




L2正则化
- 就是在原本的(成本、代价)损失函数后面加上一个正则化项。
- L2正则化,也成为weight decay,权重衰减
L2正则化是为了防止训练网络的时候出现“过拟合”,现在来理解一下网络的“欠拟合”与“过拟合”。
数学上从两个角度来衡量一个变量的误差: - 偏差bias
- 方差variance
神经网络中有 - train error:训练误差,训练过程其实就是根据“损失”来动态调整模型参数。随机梯度下降SGD。BP。权重更新。
- validate error:验证误差。在遗传算法中,评估个体适应度时,需要用到validate dataset。
- 在训练网络时,用train error和validate error来衡量是否过/欠拟合。
偏差和方差的权衡
前提:最优误差(贝叶斯误差):假设人的肉眼识别图像几乎假设误差为0%,且假设训练集和测试集服从同分布。。
欠拟合—偏差(bias)过高,适度拟合,过拟合—high variance高方差
Train set error:偏差 1% | 15% |15%
Dev set error:方差 11% | 16% |30%
过拟合(high variance) | 欠拟合(high bias) |high bias&high variance
high bias&high variance:可能是部分数据过拟合,但整体数据欠拟合。
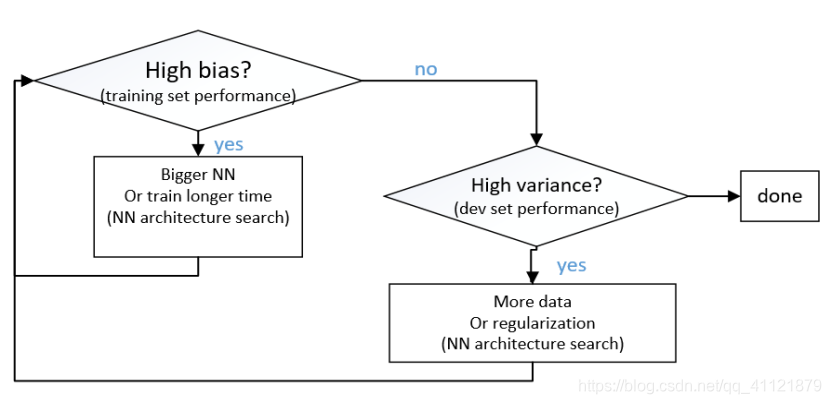
防止过拟合的方法:
(1)regularization正则化: L1,L2正则化,两者均是通过修正成本函数,使得权重矩阵范数较小,从而使得网络不会过于复杂。
(2)数据增强(data augmentation)通过增加训练数据样本数
(3)Dropout (:中途退学,【计算机】信息丢失)
(4)Early stopping
现在来详细解释一下L2正则化
原本的成本函数后面加上的那一个项是L2范数。

为啥L2正则化可以防止过拟合?推导过程
公式:

L2范数规格化(也叫做weight dekay权重衰减):成本函数、L2范数、lambda规格化参数,lambda也是一个超参数,需要利用验证集或交叉验证法来确定。

现在假设激活函数是tanh()



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









