




 本文深入解析了LongAdder和AtomicLong两种线程安全的计数器类的使用场景与内部实现机制。LongAdder更适用于高并发环境下频繁进行加减操作,而AtomicLong适合于频繁查询的场景。通过源码分析,详细解释了LongAdder如何通过cells数组和base字段高效处理并发写操作。
本文深入解析了LongAdder和AtomicLong两种线程安全的计数器类的使用场景与内部实现机制。LongAdder更适用于高并发环境下频繁进行加减操作,而AtomicLong适合于频繁查询的场景。通过源码分析,详细解释了LongAdder如何通过cells数组和base字段高效处理并发写操作。
概述
介绍
| AtomicLong | LongAdder |
|---|---|
| 使用do-while循环进行CAS操作直到数据操作成功 | 将变更的大小存储在base中,如果存在竞争,每个线程的变更都存储在所属线程的cell中。 |
CAS
样例代码
public final native boolean compareAndSetLong(Object o, long offset,
long expected,
long x);
说明
| 参数 | 作用 |
|---|---|
| Object o | 当前对象的引用地址(可以看成起始地址) |
| long offset | 当前对象变更字段相对于对象起始地址的偏移量 |
| long expected | 期望的值 |
| long x | 如果期望的值和该字段在内存中的值相同,那么就会将x进行更新 |
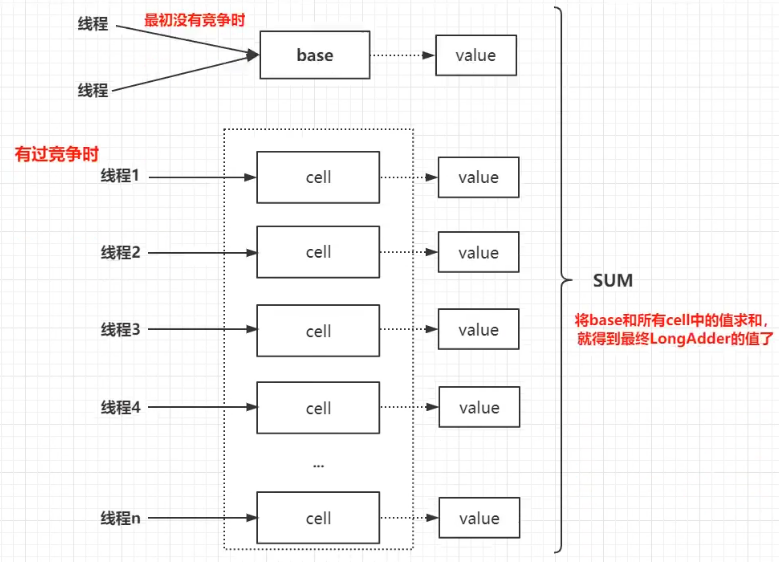
LongAdder与AtomicLong的对比
LongAdder相比于AtomicLong更适合高并发情况下,频繁进行加减变更而较少查询的操作。
AtomicLong相比于LongAdder更适合高并发情况下,频繁进行查询而较少进行加减变更的操作。
AtomicLong的精度比LongAdder的精度更高。
源码分析
add(long x)方法
/**
* Adds the given value.
*
* @param x the value to add
*/
public void add(long x) {
Cell[] cs; long b, v; int m; Cell c;
if ((cs = cells) != null || !casBase(b = base, b + x)) {
boolean uncontended = true;
if (cs == null || (m = cs.length - 1) < 0 ||
(c = cs[getProbe() & m]) == null ||
!(uncontended = c.cas(v = c.value, v + x)))
longAccumulate(x, null, uncontended);
}
}
执行到longAccumulate(x, null, uncontended)的几种情况
-
第一个if
- 情况1.1
(cs = cells) != null:cells不为null(已经存在竞争) - 情况1.2
!casBase(b = base, b + x):cells为null,但是对base进行赋值的时候失败说明存在竞争。
- 情况1.1
-
第二个if
-
当情况为1.1的时候
(c = cs[getProbe() & m]) == null ||!(uncontended = c.cas(v = c.value, v + x)):cells不为nullc = cs[getProbe() & m]) == null:如果线程对应的cells的槽位是null,说明之前未设置过值,uncontended为true。!(uncontended = c.cas(v = c.value, v + x):如果线程对应的cells的槽位不是null,说明之前已经设置过值,然后使用CAS进行设置新的值。如果设置成功则不会向下执行,如果设置失败说明存在竞争uncontended为false。 -
当情况为1.2的时候
cs == null || (m = cs.length - 1) < 0:cells为null直接执行
longAccumulate(x, null, uncontended),uncontended为true。
-
longAccumulate方法
//|--进入到该函数的几种情况
// |--1. CASE1: cells==null,并且在设置base的时候存在多个线程的竞争。需要对cells进行初始化。
// |--2. cells已经进行初始化
// |--2.1 CASE2:线程对应的cells的槽位为null。对该槽位进行赋值 new Cell(x)。
// |--2.2 CASE3:在对线程所对应的槽位进行赋值的时候,存在多个线程的竞争。可能会发生扩容和重试。
final void longAccumulate(long x, LongBinaryOperator fn,
boolean wasUncontended) {
/**
*变量说明:
*h:线程的hash值
*wasUncontended cell槽位是否存在竞争:false 存在竞争,true 不存在竞争
*collide 是否需要扩容或初始化:false 不需扩容,true 需要扩容
*cellsBusy 同步标志(Lock锁就使用到了同步标志state):0 可以获取,1 不可获取
**/
int h;
//在未使用ThreadLocalRandom.current()计算线程的hash之前,默认都是0。
//0&(length-1)=0,所以最开始存在的cell竞争是0槽位。此时需要调用ThreadLocalRandom.current()去计算线程的hash。
//该位置的状态对于此线程未知,假设不存在竞争wasUncontended = true。如果已经进行过hash初始化,则不会进入if。
if ((h = getProbe()) == 0) {
ThreadLocalRandom.current(); // force initialization
h = getProbe();
wasUncontended = true;
}
boolean collide = false; // True if last slot nonempty
done: for (;;) {
Cell[] cs; Cell c; int n; long v;
//<1> 对应CASE2、3的情况
if ((cs = cells) != null && (n = cs.length) > 0) {//<1>
//<1> 1). 对应CASE2的情况
if ((c = cs[(n - 1) & h]) == null) {
//1.1). 这里有些类似于实现单例模式的 双重检查,创建cell,并将其设置到线程所属的槽位(null)中。在设置之前会获取同步标志,设置成功之后释放同步标志。
// 因为并发,如果在这个过程中其他线程已经对该null的槽位进行设置(哈希碰撞),则会转换成CASE3,注意:wasUncontended仍然是true。
if (cellsBusy == 0) { // Try to attach new Cell
Cell r = new Cell(x); // Optimistically create
if (cellsBusy == 0 && casCellsBusy()) {
try { // Recheck under lock
Cell[] rs; int m, j;
if ((rs = cells) != null &&
(m = rs.length) > 0 &&
rs[j = (m - 1) & h] == null) {
rs[j] = r;
break done;
}
} finally {
cellsBusy = 0;
}
continue; // Slot is now non-empty
}
}
//如果未获取成功,说明有线程可能在进行扩容和初始化,所以将collide赋值false。
collide = false;
}
//<1> 1.2). CASE3的处理使用 h = advanceProbe(h)进行rehash,同自旋之前的原因一样,将wasUncontended设置为true。
else if (!wasUncontended) // CAS already known to fail
wasUncontended = true; // Continue after rehash
//<1> 1.3). CASE2的null槽位被其他线程设置,或是rehash过。会尝试对cell进行一次CAS赋值,成功则结束方法。
else if (c.cas(v = c.value,
(fn == null) ? v + x : fn.applyAsLong(v, x)))
break;
//cells数组的长度不能超过电脑的处理器数量。因为同时只能由处理器数量的线程被执行,如果长度超过会浪费空间,并设置为不可扩容。
else if (n >= NCPU || cells != cs)
collide = false; // At max size or stale
else if (!collide)
collide = true;
//<1> 1.4). 进行扩容,容量为原来的2倍。会获取同步标志。
//扩容的条件:线程的槽位不为null,并且存在竞争 wasUncontended = true,并且在尝试对cell进行CAS失败后才会进行扩容。
else if (cellsBusy == 0 && casCellsBusy()) {
try {
if (cells == cs) // Expand table unless stale
cells = Arrays.copyOf(cs, n << 1);
} finally {
cellsBusy = 0;
}
collide = false;
continue; // Retry with expanded table
}
h = advanceProbe(h);//rehash
}
//<2> 对 CASE1 的处理,获取同步标志并进行cells的初始化。初始容量为2.
else if (cellsBusy == 0 && cells == cs && casCellsBusy()) {
try { // Initialize table
if (cells == cs) {
Cell[] rs = new Cell[2];
rs[h & 1] = new Cell(x);
cells = rs;
break done;
}
} finally {
cellsBusy = 0;
}
}
// Fall back on using base
//<3> 对应 CASE1 的一种处理,若cells为null,并且有线程在进行扩容或初始化,则会尝试使用CAS将新值付给base。
else if (casBase(v = base,
(fn == null) ? v + x : fn.applyAsLong(v, x)))
break done;
}
}

















 1220
1220

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









