



目标
使用文本分类对搜索关键词进行分类,提高搜索的准确性。
项目地址:https://github.com/AriesYB/Chinese-Text-Classification-Pytorch.git
数据准备
由于事先没有记录用户关键词,但是用户搜索的词语大都属于商品的类目、品牌、型号、关键参数等,商品名称(标题)包含了这些要素,所以以商品名称作为训练文本,类目作为标签。
数据预处理
拿到数据以后,去掉商品名称中特殊符号,并去重,按照每个类目按照 7:2:1,划分训练集 train、验证集 dev 和测试集 test。
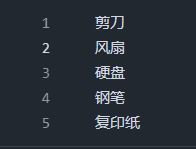
导出数据,类目每一行一条导出 class.txt,例如:
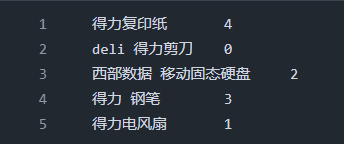
数据集则按照每一行 商品名称\t类目行号 的格式导出 train.txt、dev.txt、test.txt,例如:
训练
代码地址 TextCNN,TextRNN,FastText,TextRCNN,BiLSTM_Attention, DPCNN, Transformer, 基于pytorch
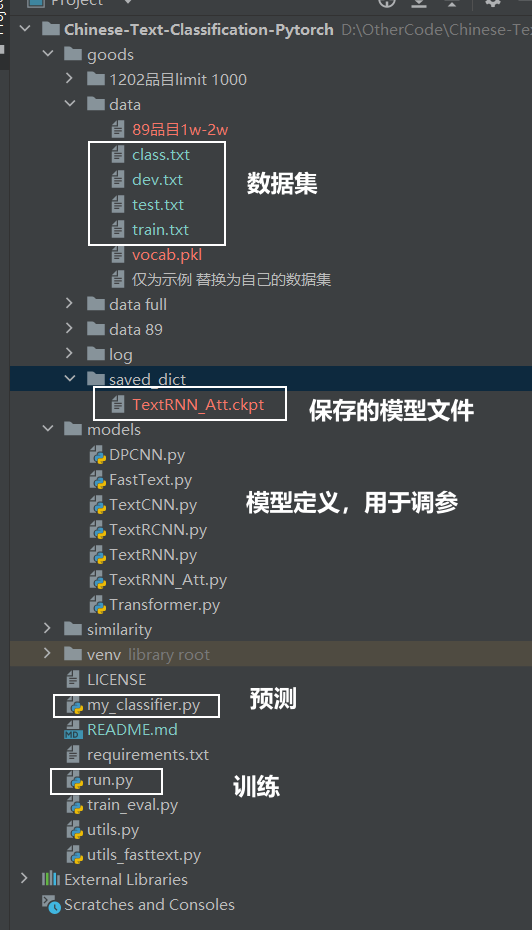
命令行参数

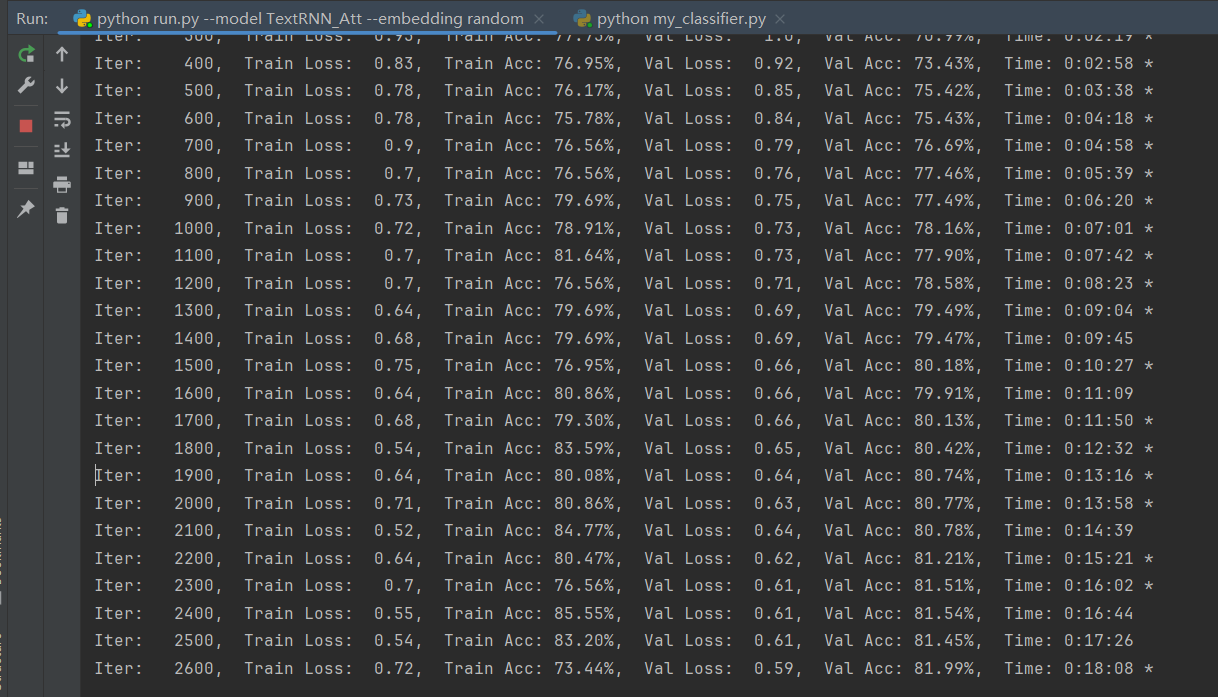
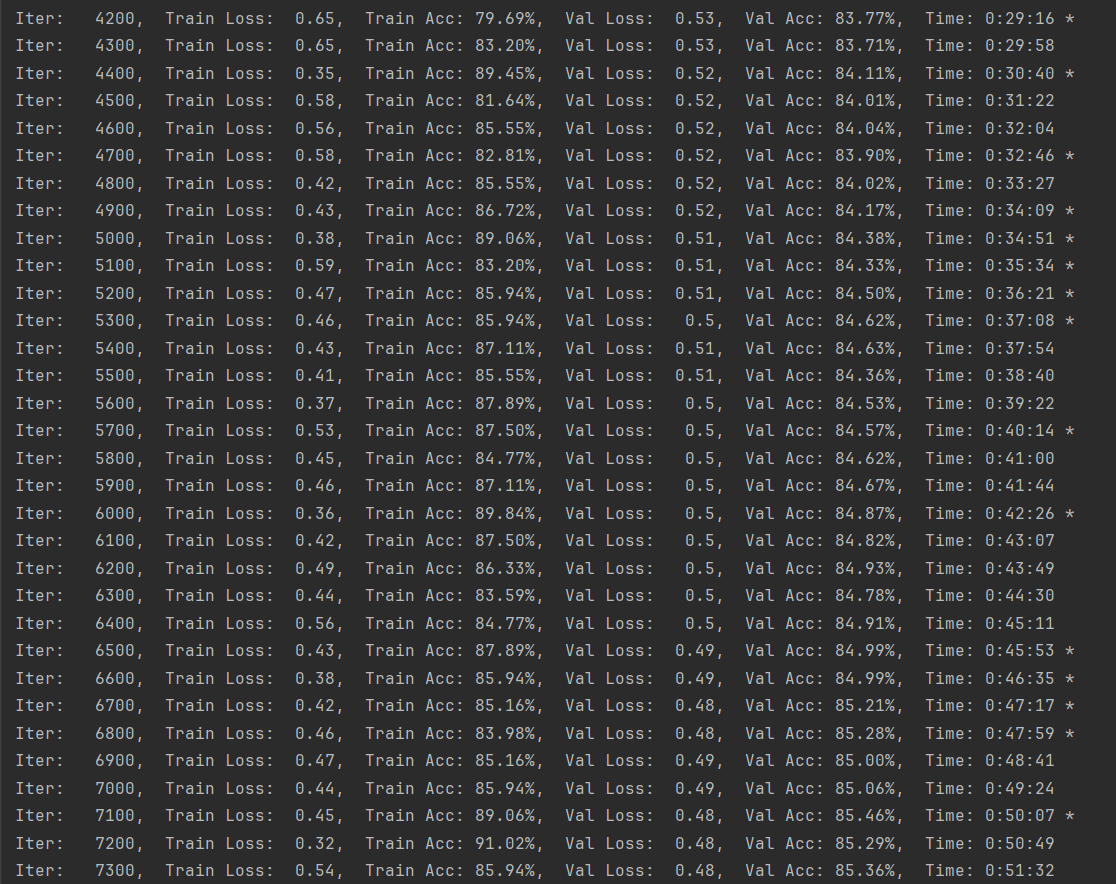
例如使用 TextRNN_Att 训练,不使用分词,随机embedding。日志中有 * 号的表示有提升。准确率不再提升时则训练结束,计算评价指标。
python run.py --model TextRNN_Att --embedding random
模型使用
python my_classifier.py
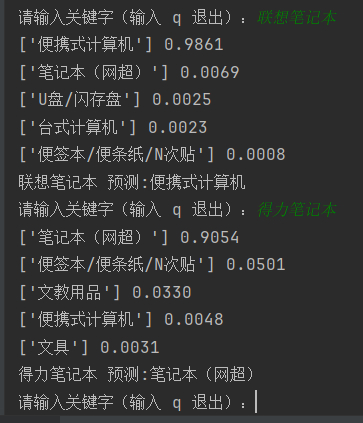
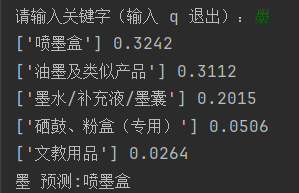
分类结果的概率的和为1,所以实际使用时,对于概率都很低的情况下,应该选取多个或者不使用分类结果。概率都很低也可能是数据集分类不清晰的问题。
其他事项




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









