




 本文介绍使用Python的Selenium库进行实时数据挖掘,涵盖了新浪财经、东方财富网、裁判文书网和巨潮资讯网的数据获取和处理。通过获取网页源代码、编写正则表达式提取关键数据,并进行数据清洗,实现对各网站信息的有效抓取和分析。
本文介绍使用Python的Selenium库进行实时数据挖掘,涵盖了新浪财经、东方财富网、裁判文书网和巨潮资讯网的数据获取和处理。通过获取网页源代码、编写正则表达式提取关键数据,并进行数据清洗,实现对各网站信息的有效抓取和分析。
实时数据挖掘
目录
序言
通过使用Selenium库实现对新浪财经股票实时数据、东方财富网、裁判文书网、巨潮资讯网的实时数据挖掘。由于这部分内容涉及爬虫进阶知识,所以我把这部分内容归于爬虫专栏。
1. 新浪财经实时数据挖掘实战
1.1 获取网页源代码
使用无界面浏览器方式获取源代码
from selenium import webdriver
chrome_options = webdriver.ChromeOptions()
chrome_options.add_argument('--headless')
browser = webdriver.Chrome(executable_path=r'C:\Users\wwww\AppData\Local\Google\Chrome\Application\chromedriver.exe',
options=chrome_options)
browser.get("http://finance.sina.com.cn/realstock/company/sh000001/nc.shtml")
data = browser.page_source
browser.quit()
print(data)
部分结果如图所示:
1.2 数据提取
我们要提取上证综合指数,因为这个指数是唯一的且不断变化,首先我们要定位网页源代码。
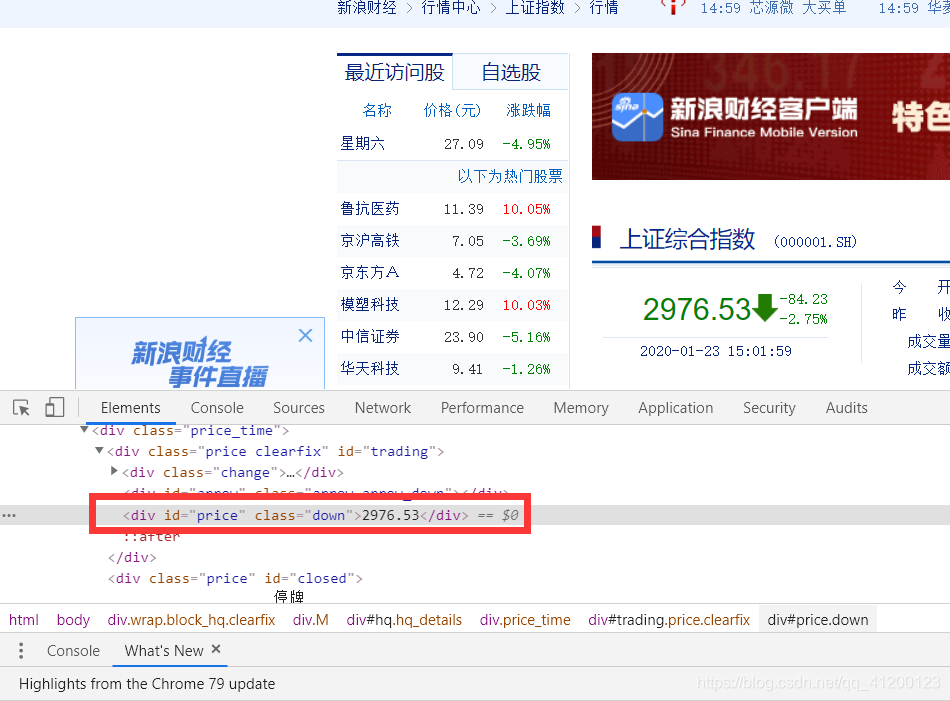
可以得到,如果上证综合指数是下降的话,class为down;同理,如果上证综合指数是上升的话,class为up。
from selenium import webdriver
import re
chrome_options = webdriver.ChromeOptions()
chrome_options.add_argument('--headless')
browser = webdriver.Chrome(executable_path=r'C:\Users\wwww\AppData\Local\Google\Chrome\Application\chromedriver.exe',
options=chrome_options)
browser.get('http://finance.sina.com.cn/realstock/company/sh000001/nc.shtml')
data = browser.page_source
browser.quit()
p_price = '<div id="price" class=".*?">(.*?)</div>'
price = re.findall(p_price, data)
print(price) # 上证综合指数的股价
结果: [‘2976.53’]
2. 东方财富网数据挖掘实战
2.1 获取网页源代码
首先我们进入东方财富网,然后点击搜索阿里巴巴,我们爬取阿里巴巴的源代码。
我们使用无界面浏览器模式来获取该网站源代码:
from selenium import webdriver
chrome_options = webdriver.ChromeOptions()
chrome_options.add_argument('--headless')
browser = webdriver.Chrome(executable_path=r'C:\Users\wwww\AppData\Local\Google\Chrome\Application\chromedriver.exe',
options=chrome_options)
browser.get('http://so.eastmoney.com/news/s?keyword=阿里巴巴')
data = browser.page_source
print(data)
browser.quit()
部分结果如下图所示:
2.2 编写正则表达式提取数据
我们的要提取新闻题目、链接、日期,首先查看网站源代码:
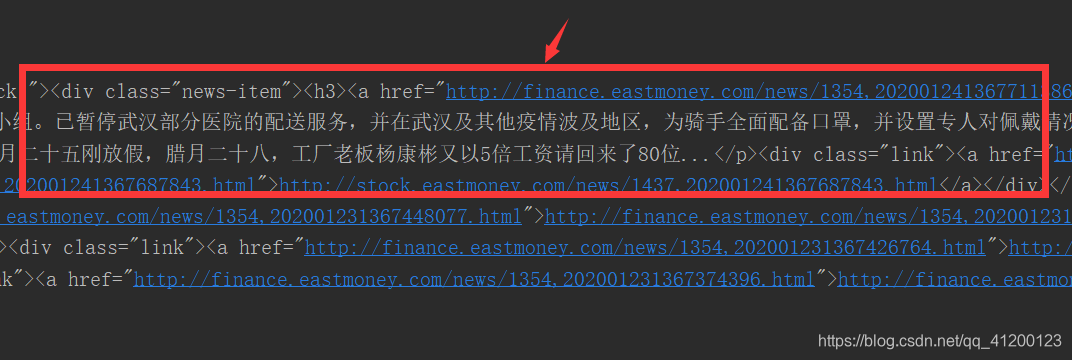
有了源代码,我们就可以编写正则表达式来提取这一部分的数据了。
p_title = '<div class="news-item"><h3><a href=".*?">(.*?)</a>'
p_href = '<div class="news-item"><h3><a href="(.*?)">.*?</a>'
p_date = '<p class="news-desc">(.*?)</p>'
title = re.findall(p_title, data 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1320
1320

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









