




一个很简单的百度贴吧看帖子和回复的爬虫小脚本
摸鱼必备哦
- 运行实例
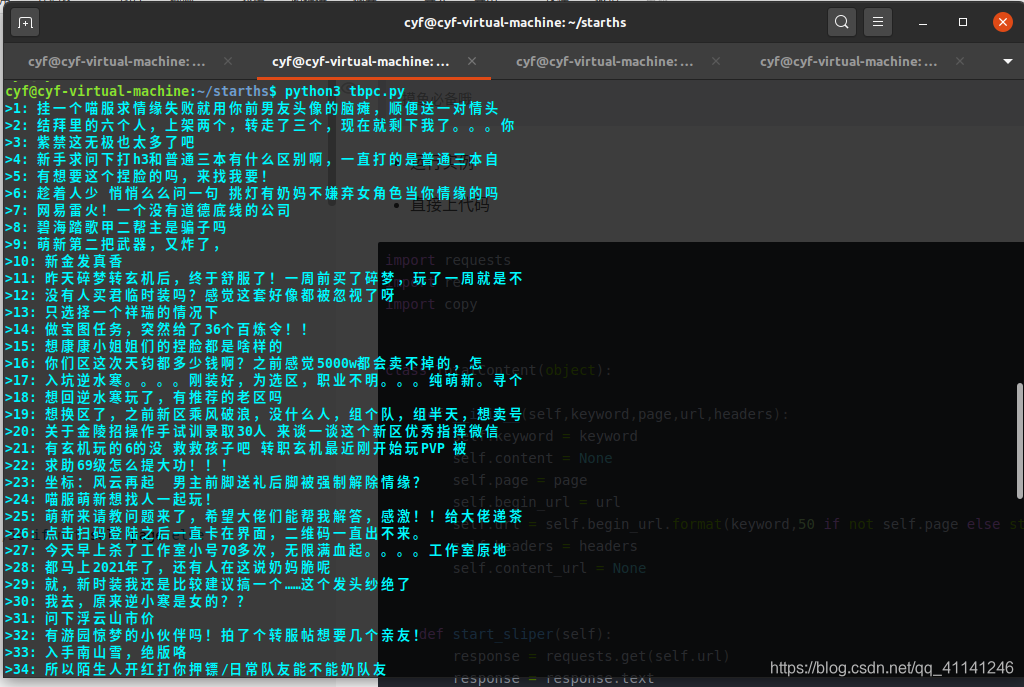
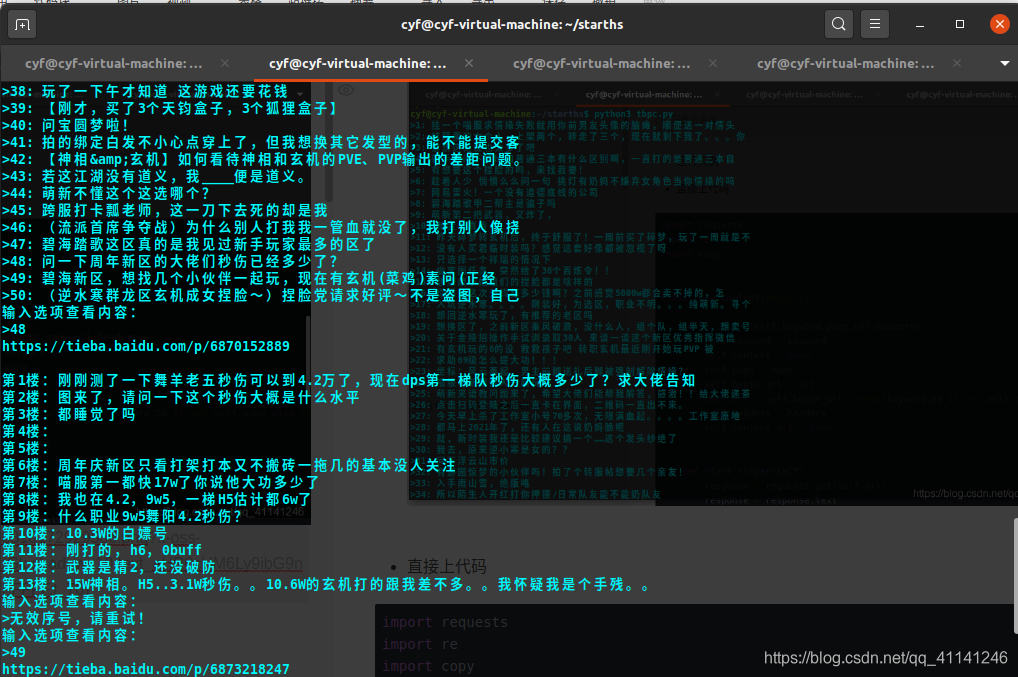
- 操作简介
- next 指令 切换下一页
- prev 指令切换上一页
- exit 退出程序
- 代码
import requests
import re
import copy
class TotalContent(object):
def __init__(self,keyword,page,url,headers):
self.keyword = keyword
self.content = None
self.page = page
self.begin_url = url
self.url = self.begin_url.format(keyword,50 if not self.page else str(self.page*50))
self.headers = headers
self.content_url = None
def start_sliper(self):
response = requests.get(self.url)
response = response.text
title_list = re.findall('target="_blank" class="j_th_tit ">(.*?)</a>',response)
url_list = re.findall('<a rel="noreferrer" href="(.*?)" title=',response)
new_title_list = copy.copy(title_list)
for pre in title_list:
if '<span class="topic-tag" data-name="%E7%B4%AB%E7%A6%81%E4%B9%8B%E5%B7%85">#紫禁之巅#</span>' in pre:
new_title_list.remove(pre)
pre = pre.replace('<span class="topic-tag" data-name="%E7%B4%AB%E7%A6%81%E4%B9%8B%E5%B7%85">#紫禁之巅#</span>','')
new_title_list.append(pre)
if '<span class="topic-tag" data-name="%E9%80%86%E6%B0%B4%E5%AF%92">#逆水寒#</span>' in pre:
new_title_list.remove(pre)
pre = pre.replace('<span class="topic-tag" data-name="%E9%80%86%E6%B0%B4%E5%AF%92">#逆水寒#</span>','')
new_title_list.append(pre)
[print('>'+str(index+1)+': '+str(i)) for index,i in enumerate(new_title_list)]
while True:
xv = input('输入选项查看内容:\n>')
try:
if int(xv) in range(1,51):
self.content_url = url_list[int(xv)-1]
self.open_url()
else:
print('无效序号,请重试!')
except ValueError:
if xv == 'next':
self.page += 1
self.url = self.begin_url.format(keyword,50 if not self.page else str(self.page*50))
self.start_sliper()
elif xv == 'prev':
self.page -= 1
self.url = self.begin_url.format(keyword,50 if not self.page else str(self.page*50))
self.start_sliper()
elif xv == 'exit':
break
else:
print('无效序号,请重试!')
def open_url(self):
url = 'https://tieba.baidu.com'+self.content_url
print(url)
response = requests.get(url,headers=self.headers)
response = response.text
replay_list = re.findall('class="d_post_content j_d_post_content " style="display:;"> (.*?)</div><br>',response)
new_replay_list = []
for pre in replay_list:
new_str = re.sub('<img class="BDE_Image" (.*?)>','',pre)
new_str_1 = re.sub('<br>','',new_str)
new_str_2 = re.sub('<img class="BDE_Smiley" (.*?)>','',new_str_1)
new_str_3 = re.sub('<div class="post_bubble_top" (.*?)><div class="post_bubble_middle_inner">','',new_str_2)
new_str_4 = re.sub('</div></div><div class="post_bubble_bottom" (.*?)></div>','',new_str_3)
new_str_5 = re.sub('<span class="topic-tag" data-name="(.*?)">(.*?)</span>','',new_str_4)
new_replay_list.append(new_str_5)
[print('第'+str(index+1)+'楼:'+str(i)) for index,i in enumerate(new_replay_list)]
if __name__ == '__main__':
start_url = 'https://tieba.baidu.com/f?kw={}&pn={}'
keyword = '逆水寒ol'
page = 1
headers={
'Accept':'*/*',
'Accept-Encoding':'gzip, deflate, br',
'Accept-Language':'zh-CN,zh;q=0.9',
'Connection':'keep-alive',
'Cookie': 'BIDUPSID=5F5D41E2809D195FCB930C0058D67AB9; PSTM=1595489660; BAIDUID=5F5D41E2809D195F6CB31D26890EF4BA:FG=1; BDORZ=B490B5EBF6F3CD402E515D22BCDA1598; BDUSS=ZVSE54dHdpOGx1TlYySVNFLUNackZXWW5vfnRCeEFWOC1tRTJ5aG1PNXdkRXhmRVFBQUFBJCQAAAAAAAAAAAEAAAAjqt42bXnYvGRyZWFtY2MAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAHDnJF9w5yRfZ3; BDUSS_BFESS=ZVSE54dHdpOGx1TlYySVNFLUNackZXWW5vfnRCeEFWOC1tRTJ5aG1PNXdkRXhmRVFBQUFBJCQAAAAAAAAAAAEAAAAjqt42bXnYvGRyZWFtY2MAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAHDnJF9w5yRfZ3; cflag=13%3A3; BDRCVFR[feWj1Vr5u3D]=I67x6TjHwwYf0; delPer=0; PSINO=1; H_PS_PSSID=32292_1442_32438_32355_32351_32045_32393_32429_32115_31709_32435_31639',
# 'Host': 'tbmsg.baidu.com',
'Referer':'https://tieba.baidu.com/f?kw=%E9%80%86%E6%B0%B4%E5%AF%92ol&ie=utf-8&pn=50',
'Sec-Fetch-Dest': 'script',
'Sec-Fetch-Mode': 'no-cors',
'Sec-Fetch-Site': 'same-site',
'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.89 Safari/537.36'
}
tl = TotalContent(keyword=keyword,page=page,url=start_url,headers=headers)
tl.start_sliper()

















 1385
1385

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









