




 博客介绍了数据库水平分表时Mycat的分片策略,分为连续分片和离散分片。连续分片如范围、日期分片,有节省资源等优点,但可能导致负载不均;离散分片如枚举、一致性哈希等,能增强并发,但扩容困难。还详细阐述了多种分片规则的配置与测试。
博客介绍了数据库水平分表时Mycat的分片策略,分为连续分片和离散分片。连续分片如范围、日期分片,有节省资源等优点,但可能导致负载不均;离散分片如枚举、一致性哈希等,能增强并发,但扩容困难。还详细阐述了多种分片规则的配置与测试。
概述
数据库进行水平分表时,需要按照一定规则对数据进行分片。
Mycat的分片策略可以分为两种:
连续分片和离散分片。
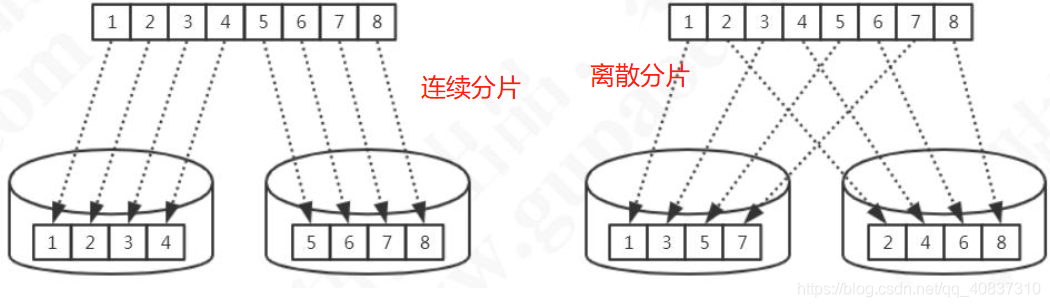
连续分片常用的有分片规则有:
- 范围分片。
- 日期分片。
优点:如果进行范围查询,比如查询连续100条数据,mycat就不用到每个节点查询数据再汇总,只需在一个节点查询返回即可,比较节省资源,并且如果进行节点的扩展,也不用进行数据的重新分片。
缺点:如果某些数据是越新的数据是热点数据的话,比如id 0-100000分配到节点1,然后过了一段时间之后,这些数据变成了冷数据,不再经常访问,但是节点2的100001-200000数据在此时变成了热点数据,这就会导致热点数据分布不均匀,从而导致某个承载大量热点数据的节点负载过高,最后造成节点之间负载不均匀、
离散分片常用的分配规则有:
- 枚举。
- 一致性哈希。
- 十进制取模。
- 固定分配哈希。
- 取模范围。
- 范围取模。
- 其他。
优点:
- 并发访问能力增强(负载到不同的节点)。
- 不会出现冷热数据分布不均匀的问题。
缺点: - 数据扩容比较困难,涉及到数据迁移问题
- 数据库连接消耗比较多,因为要经常汇总数据。
三台数据库节点。
表结构如下:
CREATE TABLE `customer` (
`id` int(11) DEFAULT NULL,
`name` varchar(255) DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
CREATE TABLE `order_info` (
`order_id` int(11) NOT NULL COMMENT '订单ID',
`uid` int(11) DEFAULT NULL COMMENT '用户ID',
`nums` int(11) DEFAULT NULL COMMENT '商品数量',
`state` int(2) DEFAULT NULL COMMENT '订单状态',
`create_time` datetime DEFAULT NULL ON UPDATE CURRENT_TIMESTAMP COMMENT '创建时间',
`update_time` datetime DEFAULT NULL ON UPDATE CURRENT_TIMESTAMP COMMENT '更新时间',
PRIMARY KEY (`order_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
CREATE TABLE `order_detail` (
`order_id` int(11) NOT NULL COMMENT '订单号',
`id` int(11) NOT NULL COMMENT '订单详情',
`goods_id` int(11) DEFAULT NULL COMMENT '货品ID',
`price` decimal(10,2) DEFAULT NULL COMMENT '价格',
`is_pay` int(2) DEFAULT NULL COMMENT '支付状态',
`is_ship` int(2) DEFAULT NULL COMMENT '是否发货',
`status` int(2) DEFAULT NULL COMMENT '订单详情状态',
PRIMARY KEY (`order_id`,`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
CREATE TABLE `student` (
`sid` int(8) NOT NULL AUTO_INCREMENT,
`name` varchar(255) DEFAULT NULL,
`qq` varchar(255) DEFAULT NULL,
PRIMARY KEY (`sid`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
CREATE TABLE `sharding_by_mod` (
`id` int(11) NOT NULL,
`db_nm` varchar(20) DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
CREATE TABLE `sharding_by_month` (
`create_time` timestamp NULL DEFAULT NULL ON UPDATE CURRENT_TIMESTAMP,
`db_nm` varchar(20) DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
CREATE TABLE `sharding_by_intfile` (
`age` int(11) NOT NULL,
`db_nm` varchar(20) DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
CREATE TABLE `sharding_by_murmur` (
`id` int(10) DEFAULT NULL,
`db_nm` varchar(20) DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
CREATE TABLE `sharding_by_long` (
`id` int(10) DEFAULT NULL,
`db_nm` varchar(20) DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
范围分片
按照id进行水平分片,1-100000分在节点1,100001-200000分在节点2,200001-~分在节点3.
先修改schema,配置对应的逻辑表和物理数据库地址和对应的分片规则。
<!-- 配置逻辑数据库-->
<schema name="mycat-test" checkSQLschema="true" sqlMaxLimit="100" dataNode="dn1">
<!--使用customer表来测试范围分片-->
<!--dataNode数据节点,多个用逗号隔开-->
<!--rule配置分片规则-->
<!--primaryKey配置该表的主键-->
<table name="customer" dataNode="dn1,dn2,dn3" rule="range-shard-by-id" primaryKey="id"/>
<!-- auto sharding by id (long) -->
<!--splitTableNames 启用<table name 属性使用逗号分割配置多个表,即多个表使用这个配置-->
<!--<table name="travelrecord,address" dataNode="dn1,dn2,dn3" rule="auto-sharding-long" splitTableNames ="true"/>-->
</schema>
<!--定义三个节点,dataHost由下面的dataHost标签配置,database配置物理数据库名称-->
<dataNode name="dn1" dataHost="mycat_test1" database="mycat_test" />
<dataNode name="dn2" dataHost="mycat_test2" database="mycat_test" />
<dataNode name="dn3" dataHost="mycat_test3" database="mycat_test" />
<!--配置真实数据库地址-->
<dataHost name="mycat_test1" maxCon="1000" minCon="10" balance="3"
writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100">
<heartbeat>select user()</heartbeat>
<!-- can have multi write hosts -->
<writeHost host="MasterHost1" url="192.168.18.142:3306" user="root"
password="123456">
</writeHost>
</dataHost>
<dataHost name="mycat_test2" maxCon="1000" minCon="10" balance="3"
writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100">
<heartbeat>select user()</heartbeat>
<!-- can have multi write hosts -->
<writeHost host="MasterHost1" url="192.168.18.143:3306" user="root"
password="123456">
</writeHost>
</dataHost>
<dataHost name="mycat_test3" maxCon="1000" minCon="10" balance="3"
writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100">
<heartbeat>select user()</heartbeat>
<!-- can have multi write hosts -->
<writeHost host="MasterHost1" url="192.168.18.144:3306" user="root"
password="123456">
</writeHost>
</dataHost>
配置分片规则:rule.xml
<!-- name就是配置规则名称,供上面印有 -->
<tableRule name="range-shard-by-id">
<rule>
<!-- columns配置分片键,也就是进行分片规则的字段 -->
<columns>id</columns>
<!-- algorithm配置分片算法,在下面定义 -->
<algorithm>range-shard</algorithm>
</rule>
</tableRule>
<!-- name算法名称,用于上面引用 -->
<!-- class算法的类,这里使用mycat自带的AutoPartitionByLong -->
<!-- mapFile属性配置范围与节点指定的文件 -->
<function name="range-shard"
class="io.mycat.route.function.AutoPartitionByLong">
<property name="mapFile">range-shard-long.txt</property><!-- 范围与节点对应指定文件 -->
<!--默认节点,当路由不到节点就分到该节点上,如果不配置并且路由不到就会报错并新数据失败。-->
<property name="defaultNode">2</property>
</function>
配置range-shard-long.txt
#id为0-100000会分到第0个节点,下面类似。
0-100000=0
100001-200000=1
重启mycat,测试
连接mycat执行下面新增语句:
INSERT INTO `customer` (`id`, `name`) VALUES (66666, '赵先生');
INSERT INTO `customer` (`id`, `name`) VALUES (77777, '钱先生');
INSERT INTO `customer` (`id`, `name`) VALUES (166666, '孙先生');
INSERT INTO `customer` (`id`, `name`) VALUES (177777, '李先生');
INSERT INTO `customer` (`id`, `name`) VALUES (266666, '周先生');
INSERT INTO `customer` (`id`, `name`) VALUES (277777, '吴先生');
然后查看:
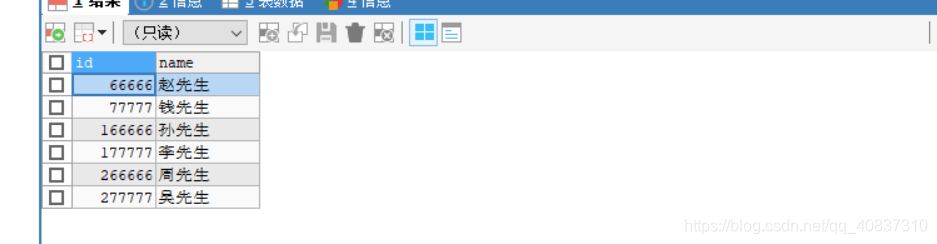
在mycat上面查询出了完整的数据,但是具体分在哪个节点还要看看。
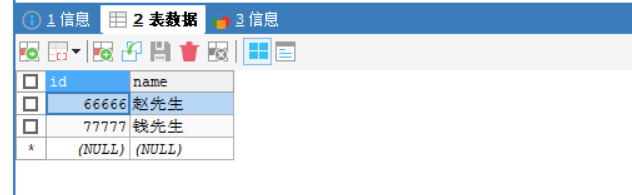
节点0:
节点1:
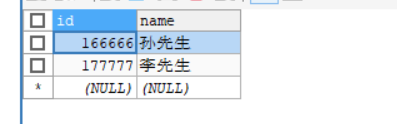
节点2:因为266666和277777在范围外,所以会分片到默认节点。
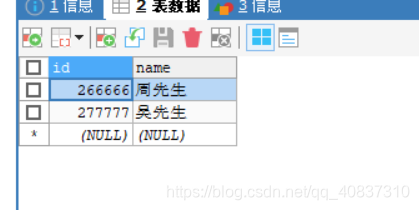
可以看到跟range-shard-long.txt文件配置的范围规则是一致的。
ER分片
schema.xml文件的schema标签配置对应的表和分片规则(在上面基础上):
<!--rule配置分片规则为mod-long-order,实际上就是一个取模的分配规则,关联字段取模,就能分片到相同的节点上 -->
<table name="order_info" dataNode="dn1,dn2,dn3" rule="mod-long-order" >
<!-- joinKey是子表与父表关联的字段,这里是order_id -->
<!-- parentKey是对应的是父表与子表关联的字段 -->
<childTable name="order_detail" joinKey="order_id" parentKey="order_id" primaryKey="id"/>
</table>
配置分片规则
<tableRule name="mod-long-order">
<rule>
<columns>order_id</columns>
<algorithm>mod-long-order</algorithm>
</rule>
</tableRule>
<function name="mod-long-order" class="io.mycat.route.function.PartitionByMod">
<!-- 节点个数,用于取模 -->
<property name="count">3</property>
</function>
重启mycat并连接执行下面SQL。
INSERT INTO `order_info` (`order_id`, `uid`, `nums`, `state`, `create_time`, `update_time`) VALUES (1, 1000001, 1, 2, '2019-9-23 14:35:37', '2019-9-23 14:35:37');
INSERT INTO `order_info` (`order_id`, `uid`, `nums`, `state`, `create_time`, `update_time`) VALUES (2, 1000002, 1, 2, '2019-9-24 14:35:37', '2019-9-24 14:35:37');
INSERT INTO `order_info` (`order_id`, `uid`, `nums`, `state`, `create_time`, `update_time`) VALUES (3, 1000003, 3, 1, '2019-9-25 11:35:49', '2019-9-25 11:35:49');
--------------------------------------------------------------------------
INSERT INTO `order_detail` (`order_id`, `id`, `goods_id`, `price`, `is_pay`, `is_ship`, `status`) VALUES (3, 20180001, 85114752, 19.99, 1, 1, 1);
INSERT INTO `order_detail` (`order_id`, `id`, `goods_id`, `price`, `is_pay`, `is_ship`, `status`) VALUES (1, 20180002, 25411251, 1280.00, 1, 1, 0);
INSERT INTO `order_detail` (`order_id`, `id`, `goods_id`, `price`, `is_pay`, `is_ship`, `status`) VALUES (1, 20180003, 62145412, 288.00, 1, 1, 2);
INSERT INTO `order_detail` (`order_id`, `id`, `goods_id`, `price`, `is_pay`, `is_ship`, `status`) VALUES (2, 20180004, 21456985, 399.00, 1, 1, 2);
INSERT INTO `order_detail` (`order_id`, `id`, `goods_id`, `price`, `is_pay`, `is_ship`, `status`) VALUES (2, 20180005, 21457452, 1680.00, 1, 1, 2);
INSERT INTO `order_detail` (`order_id`, `id`, `goods_id`, `price`, `is_pay`, `is_ship`, `status`) VALUES (2, 20180006, 65214789, 9999.00, 1, 1, 3);
mycat查看两个表:

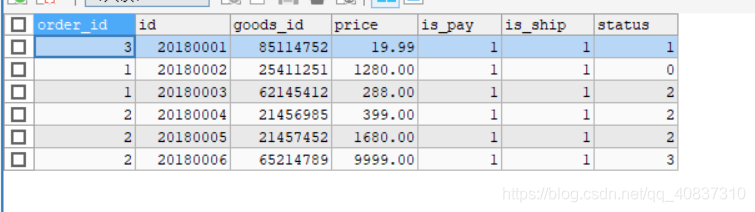
数据完整,然后查看每个节点。
节点1:


节点2:
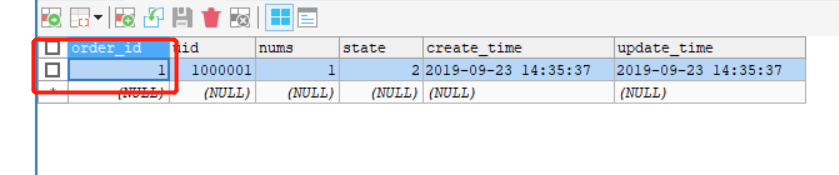
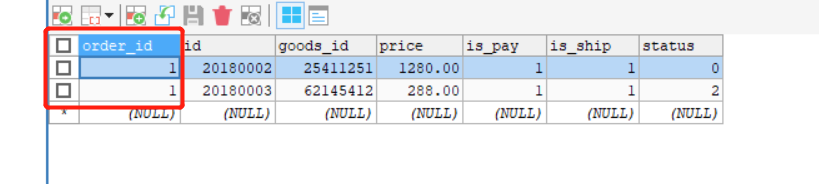
节点3:

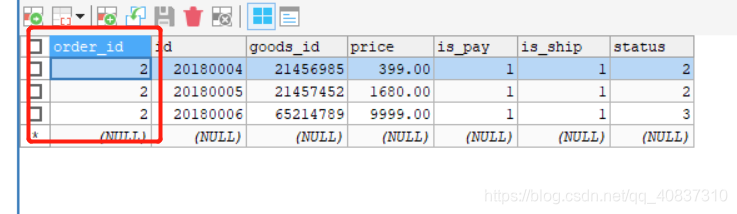
可以看到每个节点的两个表的order_id都是对应的,这样的绑定关系就避免了跨库的关联查询。
全局表
这个无需分配规则,只需加多个属性type="global"就行。
<table name="student" dataNode="dn1,dn2,dn3" primaryKey="sid" type="global"/>
重启mycat并连接执行下面语句
INSERT INTO `student` (`sid`, `name`, `qq`) VALUES (1, '黑白', '166669999');
INSERT INTO `student` (`sid`, `name`, `qq`) VALUES (2, 'AV哥', '466669999');
INSERT INTO `student` (`sid`, `name`, `qq`) VALUES (3, '地表最强菜鸟', '368828888');
INSERT INTO `student` (`sid`, `name`, `qq`) VALUES (4, '加载中', '655556666');
INSERT INTO `student` (`sid`, `name`, `qq`) VALUES (5, '猫老公', '265286999');
INSERT INTO `student` (`sid`, `name`, `qq`) VALUES (6, '一个人的精彩', '516895555');
然后查看mycat数据:
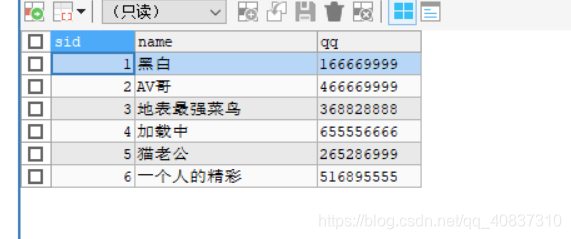
查看三个节点:
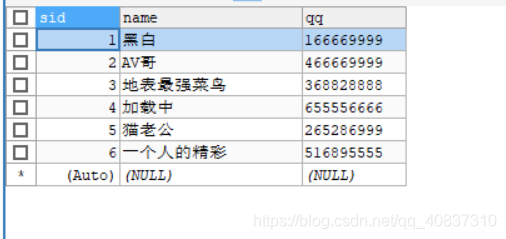
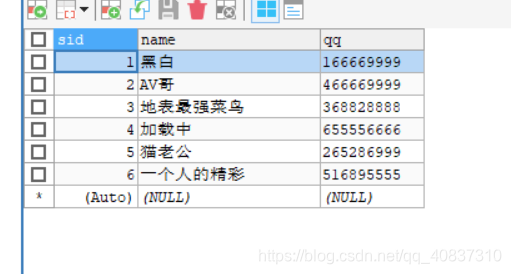
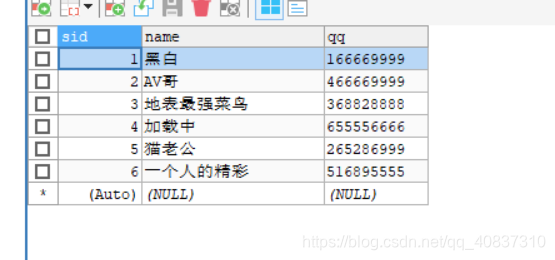
可以看到所有节点都保存了全量数据。
取模分片
取模分片就不演示了,ER分片那里的实质就是取模分片。
日期分片
按自然月进行分片:
先修改schema.xml添加相关逻辑表信息。
<table name="sharding_by_month" dataNode="dn1,dn2,dn3" rule="qs-shard-by-month"/>
修改rule.xml,添加分片规则:
<tableRule name="qs-shard-by-month">
<rule>
<columns>create_time</columns>
<algorithm>shardByMonth</algorithm>
</rule>
</tableRule>
<function name="shardByMonth"
class="io.mycat.route.function.PartitionByMonth">
<!-- 日期格式,数据表的对应字段的格式要与这里设置的一致 -->
<property name="dateFormat">yyyy-MM-dd</property>
<!-- 开始日期-->
<property name="sBeginDate">2019-10-01</property>
<!-- 结束日期-->
<property name="sEndDate">2019-12-31</property>
</function>
重启mycat并连接执行下面语句:
INSERT INTO sharding_by_month (create_time,db_nm) VALUES ('2019-10-16', database());
INSERT INTO sharding_by_month (create_time,db_nm) VALUES ('2019-10-27', database());
INSERT INTO sharding_by_month (create_time,db_nm) VALUES ('2019-11-04', database());
INSERT INTO sharding_by_month (create_time,db_nm) VALUES ('2019-11-11', database());
INSERT INTO sharding_by_month (create_time,db_nm) VALUES ('2019-12-25', database());
INSERT INTO sharding_by_month (create_time,db_nm) VALUES ('2019-12-31', database());
mycat查询:
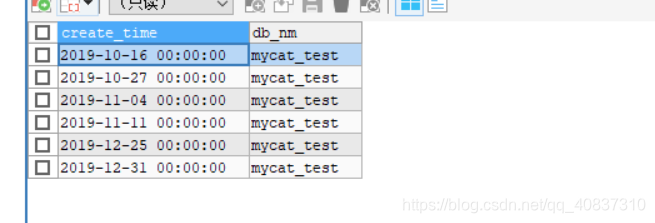
插入成功。
查看各节点数据:
节点0:保存了10月的数据
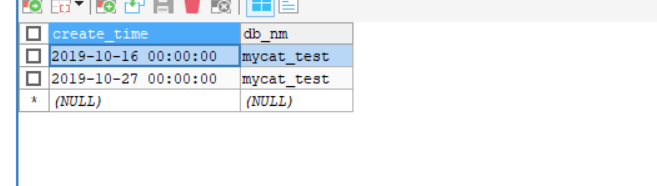
节点1:保存了11月的数据
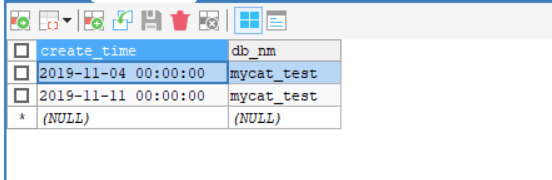
节点2:保存了12月的数据
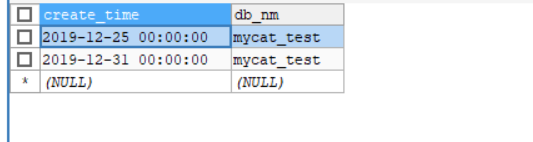
如果添加一个在开始和结束日期之外的日期。

也会成功,但是分配到了最后一个节点那里,虽然也能成功,但是这个就不符合分配规则了,原本每个节点都保存一个月的数据。
所以节点数要与月份数一样或者大于月份数才能保证按月份分片。
枚举分片
就是用于分片的枚举字段的值是有限的,通过把它枚举出来分到特定的节点中。
在一些有限场景中适用,比如按地区分片,地区是有限的,可以枚举出来。
修改schema.xml添加表信息。
<table name="sharding_by_intfile" dataNode="dn1,dn2,dn3" rule="qs-shard-infile"/>
修改rule.xml,添加分片规则
<tableRule name="qs-shard-infile">
<rule>
<columns>age</columns>
<algorithm>shardInFile</algorithm>
</rule>
</tableRule>
<function name="shardInFile" class="io.mycat.route.function.PartitionByFileMap">
<!-- 枚举映射文件-->
<property name="mapFile">shardInFile.txt</property>
<!-- 类型 0位Integer型,非0位String型-->
<property name="type">0</property>
<!-- 默认节点,当存在枚举之外的值时,就分配到这个节点-->
<property name="defaultNode">0</property>
</function>
创建shardInFile.txt文件:
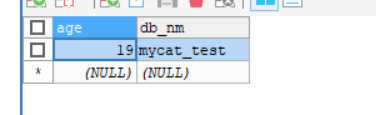
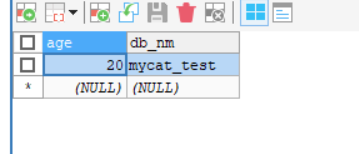
#这里仅仅枚举三个值,18就分到节点0,19就节点1,20就节点2
18=0
19=1
20=2
重启mycat并连接执行如下语句
INSERT INTO `sharding_by_intfile` (age,db_nm) VALUES (19, DATABASE());
INSERT INTO `sharding_by_intfile` (age,db_nm) VALUES (20, DATABASE());
INSERT INTO `sharding_by_intfile` (age,db_nm) VALUES (18, DATABASE());
INSERT INTO `sharding_by_intfile` (age,db_nm) VALUES (30, DATABASE());
mycat查询数据:

4条数据。
然后查看各节点数据。
节点0:
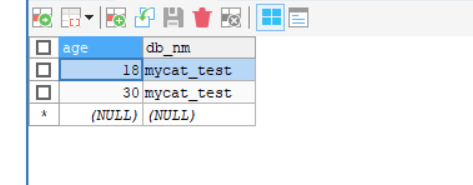
枚举18分到节点0,30在枚举之外,分到默认节点0,符合。
节点1:
节点2:
一致性哈希分片
一致性哈希的知识要另外自己了解,总的来说就是通过节点哈希在一个闭环里面表示一段范围,然后数据会落到相应的地方。分布比较均匀并且在扩容缩容时只需对圆环的下一个节点进行数据迁移即可,可以减少数据的迁移量。
先修改schema.xml,添加相应逻辑表信息。
<table name="sharding_by_murmur" dataNode="dn1,dn2,dn3" rule="qs-shard-murmur" primaryKey="id"/>
修改rule.xml,定义分片规则:
<tableRule name="qs-shard-murmur">
<rule>
<columns>id</columns>
<algorithm>shardMurMur</algorithm>
</rule>
</tableRule>
<function name="shardMurMur"
class="io.mycat.route.function.PartitionByMurmurHash">
<property name="seed">0</property>
<!-- 配置节点个数,要准确-->
<property name="count">3</property>
<!-- 虚拟节点个数,因为如果只有三个节点的话,会使得数据分布不均匀,需要配置虚拟节点来使得数据分布均匀,具体看一致性哈希相关知识就能理解了 -->
<property name="virtualBucketTimes">160</property>
</function>
重启mycat连接并执行下面语句:
INSERT INTO `sharding_by_murmur` (id,db_nm) VALUES (1, database());
INSERT INTO `sharding_by_murmur` (id,db_nm) VALUES (2, database());
INSERT INTO `sharding_by_murmur` (id,db_nm) VALUES (3, database());
INSERT INTO `sharding_by_murmur` (id,db_nm) VALUES (4, database());
INSERT INTO `sharding_by_murmur` (id,db_nm) VALUES (5, database());
INSERT INTO `sharding_by_murmur` (id,db_nm) VALUES (6, database());
INSERT INTO `sharding_by_murmur` (id,db_nm) VALUES (7, database());
INSERT INTO `sharding_by_murmur` (id,db_nm) VALUES (8, database());
INSERT INTO `sharding_by_murmur` (id,db_nm) VALUES (9, database());
INSERT INTO `sharding_by_murmur` (id,db_nm) VALUES (10, database());
INSERT INTO `sharding_by_murmur` (id,db_nm) VALUES (11, database());
INSERT INTO `sharding_by_murmur` (id,db_nm) VALUES (12, database());
INSERT INTO `sharding_by_murmur` (id,db_nm) VALUES (13, database());
INSERT INTO `sharding_by_murmur` (id,db_nm) VALUES (14, database());
INSERT INTO `sharding_by_murmur` (id,db_nm) VALUES (15, database());
INSERT INTO `sharding_by_murmur` (id,db_nm) VALUES (16, database());
INSERT INTO `sharding_by_murmur` (id,db_nm) VALUES (17, database());
INSERT INTO `sharding_by_murmur` (id,db_nm) VALUES (18, database());
INSERT INTO `sharding_by_murmur` (id,db_nm) VALUES (19, database());
INSERT INTO `sharding_by_murmur` (id,db_nm) VALUES (20, database());
mycat查询:
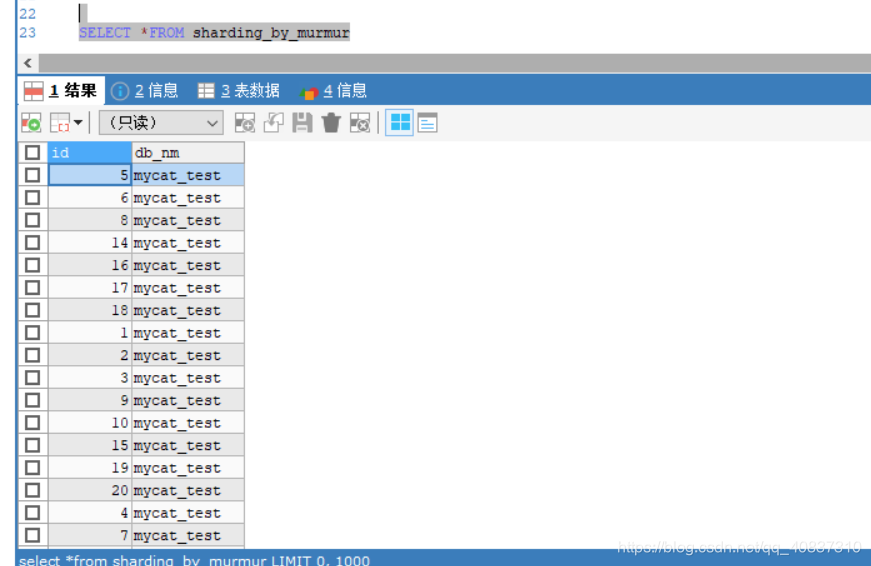
汇总了插入的20条数据。
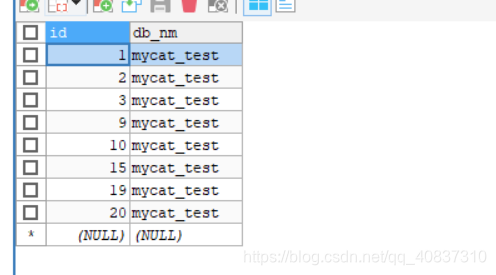
查看各节点数据:
节点0:7条数据
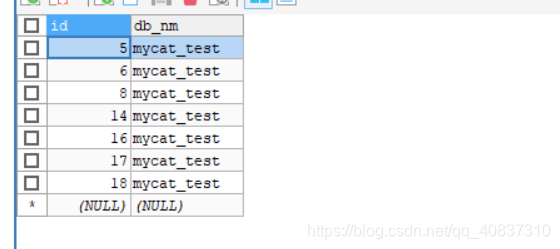
节点1:8条数据
节点2:5条数据
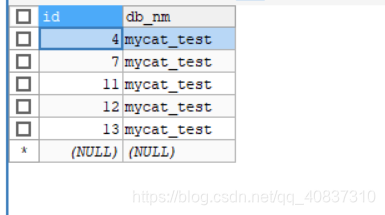
也算比较均匀了。
固定分配哈希
跟redis集群的哈希槽类似,共1024个槽,然后每个节点会分到一定的哈希槽,数据对槽数进行哈希取模计算得到一个槽数。就分配到管理该哈希槽的节点上。
先修改schema.xml添加表信息:
<table name="sharding_by_long" dataNode="dn1,dn2,dn3" rule="qs-shard-long" primaryKey="id"/>
修改rule.xml定义分片规则
<tableRule name="qs-shard-long">
<rule>
<columns>id</columns>
<algorithm>shardLong</algorithm>
</rule>
</tableRule>
<function name="shardLong"
class="io.mycat.route.function.PartitionByLong">
<!-- 三个节点,第一个节点分配256个槽,第二个节点分配256个槽,第三个节点分配512个槽,一一对应 -->
<property name="partitionCount">1,1,1</property>
<property name="partitionLength">256,256,512</property>
</function>

重启mycat连接并执行下面语句:
INSERT INTO `sharding_by_long` (id,db_nm) VALUES (222, DATABASE());
INSERT INTO `sharding_by_long` (id,db_nm) VALUES (333, DATABASE());
INSERT INTO `sharding_by_long` (id,db_nm) VALUES (666, DATABASE());
mycat查询数据:数据已经插入成功。
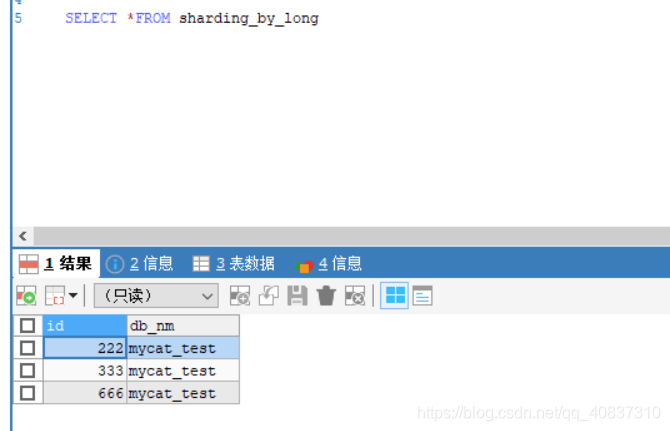
查看各节点数据:
节点0:222%1024=222,222槽是归节点0管理,所以分配到了节点0中。
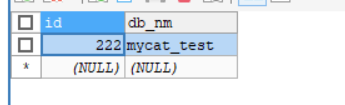
节点1:
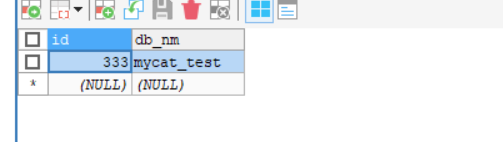
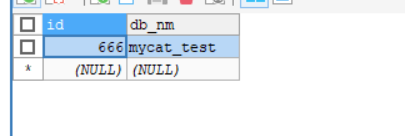
节点2:
这种分片方式的优点是如果新增节点,给新增节点分配哈希槽,只需迁移哈希槽对应的数据即可。

















 1146
1146

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









