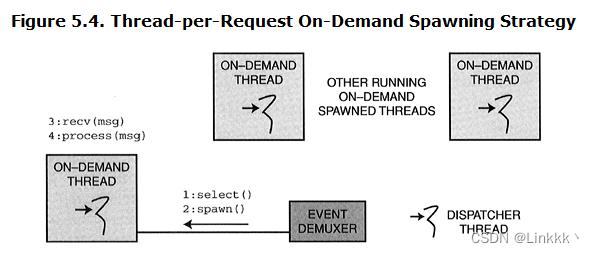
On-demand spawning 创建一个新的线程或进程以响应到达的客户端连接和/或数据请求,如同 Section 5.1 图 5.4 所示的每个请求一个线程或每个连接一个线程。on-demand spawning 策略的主要好处是减少了资源的消耗。然而,其缺点是这些策略会降低高负载的服务器上性能和实时系统的确定性,因为当生成进程/线程和开始服务时开销增加了。
5.4 User,Kernel,and Hybrid Threading Models
调度是 OS 提供地用于保证应用合理地使用主机 CPU 资源的主要机制。在多线程进程中,线程是调度和执行的单元。现代 OS 平台提供不同的模型来调度应用创建的线程。模型间关键的不同点是线程竞争系统资源的 contentsion scope。
Process contention scope, 相同进程中的线程彼此竞争调度的 CPU 时间,不直接与其他进程中的线程竞争。System contention scope, 线程直接与其他的系统范围内的线程竞争,无论其他线程关联什么进程。
目前常用的操作系统中实现了三种调度模型:
N : 1 用户线程模型1 : 1 内核线程模型N : M 混合线程模型
The N : 1 user-threading model. 早期的线程实现都在原生的进程控制机制之上,在用户空间由库处理。OS 内核因此对线程一无所知。内核调度进程,库管理一个进程中的 n 个线程,如图 5.5 (1) 所示。因此,这一模型被称为 “N : 1” 用户线程模型,线程被称为 “用户空间线程” 或 “用户线程”。在 N : 1 线程模型中,所有的线程运行于进程竞争范围。
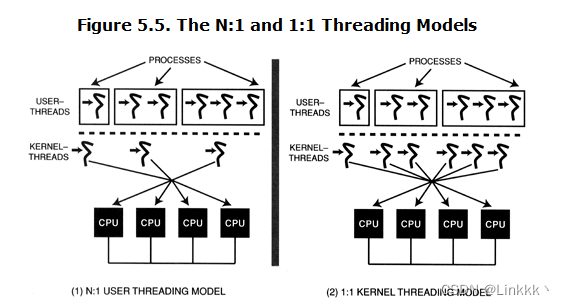
在 N : 1 线程模型中,同一进程内任何线程生命周期事件或上下文切换与内核无关。线程的创建,删除,和上下文切换因此具有很高的效率。具有讽刺意味的是,N : 1 模型的两个主要的问题也是源自内核对线程的无知:
- 不管主机 CPUs 的数量,每个进程每次仅在一个 CPU 上调度。进程中的所有线程都在争夺该 CPU,共享内核在进程调度中分配的时间片。
- 如果一个线程发起阻塞操作,例如,read() 或 write() 某文件,所有在该进程中的线程都会阻塞,直到该操作完成。很多 N : 1 实现,最著名的是 DCE 线程,提供 OS 系统函数的封装以减轻这一限制 (在调用系统调用进入内核空间前,先询问该操作是否会阻塞,如使用 select(),如果会阻塞则不进行调用)。然而,这些封装不是完全透明的,它们对你的程序行为有所约束。因此,你必须意识到它们以避免对你的应用产生不好的影响。
The 1 : 1 kernel-threading model. 大部分的现代 OS 内核对线程提供直接的支持。在 “1 : 1” 内核线程模型中,每个应用创建的线程都直接通过一个内核线程处理。OS 内核在系统的 CPUs 上调度每个内核线程,如图 5.5(2) 所示。因此,在 “1 : 1” 模型中,所有的线程运行于系统竞争范围。
1 : 1 模型修复了 N : 1 模型中的两个问题:
- 多线程应用能利用多个 CPUs。
如果内核在一个系统函数中阻塞线程,其他线程可以继续工作。
因为线程的创建和调度涉及 OS 内核,线程生命周期操作较 N : 1 模型开销更高,虽然较进程生命周期操作通常更低。
The N:M hybrid-threading model. 一些操作系统,提供 N : 1 模型和 1 : 1 模型的结合,被称为 “N : M” 混合线程模型。该模型支持用户线程和内核线程的混合。混合模型如图 5.6 所示。当应用生成一条线程时,能指定该线程应该运行于哪个竞争作用域。OS 线程库创建一个用户空间线程,但是如果需要的话仅创建一个内核线程,或着如果应用显式请求系统竞争范围。如同在 1 : 1 模型中,OS 内核在 CPUs 上调度内核线程。如同在 N : 1 模型中,OS 线程库将用户空间线程调度到所谓的 "lightweight processes" (LWPs) 上,LWPs 1 对 1 的映射到内核线程上。
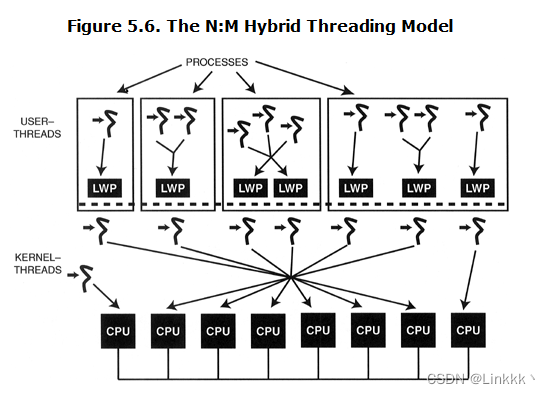
当多个用户空间的线程中的某一个调用一个阻塞的系统函数,这些用户空间的线程都会被阻塞。当 OS 内核阻塞一个 LWP,所有通过线程库在其上调度的用户线程都会阻塞,虽然同一进程中的其他 LWPs 上调度的线程能继续运行。Solaris 内核通过下述基于调度器激活概念的方法解决这一问题:
- OS 线程库维护它用于运行所有进程范围内的用户线程的 LWPs 池。必要的话,它可以重新调度这些在池中的 LWPs 上的线程。池的大小可以通过 Pthreads
pthread_setconcurrency函数调整。 - 当 OS 内核注意到进程中的所有内核线程都被阻塞了,它发送一个 SIGWAITING 信号来影响进程。线程库捕获到这一信号,然后启动一个新的 LWP。随后可以在新的 LWP 上重新调度进程范围内的线程,允许应用继续运行。
不是所有的 OS 平台都允许影响线程如何映射到系统资源,系统资源如何分配的。与其他强大的,特性齐全的工具一样,错误的使用线程可能会造成伤害。所以,当需要在两个竞争范围之间给出一个选择,应该选择哪一个?为什么生成一个线程,生成的线程在多大程度上独立于程序中中其他线程?我们给出下述解答:
-
Spawn thread to avoid interference from other tasks. 一些任务必须在执行时必须最小化进程中其他线程的干预,甚至需要最小化系统中其他线程的干预。比如:
- 线程必须对一些刺激快速做出反应,例如追踪鼠标事件
- CPU-intensive 任务应当与其他任务隔离
- 多处理器系统上的 I/O-intensive 任务
在这些情况下,线程都应该被单独调度,最小化与应用中的其他线程的竞争。为了实现这个目标,使用系统范围内的线程以避免新线程与相同内核线程中的其他线程竞争调度,并允许 OS 利用多个 CPUs。如果你的系统支持 N : M 模型,显式地请求系统竞争范围。如果你的系统提供 1 : 1 模型,那么总是会得到系统范围内的线程。在 N : 1 模型中,就不是这样了。
-
Spawn threads to simplify application design. 为需要的场景节省可用的 OS 资源通常是明智的选择。创建线程的主要动机可能是通过将应用设计解耦为独立的逻辑任务以简化应用设计,例如操作数据并将它传入下一阶段的处理阶段。这种情况下,如果你能使用进程范围内的线程的话,就不需要承担内核线程的成本了, 这常用于 N : 1 系统或在 N : M 模型中请求。进程范围的线程有下述结论:
- 在线程的创建,调度,和同步中避免了额外的内核参与,且仍然分离了应用中的关注点。
- 只要进程范围内的线程的等待状态是由同步引起的,例如在一个互斥量上等待,而非阻塞于系统函数,你的整个进程或内核线程就不会阻塞。
只要你掌握了线程同步模式和 OS 并行机制,线程能帮助你简化你的应用设计。例如,你能从一个或多个线程执行 synchronous I/O,较同步或异步事件处理模式,例如分别为 Reactor 或 Proactor,这能产生更直观的设计。
5.5 Time-shared and Real-Time Scheduling Classes
除了 5.4 节描述的竞争范围和线程模型,OS 平台通常会定义策略和优先级,以进一步对影响调度行为。这些能力使现代操作系统能运行有通用目的和实时调度需求的混合应用。OS 内核能分配线程到不同的调度类中,并使用不同的标准调度这些线程,例如优先级或它们的资源使用率。不同的调度类策略为了增加可预测性和控制而放弃了公平性。它们的描述如下:
Time-shared scheduling class. 通用目的的 OS scheduler ,其目标是传统的 time-sharing,交互的环境。用于这些操作系统的调度器通常是:
- Priority-base,最高优先级的可运行线程是下一个被调度执行的线程。
- Fair,分时调度器中的线程优先级能随它们的 CPU 使用率变化。例如,长期运行的 compute-bound 线程使用更多的 CPU 时间,分时调度器能逐渐地减少它的优先级直到到达一个更低的限制。
- Preemptive,当高优先级的线程可运行时,如果一个低优先级的线程正在执行,调度器应该抢占低优先级的线程并允许高优先级的线程运行。
- Time-sliced,被用于在具有相同优先级的线程中循环。使用这一技术,每个线程运行有限的时间周期 (比如,10 毫秒)。当当前运行的线程的时间片过去后,调度器选择下一个可用的线程,执行上下文切换,并将被抢占的线程放到队列中。
Real-time scheduling class. 虽然分时调度器对适合于传统的网络应用,但它们很少能满足具有实时需求的应用。例如,在分时调度器类中,线程通常没有固定的执行顺序,因为调度器会改变线程的优先级。进一步来说,当高优先级的线程准备好运行时,分时调度器不尝试限制抢占所需的时间的长度。
因此实时操作系统和一些通用目的的操作系统提供一个实时调度类,它限制分发用户线程或内核线程最糟糕的情况下所需的时间。具有实时调度类的 OS 通常支持一个或两个下述的调度策略:
- Round-robin,有一个时间量子指定线程在被另一个具有相同优先级的实时线程抢占前,它能运行的最大时间。
- First-in,first-out (FIFO),最高优先级的线程能运行它选择的时长,直到它主动交出控制权或被一个具有更高优先级的实时线程抢占。
当 OS 同时支持分时和实时调度类,实时线程较分时线程总是以更高的优先级运行。
CPU-bound 的实时程序能接管系统并使其他所有的系统活动中断。因此,大部分通用目的的操作系统会限制对具有超级用户特权的应用的使用实时调度类,以控制这种不期望的情况。
5.6 Task-versus Message-Based Architectures
并发架构绑定:
- CPUs,为应用代码提供执行的上下文。
- Data and control messages,向一个或多个应用和网络设备发送或接收。
- Service processing tasks, 在消息到达和离开时执行服务。
通过影响上下文切换,同步,调度,和数据移动的开销,网络应用的并发架构是最影响网络应用性能的几个因素之一。有两种典型的并发架构:task-based 和 message-based。这一维度的主要权衡涉及编程的简化和性能。
Task-based concurrency architectures 依据应用中的服务功能单元构建多个 CPU。在这一架构中,任务是主动的,由任务处理的消息是被动的,如图 5.7 (1) 所示。并发通过在单独的 CPUs 中执行服务任务,以及在任务/CPUs 间的传递消息实现。基于任务的并发架构能使用生成者/消费者模式实现,例如 Pipes 和 Filters 以及 Active Object。
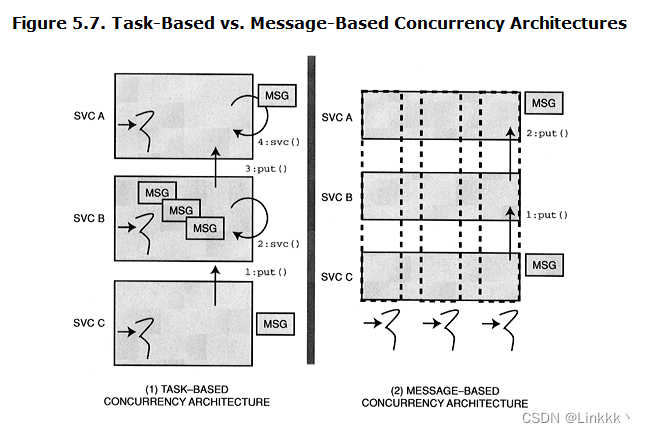
Message-based concurrency architectures 依据从应用或网络设备中接收的消息构建多个 CPUs。在这一架构中,消息是主动的,任务是被动的,如图 5.7 (2) 所示。并发通过引导在独立 CPUs 上的多条消息同时通过服务任务栈。每个线程一个请求,或每个连接一个请求,线程池模型能被用于基于消息的并发架构。
基于消息的架构较基于任务的架构通常更有效率。基于任务的架构通常更易编程,但并发在任务访问点被序列化,例如在协议栈的层之间,带来的任务或层中的同步通常是不必要的。与此相反,基于消息的架构更难以实现,因为需要更精细的并发控制。
5.6.1 Parallel Message-based Process Architectures
5.6.1.1 Introduction
随着超大规模集成电路与光纤技术的发展,性能瓶颈从底层网络转移到了通讯子系统。通讯子系统由协议任务和操作系统机制组成。协议任务包含连接建立和终止,端到端流控制,远程上下文管理,分段/重组,解多路复用,错误保护,会话控制,表示转换。操作系统机制包含进程管理,timer-based 和 I/O-based 事件调用,消息缓冲,和 层到层的流控制。协议任务和操作系统机制一起支持由协议任务组成的通讯协议栈的实现和执行。
在多处理器平台上并行执行协议栈是一种有前景的提高协议处理性能的技术。然而,仅当从并行中获取的加速超过并行处理带来的上下文切换和同步的开销,性能才可能得到明显提高。当执行进程自愿或非自愿的放弃与它相关的处理元素 (PE) 时,上下文切换才会被触发。取决于底层 OS 和硬件平台,上下文切换可能需要几十到几百个指令来冲洗寄存器窗口,内存缓存,指令管道,和翻译后备缓冲器。同步的开销来自于锁定机制,它对协议处理过程中使用的共享对象 (例如消息缓冲,消息队列,协议连接记录,和解多路复用映射) 进行序列化访问。
协议栈 (例如 TCP/IP 协议栈和 ISO OSI 7 层协议栈) 可能使用不同类型的 message-based 进程架构实现。
5.6.1.2 Message-based Process Architecture Examples
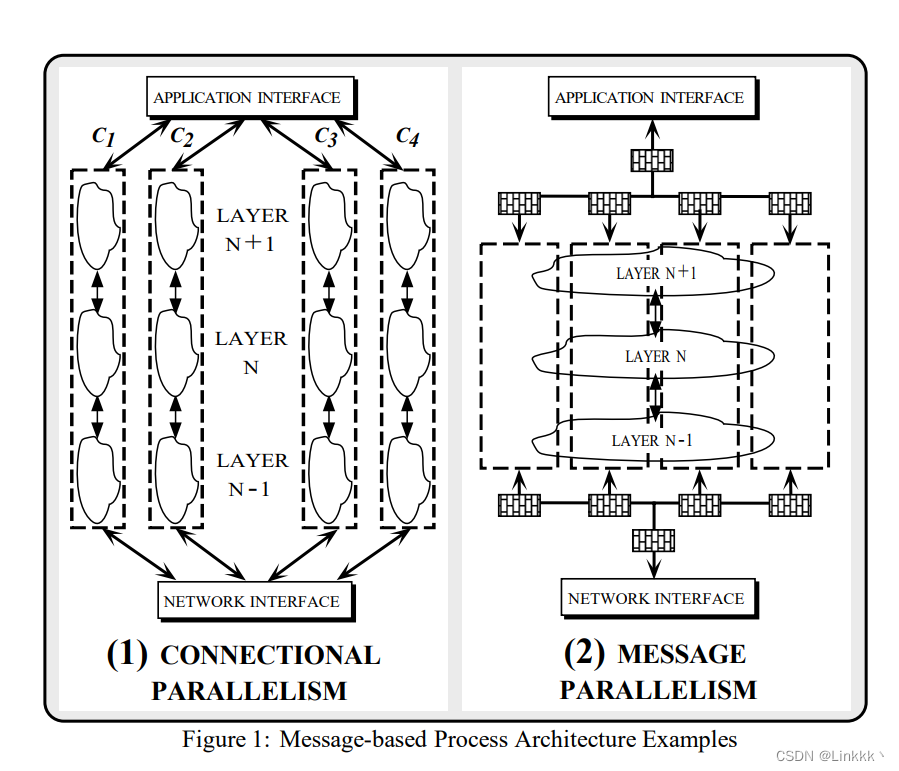
Message-based 进程架构关联进程到消息上,而非到协议层或协议任务。基于消息的进程架构的两个常见例子是 Connectional Parallelism 和 Message Parallelism。这些进程架构中主要的不同点涉及消息被解多路复用到进程的时间点。Connectional Parallelism 解复用所有的绑定到相同连接的消息到相同的进程,而 Message Parallelism 解复用消息到任何可用的进程上。
Connectional Parallelism 使用一个单独的进程来处理关联一个打开的连接的所有消息。如图 1 (1) 所示,连接 C1,C2,C3 和 C4 存在于不同的进程中,进程对所有关联各自连接的消息执行协议任务栈。在一个连接中,多个协议任务在每个通过协议栈的消息流中按序调用。外出消息通常从应用进程中借用控制线程,并使用它沿着协议栈护送消息。对到来的消息来说,网络接口或包过滤器通常执行解多路复用操作来确定正确的消息关联进程。
Connection Parallelism 对同时处理很多连接的服务器应用来说十分有用。Connectional Parallelism 的优点是 (1) 降低了层间通讯开销 (因为在协议层中移动消息不需要进行上下文切换),(2) 给定连接中的同步和通讯开销相对较低 (因为同步进程内的下行调用和上行调用能被用于不同协议层间的通讯),(3) 可用的并行数量是动态确定的,因为它是活动连接数的函数 (而不是层或任务的数量的函数,它是静态确定的)。Connectional Parallelism 的缺点之一是 PE 负载均衡的困难度。例如,一个高度活跃的连接可能用消息淹没它的 PE,而使其他 PEs 束缚于不那么活跃或空闲的连接上。
Message Parallelism 关联单独的进程到每个到来或外出的消息上。如图 1(2) 所示,进程接收来自应用或网络接口的消息,并运送该消息通过协议栈中的协议处理任务。与 Connectional Parallelism 一样,外出消息通常借用来自应用的控制线程来初始化消息传输器。
Message Parallelism 的优点类似于 Connectional Parallelism。除此之外,可用的并行可能更高,因为它依赖于交换的消息数量,而非连接的数量。类似的,PEs 间的进程负载可能更均衡,因为每个到来的消息能被分配到一个可用的 PE 上。Message Parallelism 主要的缺点是序列化访问共享资源 (例如内存缓冲和控制块,它们重新组装协议 segment 并发往相同的更高层连接) 所需的同步和互斥原语造成的开销。
5.7 Summary
网络服务器可能关联一个或多个 OS 进程或线程到一个或多个应用服务。这些因素需要多个维度的设计决定,这些维度影响线程和进程的使用,CPU 资源的使用,调度行为,和应用性能。本章对用于设计网络应用的并发维度进行了域分析。本书中剩下的章节描述依据此域分析得到的 ACE 封装外观。我们会重点关注封装和使用如今操作系统上可用的同步事件解多路复用,多进程,多线程以及同步机制的利与弊。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









