







一次完整的HTTP请求过程(深入分析)
当我们开始在浏览器中输入网址的时候,浏览器其实就已经在智能的匹配可能得 url 了,他会从历史记录,书签等地方,找到已经输入的字符串可能对应的 url,然后给出智能提示,让你可以补全url地址。对于 google的chrome 的浏览器,他甚至会直接从缓存中把网页展示出来,就是说,你还没有按下 enter,页面就出来了。
- 域名解析
如果浏览器曾经访问过该地址,那么该域名的 ip 地址(112.34.112.40)就会形成映射关系保存在 dns 服务器中,同时还缓存在浏览器和 hosts 文件里。
当域名解析时,浏览器会先去本地缓存中找 ip 地址,如果没有就去 hosts 文件中找,找到就键入ip地址。如果还是没有,那么就会向本地 dns 服务器的缓存中查找,如果仍然没有,最后就去顶级域 dns 进行查询并逐级返回了。
1)首先会搜索浏览器自身的DNS缓存(缓存时间比较短,大概只有1分钟,且只能容纳1000条缓存)
2)如果浏览器自身的缓存里面没有找到,那么浏览器会搜索操作系统自身的DNS缓存,其实操作系统也会有一个域名解析的过程,在Windows中可以通过C:\Windows\System32drivers\etc\hosts文件来设置,你可以将任何域名解析到任何能够访问的IP地址。如果你在这里指定了一个域名对应的IP地址,那么浏览器会首先使用这个IP地址。
在Linux中这个配置文件是/etc/hosts,修改这个文件可以达到同样的目的。操作系统会在缓存中缓存这个解析结果,缓存的时间同样是受这个域名的失效时间和缓存的空间大小控制的。小总结:
前面这两个步骤都是在本机完成的,所以在图1-10中没有表示出来。到这里还没有涉及真正的域名解析服务器,如果在本机中仍然无法完成域名的解析,就会真正请求域名服务器来解析这个域名了。3)在我们的网络配置中都会有“DNS服务器地址”这一项,这个地址就用于解决前面所说的如果两个过程无法解析时要怎么办,操作系统会把这个域名发送给这里设置的LDNS(Local
DNS),也就是本地区的域名服务器。(这个DNS通常都提供给你本地互联网接入的一个DNS解析服务,例如你是在学校接入互联网,那么你的DNS服务器肯定在你的学校,如果你是在一个小区接入互联网的,那这个DNS就是提供给你接入互联网的应用提供商,即电信或者联通,也就是通常所说的SPA)小总结:这个专门的域名解析服务器性能都会很好,它们一般都会缓存域名解析结果,当然缓存时间是受域名的失效时间控制的,一般缓存空间不是影响域名失效的主要因素。大约80%的域名解析都到这里就已经完成了,所以LDNS主要承担了域名的解析工作。
4)如果LDNS仍然没有命中,就直接到RootServer域名服务器请求解析。
5)根域名服务器返回给本地域名服务器一个所 查询域的主域名服务器(gTLdServer)地址。gTLD是国际顶级域名服务器,如.com、
.cn、.org 等,全球只有(台左右。6)本地域名服务器(Local DNS Server) 再向上-步返回的gTLD服务器发送请求。
7)接受请求的gTLD服务器查找并返回此域名对应的Name Server域名服务器的地址,这个Name
Server通常就是你注册的域名服务器,例如你在某个域名服务提供商申请的域名,那么这个域名解析任务就由这个域名提供商的服务器来完成。8)NameServer域名服务器会查询存储的域名和IP的映射关系表,在正常情况下都根据域名得到目标IP记录,连同一个TTl值返回给DNS
Server域名服务器。9)返回该域名对应的IP和TTL值,Local DNS Server 会缓存这个域名和IP的对应关系,缓存的时间由TTL值控制。
10)把解析的结果返回给用户,用户根据TTL值缓存在本地系统缓存中,城解析过程结束。
在实际的DNS解析过程中,可能还不止这10个步骤,如Name
Sever也可能有多或者有一个GTM来负载均衡控制,这都有可能会影响域名解析的过程。总结: 一般情况前5步是可以解析出域名的。
- 获取端口号
浏览器获取 80 端口。如果是 https 协议,端口号为 443。拿到域名对应的IP地址之后,浏览器会以一个随机端口(1024<端口<65535)向服务器的WEB程序(常用的有httpd,nginx等)80端口发起TCP的连接请求。这个连接请求到达服务器端后(这中间通过各种路由设备,局域网内除外),进入到网卡,然后是进入到内核的TCP/IP协议栈(用于识别该连接请求,解封包,一层一层的剥开),还有可能要经过Netfilter防火墙(属于内核的模块)的过滤,最终到达WEB程序,最终建立了TCP/IP的连接。 - 建立TCP连接
- 发送请求
客户端向服务器发起http请求的时候,会有一些请求信息,请求信息包含三个部分:
请求方法URI协议/版本
请求头(Request Header)
请求正文:
下面是一个完整的HTTP请求例子:
进过TCP3次握手之后,浏览器发起了http的请求
HTTP请求报文格式(HTTP请求报文由3部分组成(请求行+请求头+请求体))
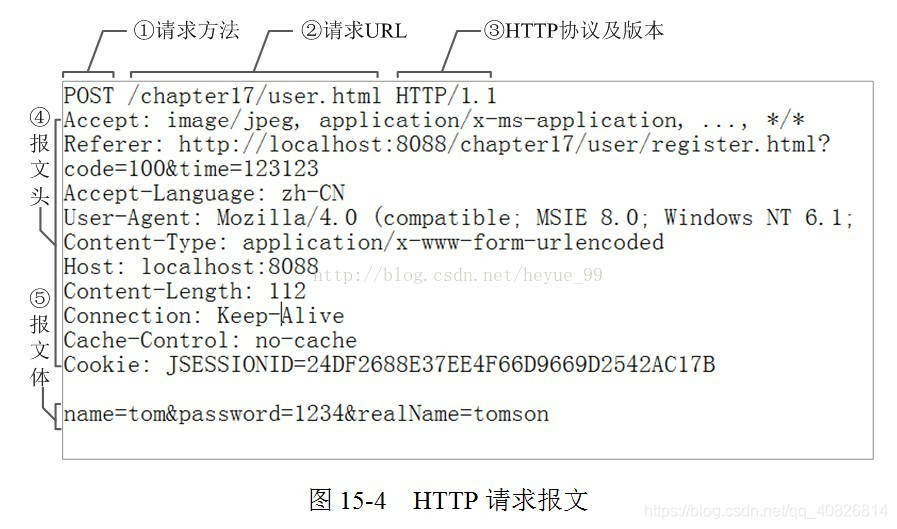
请求行:
①是请求方法,GET和POST是最常见的HTTP方法,除此以外还包括DELETE、HEAD、OPTIONS、PUT、TRACE。
②为请求对应的URL地址,它和报文头的Host属性组成完整的请求URL。
③是协议名称及版本号。
请求头:
④是HTTP的报文头,报文头包含若干个属性,格式为“属性名:属性值”,服务端据此获取客户端的信息。
与缓存相关的规则信息,均包含在header中
请求体:
⑤是报文体,它将一个页面表单中的组件值通过param1=value1¶m2=value2的键值对形式编码成一个格式化串,它承载多个请求参数的数据。不但报文体可以传递请求参数,请求URL也可以通过类似于“/chapter15/user.html?param1=value1¶m2=value2”的方式传递请求参数。
什么是URL、URI、URN?
URI :Uniform Resource Identifier 统一资源标识符
URL:Uniform Resource Locator 统一资源定位符
URN: Uniform Resource Name 统一资源名称
URL和URN 都属于 URI
成功建立连接后,浏览器向服务器发送请求。
- 处理请求
后端从在固定的端口接收到TCP报文开始,它会对TCP连接进行处理,对HTTP协议进行解析,并按照报文格式进一步封装成HTTP Request对象,供上层使用。
一些大一点的网站会将你的请求到反向代理服务器中,因为当网站访问量非常大,网站越来越慢,一台服务器已经不够用了。于是将同一个应用部署在多台服务器上,将大量用户的请求分配给多台机器处理。此时,客户端不是直接通过HTTP协议访问某网站应用服务器,而是先请求到Nginx,Nginx再请求应用服务器,然后将结果返回给客户端,这里Nginx的作用是反向代理服务器。同时也带来了一个好处,其中一台服务器万一挂了,只要还有其他服务器正常运行,就不会影响用户使用。
服务器接收到请求并分析处理请求。
- 返回结果
也就是返回一个HTPP响应。
HTTP响应与HTTP请求相似,HTTP响应也由3个部分构成,分别是:
HTTP响应也由三部分组成:状态码,响应头和实体内容
1.状态码:状态码用于表示服务器对请求的处理结果
2.响应头:响应头用于描述服务器的基本信息,以及客户端如何处理数据
3.实体内容:服务器返回给客户端的数据
HTTP/1.1 200 OK
Date: Sat, 31 Dec 2005 23:59:59 GMT
Content-Type: text/html;charset=ISO-8859-1
Content-Length: 122
<html>
<head>
<title>http</title>
</head>
<body>
<!-- body goes here -->
</body>
</html>
响应正文
包含着我们需要的一些具体信息,比如cookie,html,image,后端返回的请求数据等等。这里需要注意,响应正文和响应头之间有一行空格,表示响应头的信息到空格为止,下图是fiddler抓到的请求正文,红色框中的:响应正文:
服务器将请求的数据结果返回给浏览器。
8、浏览器显示 HTML
解析html以构建dom树 -> 构建render树 -> 布局render树 -> 绘制render树
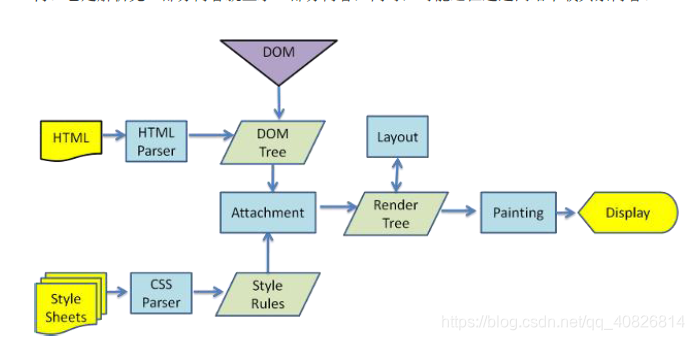
浏览器在解析html文件时,会”自上而下“加载,并在加载过程中进行解析渲染。在解析过程中,如果遇到请求外部资源时,如图片、外链的CSS、iconfont等,请求过程是异步的,并不会影响html文档进行加载。
解析过程中,浏览器首先会解析HTML文件构建DOM树,然后解析CSS文件构建渲染树,等到渲染树构建完成后,浏览器开始布局渲染树并将其绘制到屏幕上。这个过程比较复杂,涉及到两个概念: reflow(回流)和repain(重绘)。
DOM节点中的各个元素都是以盒模型的形式存在,这些都需要浏览器去计算其位置和大小等,这个过程称为relow;当盒模型的位置,大小以及其他属性,如颜色,字体,等确定下来之后,浏览器便开始绘制内容,这个过程称为repain。
页面在首次加载时必然会经历reflow和repain。reflow和repain过程是非常消耗性能的,尤其是在移动设备上,它会破坏用户体验,有时会造成页面卡顿。所以我们应该尽可能少的减少reflow和repain。
当文档加载过程中遇到js文件,html文档会挂起渲染(加载解析渲染同步)的线程,不仅要等待文档中js文件加载完毕,还要等待解析执行完毕,才可以恢复html文档的渲染线程。因为JS有可能会修改DOM,最为经典的document.write,这意味着,在JS执行完成前,后续所有资源的下载可能是没有必要的,这是js阻塞后续资源下载的根本原因。所以我明平时的代码中,js是放在html文档末尾的。
JS的解析是由浏览器中的JS解析引擎完成的,比如谷歌的是V8。JS是单线程运行,也就是说,在同一个时间内只能做一件事,所有的任务都需要排队,前一个任务结束,后一个任务才能开始。但是又存在某些任务比较耗时,如IO读写等,所以需要一种机制可以先执行排在后面的任务,这就是:同步任务(synchronous)和异步任务(asynchronous)。
JS的执行机制就可以看做是一个主线程加上一个任务队列(task queue)。同步任务就是放在主线程上执行的任务,异步任务是放在任务队列中的任务。所有的同步任务在主线程上执行,形成一个执行栈;异步任务有了运行结果就会在任务队列中放置一个事件;脚本运行时先依次运行执行栈,然后会从任务队列里提取事件,运行任务队列中的任务,这个过程是不断重复的,所以又叫做事件循环(Event loop)。
8. 断开连接(四次挥手)
第一次挥手:Client将FIN置为1,发送一个序列号seq给Server;进入FIN_WAIT_1状态;
第二次挥手:Server收到FIN之后,发送一个ACK=1,acknowledge number=收到的序列号+1;进入CLOSE_WAIT状态。此时客户端已经没有要发送的数据了,但仍可以接受服务器发来的数据。
第三次挥手:Server将FIN置1,发送一个序列号给Client;进入LAST_ACK状态;
第四次挥手:Client收到服务器的FIN后,进入TIME_WAIT状态;接着将ACK置1,发送一个acknowledge number=序列号+1给服务器;服务器收到后,确认acknowledge number后,变为CLOSED状态,不再向客户端发送数据。客户端等待2*MSL(报文段最长寿命)时间后,也进入CLOSED状态。完成四次挥手。

















 628
628

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









