






四类SQL通用:mysql、sqlserver、oracle、postgresql
select
select a from tableA where a=a1:
运算:
select a*3 b from tableA;
使用()来定义运算优先级。
别名
select a as xx from tableA;可以不加as,仅为增加可读性。
别名不可以中间有空格,
别名不可以有特殊符号,
别名不可以用关键字,
但是以上问题都可以被" "解决。
课后题:搜索empno,输出为员工号;搜索salary,输出为月薪;搜索salary,乘14后输出为14薪。
select empno 员工号,salary 月薪,salary*14 14薪 from emplyees;
distinct 去重复值;
select distinct a from tableA;
where
五种运算符。=\>\<\!=\<=\>=
select a from employees where a=a1;
select * from employees where hire_date<‘2010-01-01’
// where < 居然可以比较data
课后题:提取表格中雇佣时间在2020年1月1日前的员工,输出他们的姓名、薪资、增加10%收入后薪资和入职时间;
select name,salary,salary*1.1 as “updated salary”,hire_date from empolyees where hire_date<‘2010-01-01’
and or not
and-且:select * from empolyees where deptno=3 and salary>10000;
or-或:select * from empolyees where deptno=3 or salary>10000;
and与or叠加:and优先级更高。
select * from employees where deptno=3 or salary>10000 and hire_date>‘2020-01-01’
等同于:
select * from employees where deptno=3 or (salary>10000 and hire_date>‘2020-01-01’)
not与or叠加:
not (A or B)=not A and not B
课后练习:用2种语句写出符合条件的sql。一种用not,一种不用not
查询员工表中部门号不是3且工资大于15000的员工。
select * from employees where not (deptno=3 or salary<=15000);
select * from employees where deptno!=3 and salary>15000;
IN键匹配多个值:
select * from employees where deptno in (1,2,3)
等价于
select * from employees where deptno=1 or deptno=2 or deptno=3
not in:符合集合的部分都排除。
**
not in 无法对null进行判断。这个题目的答案是???
**
如何
between指定范围:
select * from employees where hire_data>=‘2013-01-01’ and hire_data<=‘2015-01-01’
等价于
select * from employees where hire_data between ‘2013-01-01’ and ‘2015-01-01’
not between:区间范围内的排除;
课后练习:
查询工资在10000和15000之间的员工;
select * from employees where salary between 10000 and 15000;
like搜索匹配的字符串:
select * from employees where name like ‘%卫’;
李%:搜索任意长度的李某,如李大,李世民,李文强。
%卫%:搜索任何含有卫的名字,不管是第一、中间、结尾。百分号可以为空。卫大、赵卫华、大卫。
select * from employees where email like ‘__a%’;`
查询所有email邮箱第三位为a的email。前面的__只需要能够空出位置即可,内容不关注,有两个_,空出2个位置;后面的%匹配任意长度字符串,完全不关注。
select * from employees where email like ‘%@qq.com’;`
查出使用qq邮箱的员工。
select * from employees where email like ‘____@%’;`
查询邮箱前面使用了4个字母的员工,如qwer@qq.com
课后的练习:
查询email字段中第二个字母是h的gmail邮箱。
select * from employees where email like ‘_h%@gmail.com’;
OrderBy
默认顺序排(从小到大)
select * from employees order by salary;(默认值asc,效果一样)
降序排序(从大到小)
select * from employees order by salary desc;
使用别名进行排序;
select name,salary12 annual_salary from employees order by annual_salary;
select name,salary12 from employees order by salary*12;
多字段排序;先排deptno,再排salary,其中deptno降序,salary升序。
select name,depno,salary from employees order by deptno desc,salary asc。
使用列序号代替列名进行排序。(语义同上)
select name,deptno,salary from employees order by 2 desc,3 asc。
练习:按照部门升序和入职日期降序排员工名。
select * from employees order by deptno asc,hire_rate desc;
SQL注释:
单行注释:[-- ]
多行注释:/* */
NULL:
占位符,未知值得占位符。
NULL不等于0,不等于任何值,不等于NULL。
‘‘空值不等于NULL,’’ is not NULL。
只能用where xx is null或者xx is not null。
update时,未定义的字段,如果有默认值,会取默认值。如果指定这个有默认值的字段为NULL,会采用NULL。
update
update更新单条件条目的单字段
update employees set deptno=3 where empno=3;
update更新单条件条目的多字段
update employees set deptno=3,salary=salary+1000 where empno=3;
update改信息为默认值
update employees set salary=default where empno=3;
update使用子查询-注意多条对象需要用in而非=
把员工号为2的经理的下属工资增加100元。(表employees里只有部门号,表departments中才有经理号)
update employees set salary=salary+100 where deptno=(select deptno from departments where manageno=2);
update使用子查询查组合条件
把员工号为2、3的经理的下属工资增加100元。
错误示范:
update employees set salary=salary+100 where deptno=(select deptno from departments where manageno=2 or manageno=3);
正确示范:
update employees set salary=salary+100 where deptno in (select deptno from departments where manageno=2 or manageno=3);
update练习:给所有的经理涨10%工资。工资在employees表中,经理的号码在departments的managerno;
update employees set salary=salary*1.1 where deptno in (select distinct managerno from departments)
delete删除记录
delete from employees where deptno=9;
truncate table = delete from table;
truncate 效率是高于delete,因为truncate是一次性收回所有分配的空间,delete是一条一条删除。数据量大时会有明显的性能差距。
delete中使用子查询;
注意,子查询用in而不是用=
delete from employees where deptno in (select deptnpo from departments where loc like ‘二楼’);
课后练习
删除2号经理部门的所有员工。需要先从部门表里查出2号员工所在的部门,再在员工表里进行删除。
delete from employees where deptno in (select deptno from departments where managerno=2)
多表链接
查询员工对应的部门名(员工表在employees,只有departno。部门表在departments,有dname。
select name,dname from employees,departments where employees.deptno=departments.deptno
多表重合字段需要指定来源表。
select name,dname,departments.deptno from employees,departments where employees.deptno=departments.deptno
多表连接时的别名简写。
select name,dname,d.deptno from employees e,departments d where e.deptno=d.deptno;
三表链接。
select j.*,e.name,d.dname from employees e,departments d,job_history j where e.empno=j.empno and j.deptno=d.deptno
INNER JOIN 内连接
传统多表连接:select name,dname,e.deptno from employees e,departments d where e.deptno=d.deptno;
inner join改写:select name,dname e.deptno from employees e inner join departments d on e.deptno=d.deptno;
inner可以去掉不写。默认就是inner
select j.,e.name from job_history j join employees e on j.empno=e.empno;
练习题:使用内连接改写这个语句。三表INNER JOIN连接:select * from table a join b on b.xx=a.xx join c on c.xx=a.xx
原语句:select j.,e.name,d.name from job_histroy j,employees e,departments d where e.deptno=d.deptno and j.empno=e.empno;
改写后:select j.*,e.name,d.name from employees e join departments d,job_history j on e.deptno=d.deptno,e.empno=j.empno
改写后:select j.*,e.name,d.name from job_history j join emplyees e on e.empno=j.empno join departments d on e.deptno=d.deptno
SELF JOIN自连接
一个表使用不同的别名进行实体化,进行连接。
作用:如:查询一个表内的同名但不同号的员工:
select e1.name,e1.empno,e2.empno from employees e1 join employees e2 on e1.name=e2.name and e1.empno<> e2.empno;
这样的同名结果会在e1、e2表格里出现2次。可以做去重,把不等于<>改为大于>
如:查询历史上曾经在同一个部门一起共事过的员工,两两输出。
员工号不同,且部门号相同,且起始时间中的任意一个落在另一个时间段中间。
select j1.empno,j2.empno,j1.deptno,j1.start_rate comm_start from job_history h1 join job_history h2 on j1.deptno=j2.deptno and j1.empno<>j2.empno and j1.start_date between j2.start_date and j2.end_date
要点:1)用别名连接2个表,联合查询。2)Join语句连接3个条件,=、!=、between;3)只需要比较j1与j2的时间差,不需要比较j2与j1,因为是完全一样的数据不需要比2次。
练习:查询历史上曾经在2号部门和3号部门都工作过的员工。
select j1.empno,j2.empno,j1.name from job_history j1 join job_history_h2 on j1.empno=j2.empno and j1.deptno=2 and j2.deptno=3
OUTER JOIN外连接
内连接:必须要符合查询条件才会被输出
外连接:包括ON判断条件中没有的内容也会被输出。
左外连接:会输出左边的表的全部内容,并且显示右边表中匹配的记录。(可以省略outer,left join)
select name,dname,e.deptno from employees e left outer join departments d on e.deptno=d.deptno;
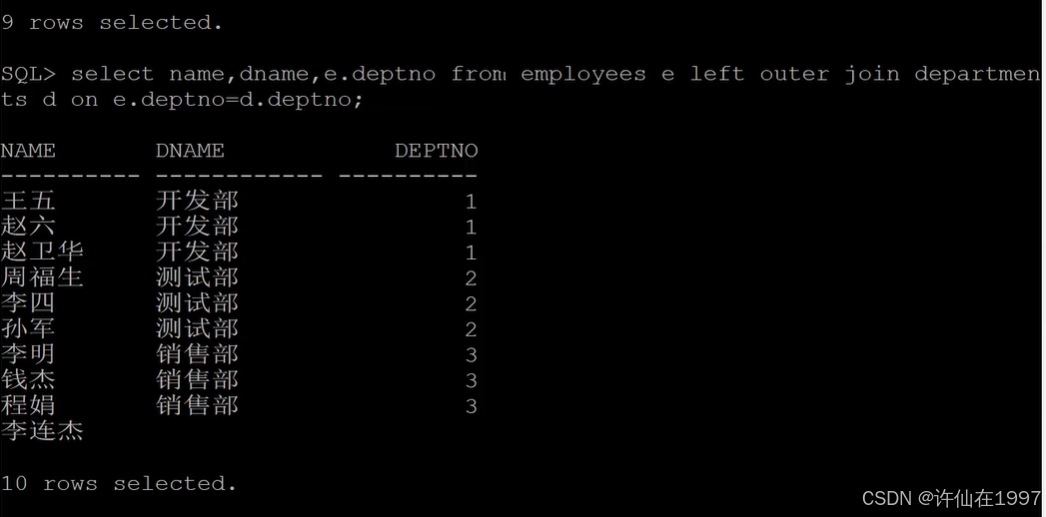
右外连接:同上,输出右边的表的全部内容,并且显示左边表中匹配的记录。(right join)
全连接:全部显示出来
select name,dname,e.deptno from employees e full join departments d on e.deptno=d.deptno;
课后练习:查询出所有员工岗位变化的记录。
select e.empno,name,start_rate,j.deptno from employees e left join job_history j on e.empno=j.empno
CORSS JOIN 交叉连接
第一个表的每一条记录会和第二个表的每条记录没有任何条件的连接。(a*b条记录)
select * from employees cross join departments order by empno;
等价于:
select * from employees,departments order by empno;
很少用,只有比如:表A是衣服表,表B是尺码表之类的
UNION集合联合
把两个表格里内容,去掉重复项,一起输出来。
select empno,deptno from employees union select managerno,deptno from departments;(9+4-3=10)
不去重显示
select empno,deptno from employees union all select managerno,deptno from departments;(9+4-3=10)
两个集合的元素个数必须一样,类型一样就可以一起输出。类型不一样不可以。
可以直接用数字而非表格字段补充。
select empno,salary from employees union select managerno,20000 from departments;
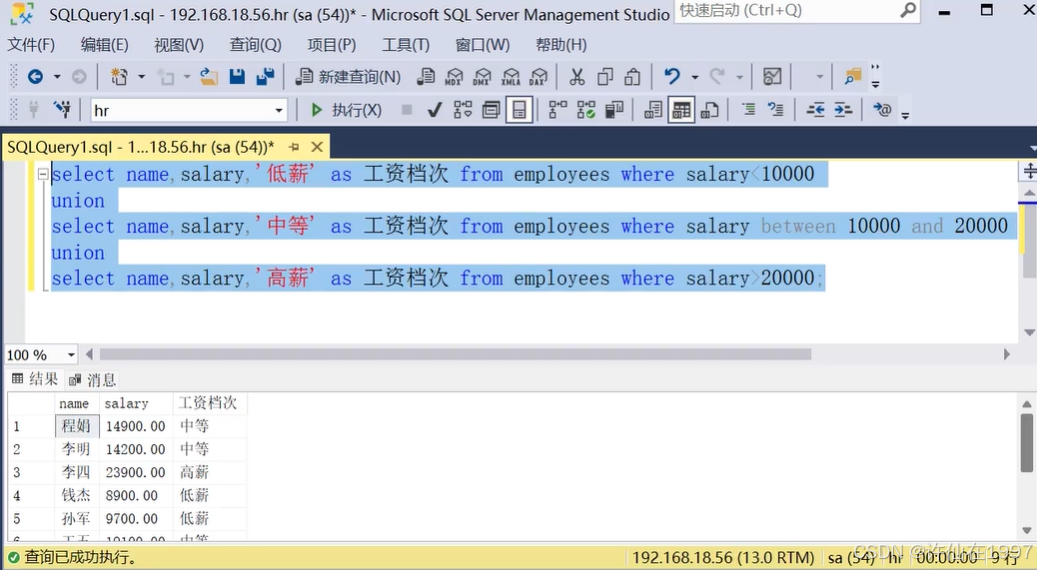
一下子把员工工资表分成低薪、中等、高薪重新输出。
课后练习:查询所有员工的姓名和入职时间,根据入职时间将员工进行分类资深程度。早于2010年入职的员工为创始人,在2010-2019期间的列为老员工,在2020年之后的列为新员工。
select name,hire_rate,“创始人” as “资深程度” from job_history where hire_date<2010-01-01
union
select name,hire_rate,“老员工” as “资深程度” from job_history where hire_date between 2010-01-01 and 2019-12-31
union
select name,hire_rate,“新员工” as “资深程度” from job_history where hire_date>2020-01-01
基本正确,as只为增加可读性,不影响正确;hire_rate,日期类型需要用’'括起来
select name,hire_date,‘创始人’ 资深程度 from employees where hire_date <‘2010-01-01’
union
select name,hire_date,‘老员工’ 资深程度 from employees where hire_date between ‘2010-01-01’ and ‘2019-12-31’
union
select name,hire_date,‘新员工’ 资深程度 from employees where hire_date >‘2019-12-31’;
常用的聚合分组函数
都不统计null值
max
min
avg
sum
count
select max(salary) as 最高工资,min(salary) as 最低工资, avg(salary) as 平均工资,sum(salary) as 汇总工资,count(*) as 员工数 from employees;
avg小数点会较多。可以用cast(avg(salary) as decimal(10,2)) as 平均工资,保留小数点后2位。、
select count(*),count(deptno),count(managerno) from departments;
注意:NULL值不参与统计,所以推荐用count(*)而非具体的字段
分组函数可以增加条件。where
分组函数也可以增加计算。select sum(salary),sum(salary*1.1) from employees;

















 78
78

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









