






 本文介绍了Kafka作为高吞吐分布式消息系统的特点,包括解耦合、峰值压力缓冲、持久性和分布式等。详细讲解了Kafka的架构组成、消息队列特点以及集群搭建过程。接着探讨了SparkStreaming与Kafka结合的Receiver和Direct模式,分析了两种模式的数据丢失、并行度优化及消费者offset管理策略。
本文介绍了Kafka作为高吞吐分布式消息系统的特点,包括解耦合、峰值压力缓冲、持久性和分布式等。详细讲解了Kafka的架构组成、消息队列特点以及集群搭建过程。接着探讨了SparkStreaming与Kafka结合的Receiver和Direct模式,分析了两种模式的数据丢失、并行度优化及消费者offset管理策略。
kafka简介和Streaming-kafka
高吞吐的分布式消息系统,默认存储磁盘,默认保存7天
时间策略删除,kafka和很多消息系统不一样,很多消息系统是消费完了我就把它删掉,而kafka是根据时间策略删除,而不是消费完就删除,在kafka里面没有一个消费完这么个概念,只有过期这样一个概念
特点
系统之间解耦合
峰值压力缓冲
异步通信(消息队列)
生产者消费者模式,FIFO
高性能 吞吐量大
持久性 磁盘,顺序读写
分布式 副本,可扩展
时间/offset灵活 7天,读取位置
消息队列特点
可靠性:
自己不丢数据–不经过内存直接存入磁盘(0拷贝),保存数据7天
消费者不丢数据–至少一次
架构组成
producer 消息生产者,两种机制,1基于轮询,2key的Hash,若key为空则只能轮询写
broker 组成kafka集群的节点,broker间没有主从关系,依赖于ZK协调
broker负责消息的读写和存储,每个broker可以管理多个partition
topic 一类消息/消息队列
每个topic是由多个partition组成,可指定数量
partition 组成topic的单元,直接接触磁盘,消息是append到每个partition上的
每个partition内部消息是强有序的FIFO,每个消息都有一个序号-offset
创建partition可以指定副本
一个partition只对应一个broker
consumer 每个consumer都有自己的消费者组
每个消费者组在同一个topic消费时,该topic中数据只能被消费一次
不同的消费者组消费同一个topic时互不影响
0.8前由zk管理offset 0.8之后由kafka自身管理
zookeeper 存储元数据,broker,topic,partition…(offset)
集群搭建
命令
启动Kafka集群后启动kafka
bin/kafka-server-start.sh config/server.properties
创建topic:
bin/kafka-topics.sh --zookeeper sxt002:2181,sxt003:2181,sxt004:2181 --create --replication-factor 2 --partitions 3 --topic testflume
bin/kafka-topics.sh --zookeeper sxt002:2181,sxt003:2181,sxt004:2181 --create --replication-factor 2 --partitions 1 --topic LogError
查看topic
bin/kafka-topics.sh --zookeeper sxt002:2181,sxt003:2181,sxt004:2181 --list
启动消费者:
bin/kafka-console-consumer.sh --zookeeper sxt002:2181,sxt003:2181,sxt004:2181 --from-beginning --topic testflume
启动生产者
bin/kafka-topics.sh --zookeeper sxt002:2181,sxt003:2181,sxt004:2181 --create --replication-factor 2 --partitions 1 --topic mylog_cmcc
bin/kafka-console-consumer.sh --zookeeper sxt002:2181,sxt003:2181,sxt004:2181 --from-beginning --topic mylog_cmcc
删除
1 bin/kafka-topics.sh --zookeeper sxt002:2181,sxt003:2181,sxt004:2181 --delete --topic xxxx
2 在日志文件中找到相关topic xxxx删除文件夹 rm -rf ./xxxx/
3 取ZK删除元数据进入bin/zkCli.sh ./zkCli.sh ls /
ls /brokers/topics rmr /brokers/topics/xxxx
ls /
ls /config/topics rmr /config/topics/xxxx
ls /
ls /adimn/delete_topics rmr /adimn/delete_topics/xxxx
Streaming+kafka
SparkStreaming+kafka Receiver模式
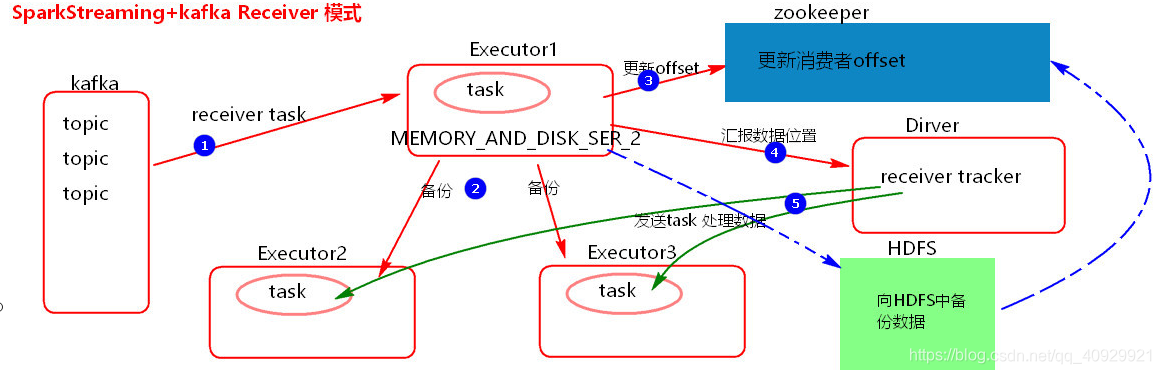
SparkStreaming+ kafka receiver模式:
处理数据采用了receiver接收器的模式,需要一个 task一直处于占用接收数据
接收来的数据存储级别: MEMORY AND_ DISK SER_2
这种模式几乎没有用的。因为存在数据丢失问题
丢失数据
当接收完消息后,更新完zokeeper offset后,如果Driver挂掉,Driver 下的Executor也会被klled ,在Executor内存中的数据多少会有丢失
解决丢失数据
开启WAL ( Write Ahead Log )预写日志机制。当Executor备份完数据之后,向HDFS中也备份- -份数据,备份完成之后,再去更新消费者offset。如果开启WAL机利,可以将接收来的数据存储级别降级,例如: MEMORY AND DISK_ SER。开启WAL机制要设置checkpoint
开启WAL机制,带来了新的问题
必须数据备份到HDFS完成之后,才会更新offset,下一步才会汇报数据位置,再发task处理数据, 会造成数据处理的延迟加大
Receiver模式的并行度
[每一批次生成的DStream中的RDD的分区数]
spark. streaming blockInterval = 200ms。在batchInterval 内每隔200ms ,将接收来的数据封装到一个block中, batchInterval时间内生成的这些block组成了当前这个batch。假设batchInterval = 5s , 5s内生成的一个batch中就有25个block。RDD- >batch RDD-> partition,batch-> block,这里每一个block就是对应RDD中的一个个的partition
提高RDD的并行度
当在batchInterval时间一定情兄下,减少spark.streaming blockInterval值;建议这个值不要低于50ms
SparkStreaming+ kafka Receiver模式
1.存在丢失数据问题,不常用
2.就算开启WAL机制解决了丢失数据问题,带来了新的问题,数据处理延迟大
3.receiver模式底层消费kafka , 采用的是High Level Consumer API实现,不关心消费者offset,无法从每批次中获取消费者offset和指定从某个offset继续消费数据
4.Receiver模式采用zookeeper来维护消费者offset
SparkStreaming+ kafka Direct模式
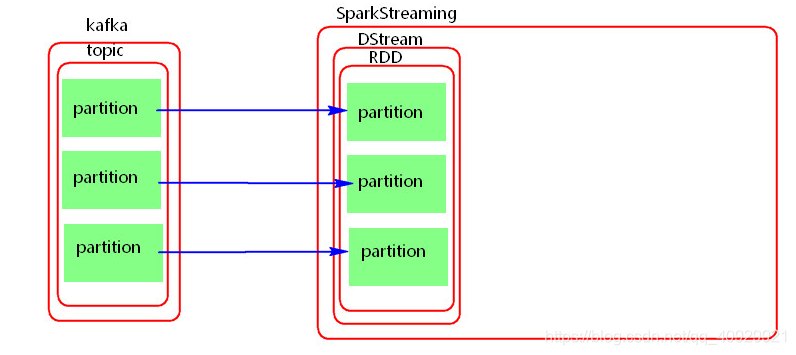
SparkStreaming + kafka Direct模式:
不需要一个task一直接收数据,当前批次处理数据时,直接读取数据处理。 Direct模式并行度与读取的topic中partition的个数一对一
Direct模式使用Spark自 已来维护消费者offset ,默认offset存储在内存中,如果设置了checkpoint ,在checkpoint中也有一份
Direct模式可以做到手动维护消费者offset
提高并行度
1增大读取的topic的partition个数
2.读取过来DStream之后,可以重新分区
Direc模式相对于Receiver模式
1.简化了并行度。默认的并行度与读取的kafka中topic的partition个数一对一
2.Receiver模式采用zookeeper来维护消费者offset,Direct模式使用Spark自已来维护消费者offset
3.Receiver模式采用消费kafka的High Level Consumer API实现, Direct模式采用的是读取kafka的Simple
Consumer API可以做到手动维护offset
SparkSteaming+kafka维护消费者offset
1.使用checkpoint管理肖费者offset(Spark1.6+ Spark2.3)
1).如果业务逻辑不变,可以使用checkpoint来管理消费者offset。使用StreamingContext. getOrCreate ( checkpoint目录, StreamingContext) 首先从checkpoint目录中恢复Streaming配置信息、逻辑、offset。 如果业务逻辑改变了,使用这种方式不会执行新的业务逻辑,恢复offset的同时,把旧的逻辑也恢复过来了
2),如果业务逻辑不变,使用checkpoint维护消费者offset ,存在重复消费数据问题,自己要保证后面处理数据的幂等性
2.依赖与kafka维护消费者offset(Spark2.3)
1).设置enable.auto.commit = false 关闭自动向Kafka自动提交offset
2).在保证业务完全处理完之后手动异步的向Kakfa中更新消费者offset
3.手动维护消费者offset(Spark1.6+ Spark2.3)
存储在redis中,首先从redis获取消费者上次保存的offset ->告诉SparkSteaming接着这个位置消费数据->每一批次将读取到的offset位置更新redis

















 848
848

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









