




 本文介绍了使用SparkStreaming进行实时数据分析的应用场景,如社交媒体、电商和搜索引擎中的热门话题追踪。通过设定窗口长度和滑动间隔,可以每5分钟更新一次过去30分钟的热搜内容,展示排名前三的话题。文章还探讨了窗口操作的原理和参数设置,强调它们必须是源DStream批处理间隔的倍数。
本文介绍了使用SparkStreaming进行实时数据分析的应用场景,如社交媒体、电商和搜索引擎中的热门话题追踪。通过设定窗口长度和滑动间隔,可以每5分钟更新一次过去30分钟的热搜内容,展示排名前三的话题。文章还探讨了窗口操作的原理和参数设置,强调它们必须是源DStream批处理间隔的倍数。
1.背景描述
- 在社交网络(微博),电子商务(京东)、搜索引擎(百度)、股票交易中人们关心的内容之一是我所关注的内容中,大家正在关注什么
- 在实际企业中非常有价值
- 例如:我们关注过去30分钟大家都在热搜什么?并且每5分钟更新一次。要求列出来搜索前三名的话题内容
2.原理图
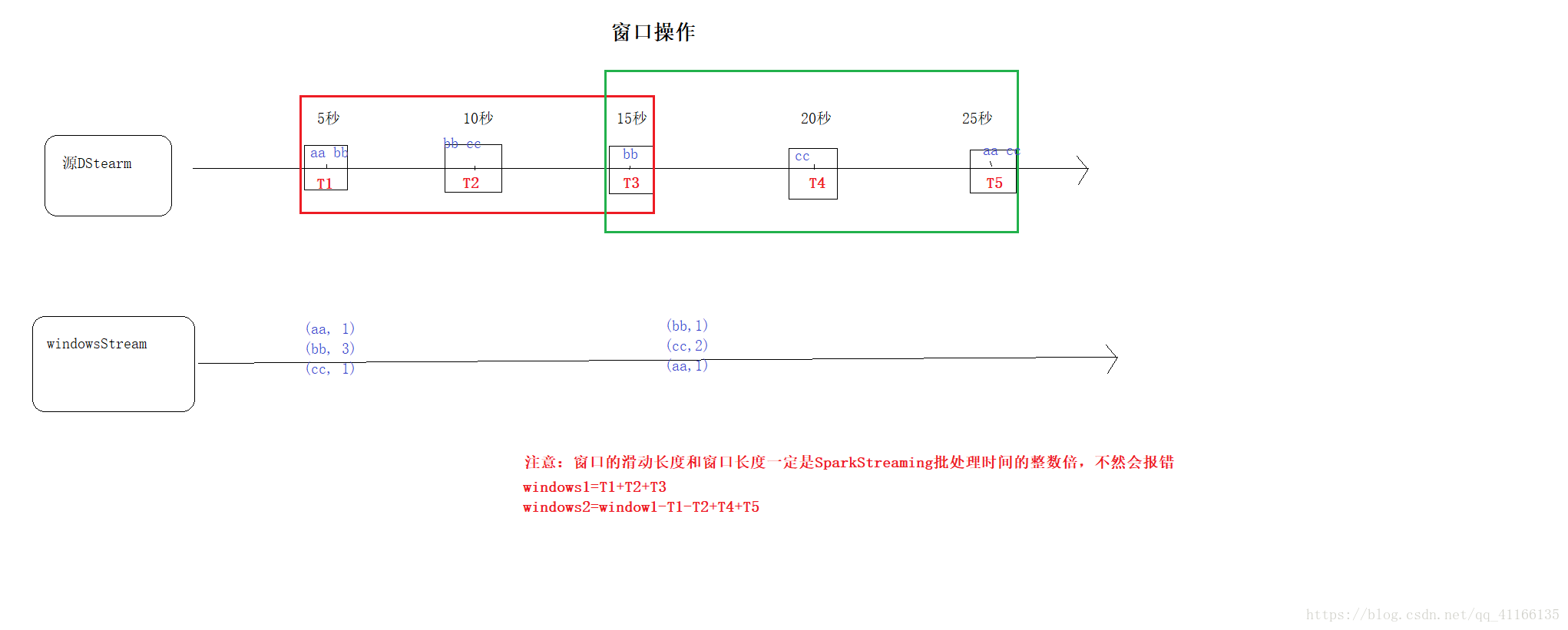
如图所示,每当窗口滑过DStream时,落在窗口内的源RDD被组合并被执行操作以产生windowed DStream的RDD。在上面的例子中,操作应用于最近3个时间单位的数据,并以2个时间单位滑动。这表明任何窗口操作都需要指定两个参数。
窗口长度(windowlength) - 窗口的时间长度(上图的示例中为:15)。
滑动间隔(slidinginterval) - 两次相邻的窗口操作的间隔(即每次滑动的时间长度)(上图示例中为:10)。
这两个参数必须是源DStream的批间隔的倍数(上图示例中为:5)。
3.代码
问题:
* 下述代码每隔20秒回重新计算之前60秒内的所有数据,如果窗口滑动时间间隔太短,那么需要重新计算的数据就比较大,非常耗时
* 怎么理解呢?窗口滑动时间间隔短的话,与窗口长度的交集每次都必须重新计算,浪费资源,避免交集太大的话就应该设置滑动间隔长一点
* //第一个Seconds是窗口大小(3个RDD一共需要的时间),第二个Seconds是窗口间隔时间
* searchPair.reduceByKeyAndWindow((v1:Int, v2:Int) => v1+v2, (v1:Int, v2:Int) => v1-v2, Seconds(60), Seconds(20))
*
object OnlineHotItems {
def main(args: Array[String]): Unit = {
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









