




 本文介绍如何使用Python模拟登录URP教务系统,包括获取cookies、处理验证码、构建post数据并提交,以及识别验证码的方法。通过分析网络请求,设置headers和cookie,实现对教务系统页面的模拟访问。最后展示了验证码的人工识别和登录成功的验证,例如通过查询课表功能。
本文介绍如何使用Python模拟登录URP教务系统,包括获取cookies、处理验证码、构建post数据并提交,以及识别验证码的方法。通过分析网络请求,设置headers和cookie,实现对教务系统页面的模拟访问。最后展示了验证码的人工识别和登录成功的验证,例如通过查询课表功能。
本文转自本人简书内容详情
选课功能已经更新
前言
前段时间,小编抓取了搜狐新闻网某网页的内容,并作词云分析,感觉很是爬虫有趣。最近突然心血来潮想要爬取一下我们学校的教务系统抓取课表。
#思路解析
A 、先打开登陆页面,获取cookies;B、再访问验证码的地址,因为验证码是动态的,每次打开都是不同的,所以我们需要保存之前的cookie,保证获取的验证码和后续要提交的表单是同步的。C、然后就是识别验证码的环节,登陆成功后为了避免网页的重定向,所以还需要用requests的session函数禁止重定向。D、构建post表单请求数据,然后将数据提交给网站 F、获取响应头信息,通过返回的网页内容来判断是否登陆成功。
模拟登陆
在开题之前,先带大家认识一下:浏览器请求网页的流程。
在web应用中,服务器把网页传给浏览器,实际上就是把网页的HTML发送给浏览器。但是在没有携带cookie的情况下,如果IP短时间高并发的请求网站,该IP就会被封。这里解释一下cookie,cookie是一种回话机制,可以用来存储很多信息,也经常用于反爬。我们一般处理cookie有两种方法:1、cookie的保存 2、cookie的读取。然后登陆部分的处理通常采用的方法就是将爬虫模拟成浏览器,有:1、通过opener添加headers 2、通过requests添加headers 3、批量添加headers 。小编采用的是第二种方法。
用浏览器打开教务处系统的界面如下:
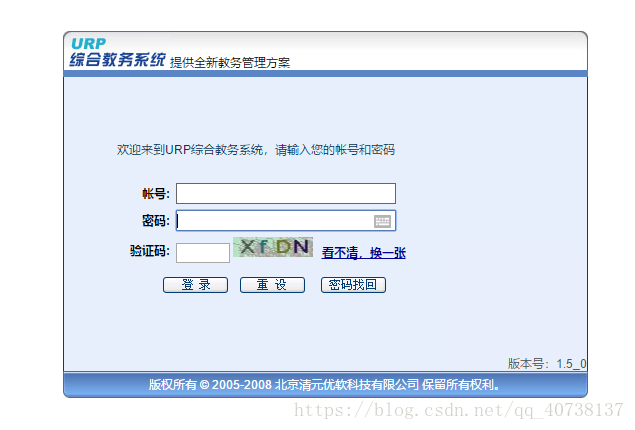
上面提到的headers,cookie等参数的获取,也是有两种方法获取。1、在登陆页面按F12进入开发者模式,选择network,再选中preserve log,选中login页面
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









