



 本文详细解析了一种名为SecretPoems的矩阵变换算法,该算法通过特定的规则将输入的n*n矩阵元素重新排列并输出。文章通过示例阐述了算法的工作原理,包括两个变换函数change1和change2的具体实现,以及它们如何共同作用于矩阵元素的移动。通过阅读本文,读者可以了解SecretPoems算法的基本思想和实现细节。
本文详细解析了一种名为SecretPoems的矩阵变换算法,该算法通过特定的规则将输入的n*n矩阵元素重新排列并输出。文章通过示例阐述了算法的工作原理,包括两个变换函数change1和change2的具体实现,以及它们如何共同作用于矩阵元素的移动。通过阅读本文,读者可以了解SecretPoems算法的基本思想和实现细节。
【题目】
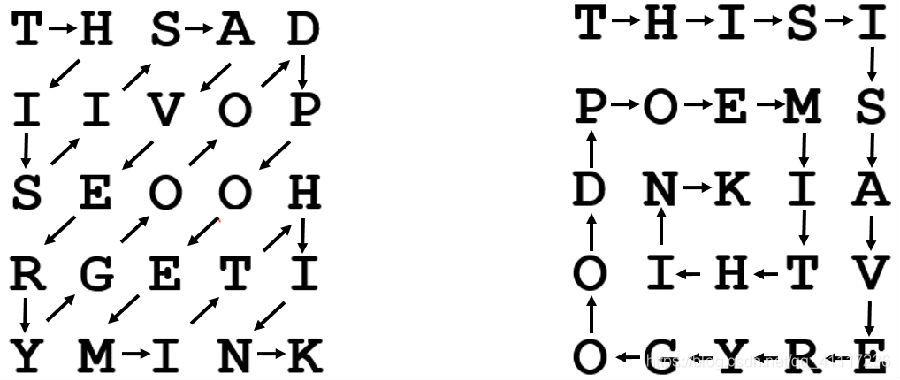
【题意】
给定n*n的矩阵,按左边的顺序再以右边的顺序输出。(讲道理我没看题哈哈哈,典型样例推题意)
【思路】
规律显而易见,就是实现起来有点麻烦。
change1表示图二的位置变化,change2表示图一,因为我一开始把图一的想简单了先搞的图二。好像没什么好讲的...
上代码。
【代码】
const int dx[]={1,0,-1,0};
const int dy[]={0,-1,0,1};
char a[105][105],b[105][105];
int x,y,xx,yy,tx,ty,f,ff;
int n;
void change1()
{
if(f==3&&yy==ty) f=0;
else if(f==0&&xx==tx) f=1;
else if(f==1&&yy==n+1-ty) f=2,tx--;
else if(f==2&&xx==n+1-tx) f=3,ty--;
xx+=dx[f],yy+=dy[f];
}
void change2()
{
if(x<n&&y<n){
if(x==1&&(x+y)%2==0) y++;
else if((y+x)%2&&y==1) x++;
else if((x+y)%2) x++,y--;
else x--,y++;
}
else{
if(x==n&&(x+y)%2) y++;
else if((y+x)%2==0&&y==n) x++;
else if((x+y)%2) x++,y--;
else x--,y++;
}
}
int main()
{
while(~scanf("%d",&n)){
for(int i=1;i<=n;i++)
scanf("%s",a[i]+1);
xx=1,yy=1,x=1,y=1;
f=3,ff=1;
tx=n,ty=n;
for(int i=1;i<=n*n;i++){
b[xx][yy]=a[x][y];
change1(); change2();
}
for(int i=1;i<=n;i++)
for(int j=1;j<=n;j++)
printf(j<n?"%c":"%c\n",b[i][j]);
}
}

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









