




论文地址:https://arxiv.org/abs/2206.09959 https://arxiv.org/abs/2206.09959
https://arxiv.org/abs/2206.09959
代码地址:
 https://github.com/NVlabs/GCViT
https://github.com/NVlabs/GCViT
作者提出了全局上下文Vision Transformer(GCViT),这是一种提高参数和计算利用率的新架构。提出的方法利用全局上下文自注意模块,与局部自注意相结合,有效地建模长期和短期空间交互,而不需要昂贵的操作。
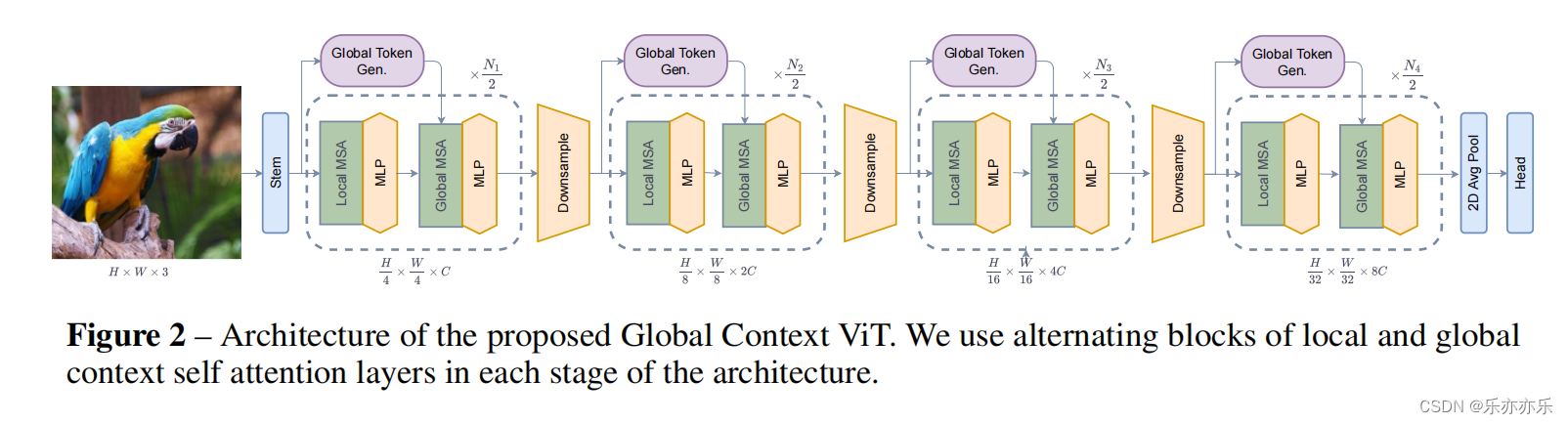
在这项工作中,作者引入Global Context(GC)ViT 网络。提出了一个由局部和全局自注意模块组成的分层ViT架构。在每个阶段,作者使用修改的fused inverted residual 模块来计算全局query token。作者称之为Fused-MBConv 模块,它包含来自不同图像区域的全局上下文信息。本地自注意模块负责对short-range信息进行建模,而全局query token 在所有全局自注意模块之间共享,以与本地key和value进行交互。
论文主要贡献:
- 一种新的分层Transformer模型,称为GCViT,它可以作为各种计算机视觉任务的通用主干网络,如分类、检测、实例分割;
- 一种新颖而简单的设计,由全局自注意和令牌生成模块组成,允许通过捕获全局上下文信息来建模长期依赖关系,从而消除了对高度复杂或复杂操作的需要;
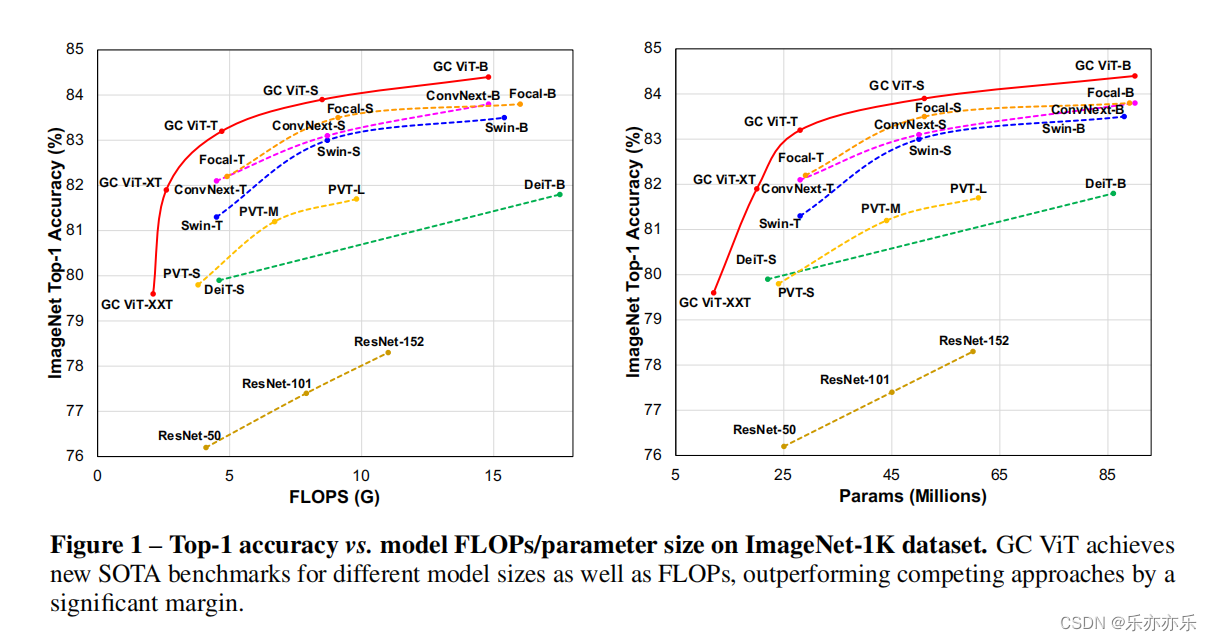
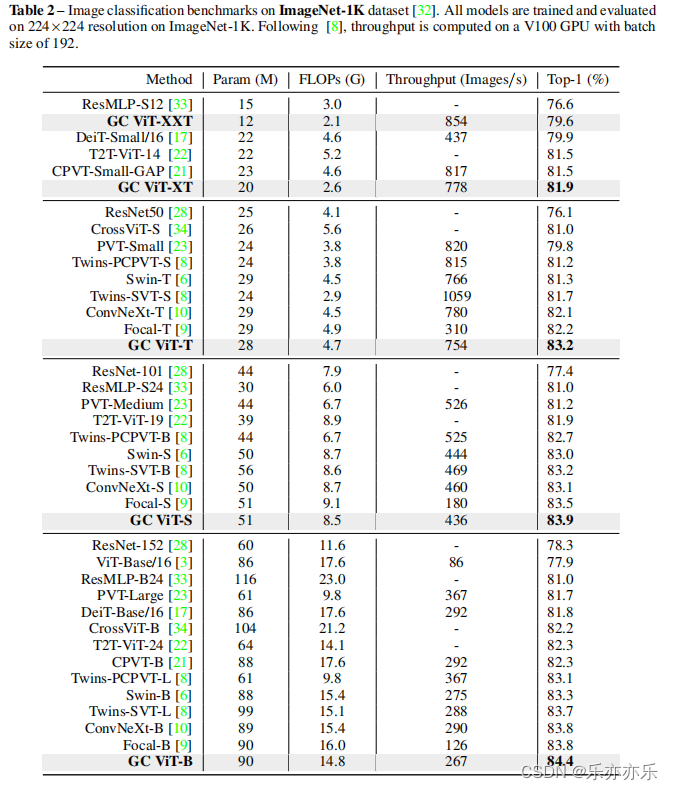
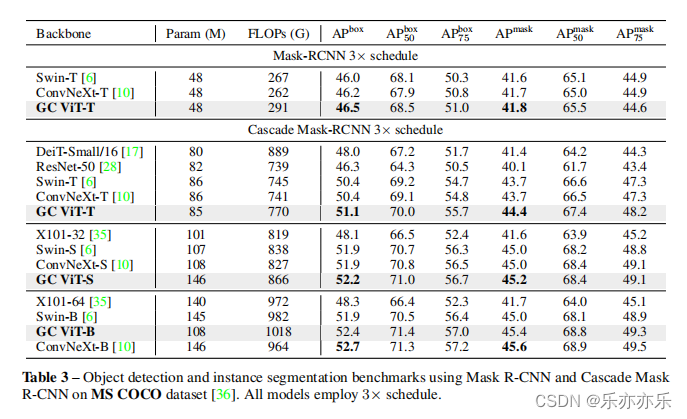
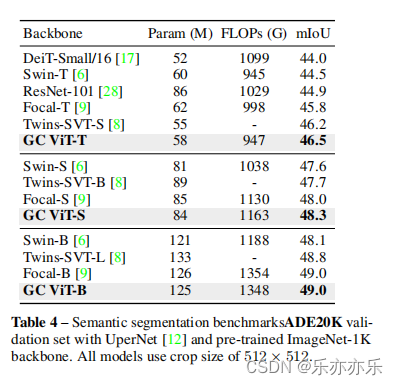
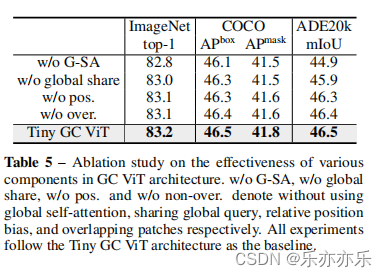
- 如图1所示,实验结果SOTA。
网络结构:
GC ViT 结构
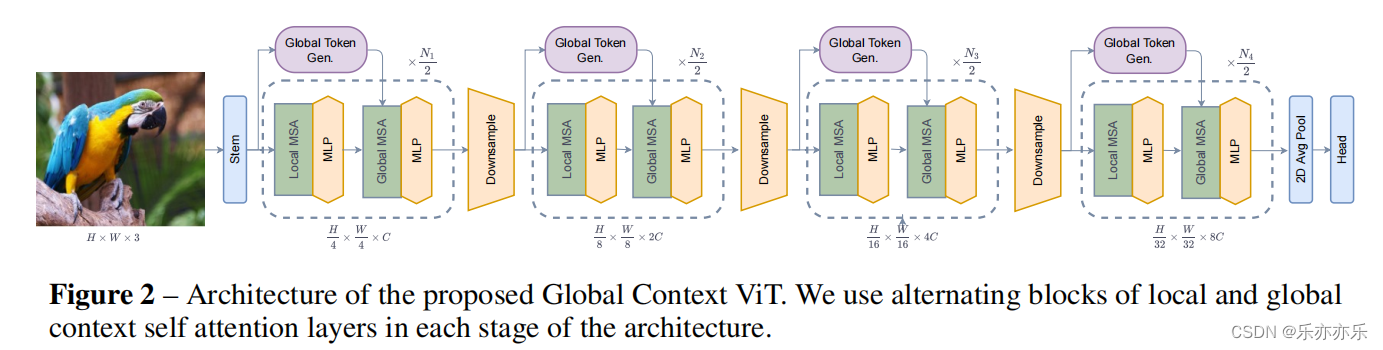
网络结构如图2所示。与之前的一些Transformer架构类似,使用一个层次框架,通过减少空间维度,同时扩大嵌入维数,分别获得几个分辨率(称为阶段)的特征表示。
首先输入图像的分辨率为H X W X 3 ,通过应用一个3×3的卷积层和适当的填充来获得重叠(overlapping)的patch。然后将patch投影到C维嵌入空间中。每个GCViT阶段都由交替的局部和全局自注意模块组成,以提取空间特征。两者都在像Swin Transformer 这样的 local windows 中运行,然而,全局自注意访问 Global Toke Generator (GTG)提取的全局特征。GTG是一个类似于cnn的模块,它在每个阶段只从整个图像中提取一次特征。每个阶段后增加一个下采样模块,空间分辨率减少一半。生成的特征通过平均池化和线性层传递,以为下游任务创建嵌入。
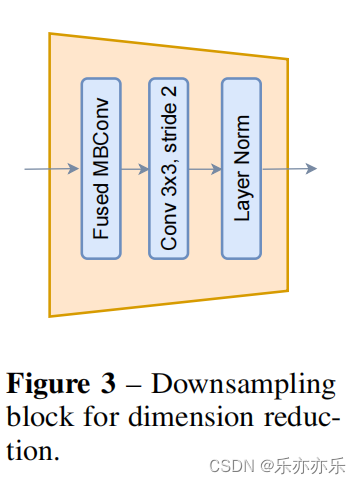

从CNN模型中借用了空间特征收缩的概念,该模型在降维的同时施加了局部性偏差和跨通道通信。
class ReduceSize(nn.Module):
def __init__(self, dim,
norm_layer=nn.LayerNorm,
keep_dim=False):
super().__init__()
self.conv = nn.Sequential(
nn.Conv2d(dim, dim, 3, 1, 1,
groups=dim, bias=False),
nn.GELU(),
SE(dim, dim),
nn.Conv2d(dim, dim, 1, 1, 0, bias=False),
)
if keep_dim:
dim_out = dim
else:
dim_out = 2*dim
self.reduction = nn.Conv2d(dim, dim_out, 3, 2, 1, bias=False)
self.norm2 = norm_layer(dim_out)
self.norm1 = norm_layer(dim)
def forward(self, x):
x = x.contiguous()
x = self.norm1(x)
x = x.permute(0, 3, 1, 2)
x = x + self.conv(x)
x = self.reduction(x).permute(0, 2, 3, 1)
x = self.norm2(x)
return x
Global Query Generator
作者提出包含跨整个输入特征图的信息的全局查询标记(global query tokens),以便与局部键keys和值values特征进行交互。如图5所示:
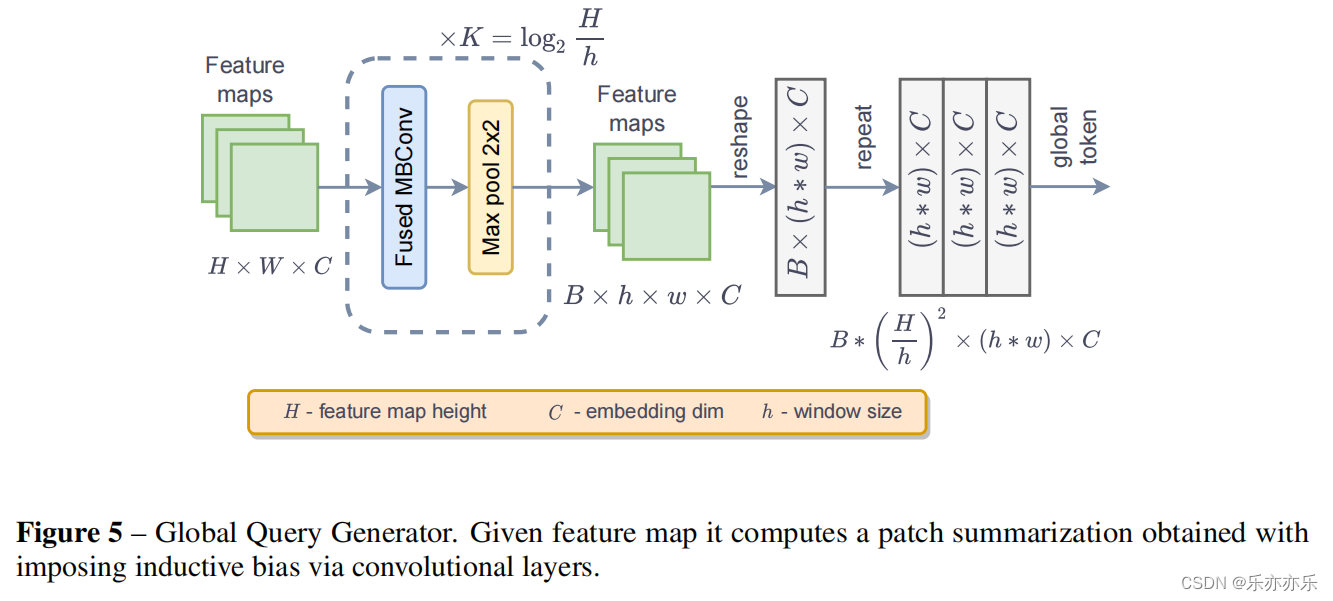
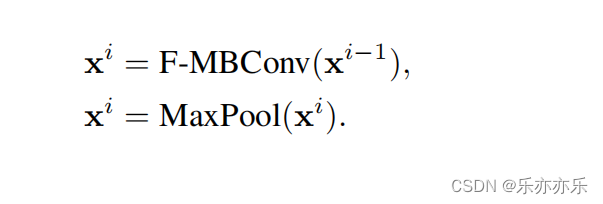
class FeatExtract(nn.Module):
def __init__(self, dim, keep_dim=False):
super().__init__()
self.conv = nn.Sequential(
nn.Conv2d(dim, dim, 3, 1, 1,
groups=dim, bias=False),
nn.GELU(),
SE(dim, dim),
nn.Conv2d(dim, dim, 1, 1, 0, bias=False),
)
if not keep_dim:
self.pool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
self.keep_dim = keep_dim
def forward(self, x):
x = x.contiguous()
x = x + self.conv(x)
if not self.keep_dim:
x = self.pool(x)
return x
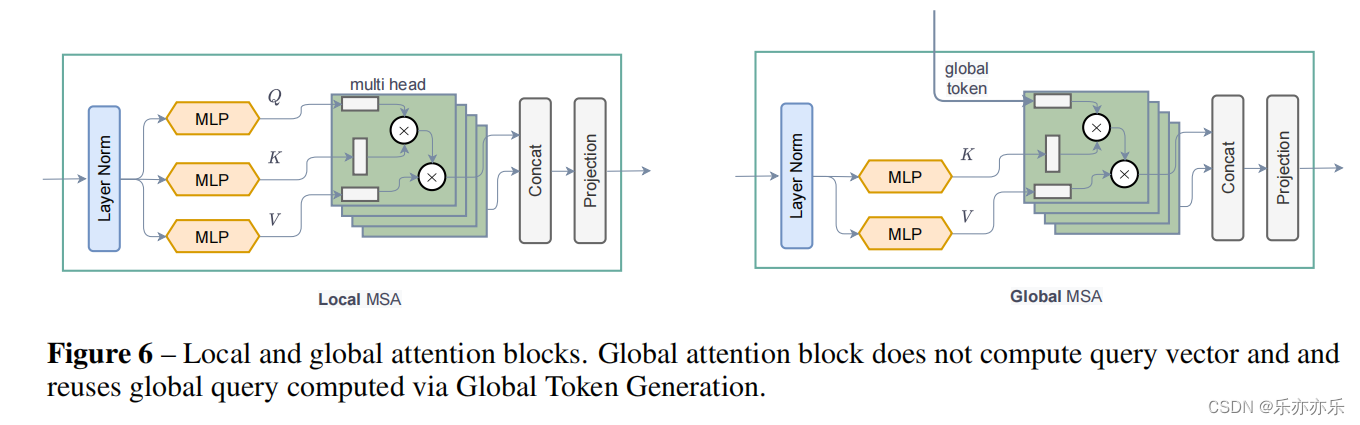
Local MSA:
class WindowAttention(nn.Module):
def __init__(self,
dim,
num_heads,
window_size,
qkv_bias=True,
qk_scale=None,
attn_drop=0.,
proj_drop=0.,
):
super().__init__()
window_size = (window_size,window_size)
self.window_size = window_size
self.num_heads = num_heads
head_dim = dim // num_heads
self.scale = qk_scale or head_dim ** -0.5
self.relative_position_bias_table = nn.Parameter(
torch.zeros((2 * window_size[0] - 1) * (2 * window_size[1] - 1), num_heads))
coords_h = torch.arange(self.window_size[0])
coords_w = torch.arange(self.window_size[1])
coords = torch.stack(torch.meshgrid([coords_h, coords_w]))
coords_flatten = torch.flatten(coords, 1)
relative_coords = coords_flatten[:, :, None] - coords_flatten[:, None, :]
relative_coords = relative_coords.permute(1, 2, 0).contiguous()
relative_coords[:, :, 0] += self.window_size[0] - 1
relative_coords[:, :, 1] += self.window_size[1] - 1
relative_coords[:, :, 0] *= 2 * self.window_size[1] - 1
relative_position_index = relative_coords.sum(-1)
self.register_buffer("relative_position_index", relative_position_index)
self.qkv = nn.Linear(dim, dim * 3, bias=qkv_bias)
self.attn_drop = nn.Dropout(attn_drop)
self.proj = nn.Linear(dim, dim)
self.proj_drop = nn.Dropout(proj_drop)
trunc_normal_(self.relative_position_bias_table, std=.02)
self.softmax = nn.Softmax(dim=-1)
def forward(self, x, q_global):
B_, N, C = x.shape
qkv = self.qkv(x).reshape(B_, N, 3, self.num_heads, C // self.num_heads).permute(2, 0, 3, 1, 4)
q, k, v = qkv[0], qkv[1], qkv[2]
q = q * self.scale
attn = (q @ k.transpose(-2, -1))
relative_position_bias = self.relative_position_bias_table[self.relative_position_index.view(-1)].view(
self.window_size[0] * self.window_size[1], self.window_size[0] * self.window_size[1], -1)
relative_position_bias = relative_position_bias.permute(2, 0, 1).contiguous()
attn = attn + relative_position_bias.unsqueeze(0)
attn = self.softmax(attn)
attn = self.attn_drop(attn)
x = (attn @ v).transpose(1, 2).reshape(B_, N, C)
x = self.proj(x)
x = self.proj_drop(x)
return Global MSA:

class WindowAttentionGlobal(nn.Module):
def __init__(self, dim,
num_heads,
window_size,
qkv_bias=True,
qk_scale=None,
attn_drop=0.,
proj_drop=0.,
):
super().__init__()
window_size = (window_size,window_size)
self.window_size = window_size
self.num_heads = num_heads
head_dim = dim // num_heads
self.scale = qk_scale or head_dim ** -0.5
self.relative_position_bias_table = nn.Parameter(
torch.zeros((2 * window_size[0] - 1) * (2 * window_size[1] - 1), num_heads))
coords_h = torch.arange(self.window_size[0])
coords_w = torch.arange(self.window_size[1])
coords = torch.stack(torch.meshgrid([coords_h, coords_w]))
coords_flatten = torch.flatten(coords, 1)
relative_coords = coords_flatten[:, :, None] - coords_flatten[:, None, :]
relative_coords = relative_coords.permute(1, 2, 0).contiguous()
relative_coords[:, :, 0] += self.window_size[0] - 1
relative_coords[:, :, 1] += self.window_size[1] - 1
relative_coords[:, :, 0] *= 2 * self.window_size[1] - 1
relative_position_index = relative_coords.sum(-1)
self.register_buffer("relative_position_index", relative_position_index)
self.qkv = nn.Linear(dim, dim * 2, bias=qkv_bias)
self.attn_drop = nn.Dropout(attn_drop)
self.proj = nn.Linear(dim, dim)
self.proj_drop = nn.Dropout(proj_drop)
trunc_normal_(self.relative_position_bias_table, std=.02)
self.softmax = nn.Softmax(dim=-1)
def forward(self, x, q_global):
B_, N, C = x.shape
B = q_global.shape[0]
kv = self.qkv(x).reshape(B_, N, 2, self.num_heads, C // self.num_heads).permute(2, 0, 3, 1, 4)
k, v = kv[0], kv[1]
q_global = q_global.repeat(B_//B, 1, 1, 1)
q = q_global.reshape(B_, self.num_heads, N, C // self.num_heads)
q = q * self.scale
attn = (q @ k.transpose(-2, -1))
relative_position_bias = self.relative_position_bias_table[self.relative_position_index.view(-1)].view(
self.window_size[0] * self.window_size[1], self.window_size[0] * self.window_size[1], -1)
relative_position_bias = relative_position_bias.permute(2, 0, 1).contiguous()
attn = attn + relative_position_bias.unsqueeze(0)
attn = self.softmax(attn)
attn = self.attn_drop(attn)
x = (attn @ v).transpose(1, 2).reshape(B_, N, C)
x = self.proj(x)
x = self.proj_drop(x)
return x
几种模型结构配置:
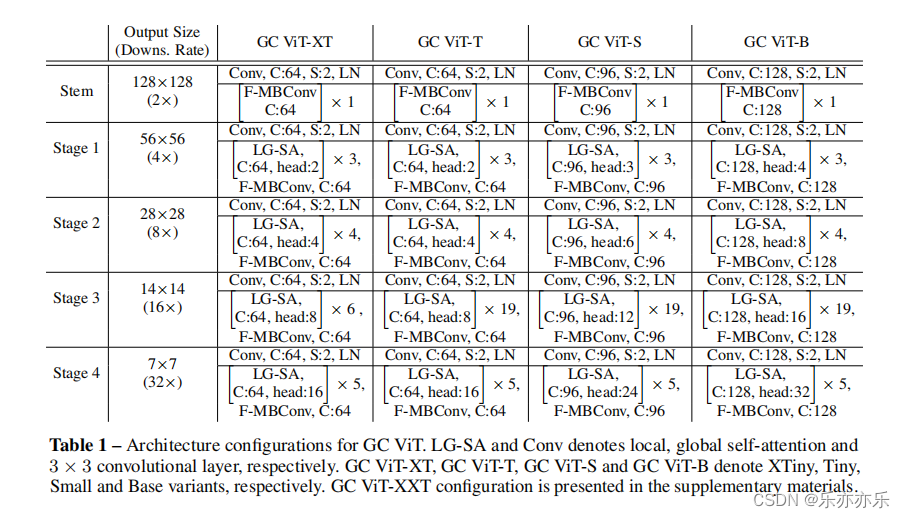
实验结果:


















 580
580

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











