






Deep Learning for Anomaly Detection: A Survey
https://www.researchgate.net/publication/330357393_Deep_Learning_for_Anomaly_Detection_A_Survey
8.3 Based on the training objective 基于训练目标
In this survey we introduce two new categories of deep anomaly detection (DAD) techniques based on training objectives employed 1) Deep hybrid models (DHM). 2) One class neural networks (OC-NN).
在本研究中,我们介绍了两种新的基于采用的训练目标的深度异常检测(DAD)技术:1)深度混合模型(DHM)。2)一类神经网络(OC-NN)。
8.3.1 Deep Hybrid Models (DHM)
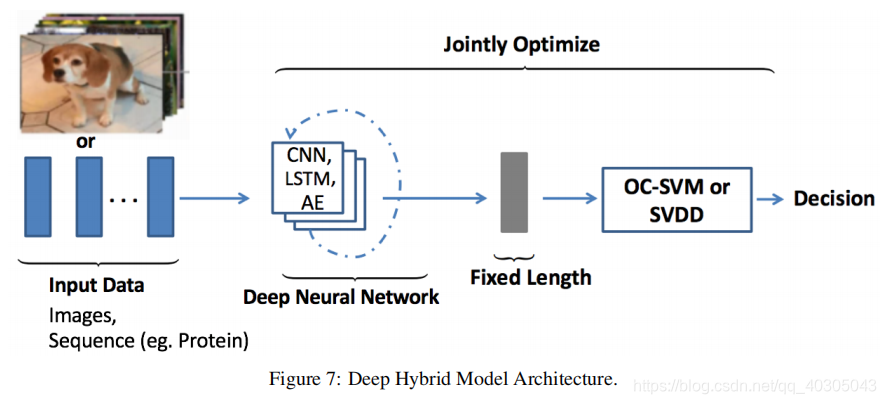
Deep hybrid models for anomaly detection use deep neural networks mainly autoencoders as feature extractors, the features learnt within the hidden representations of autoencoders are input to traditional anomaly detection algorithms such as one-class SVM (OC-SVM) to detect outliers [36]. Figure 7 illustrates the deep hybrid model architecture usedfor anomaly detection. Following the success of transfer learning to obtain rich representative features from models pre-trained on large datasets, hybrid models have also employed these pre-trained transfer learning models as feature extractors with great success [37]. A variant of hybrid model was proposed by Ergen et.al [38] which considers joint training of feature extractor along-with OC-SVM (or SVDD) objective to maximize the detection performance. A notable shortcoming of these hybrid approaches is the lack of trainable objective customised for anomaly detection,hence these models fail to extract rich differential features to detect outliers. In order to overcome this limitation customised objective for anomaly detection such Deep one-class classification [39]and One class neural networks [18]are introduced.
用于异常检测的深度混合模型使用深层神经网络,主要是将自动编码器用作特征提取器,将在自动编码器的隐藏表示中学习到的特征输入到传统的异常检测算法中,例如一类SVM(OC-SVM)以检测异常值[36]。图7说明了用于异常检测的深度混合模型架构。继迁移学习成功地从大数据集中预先训练的模型中获得丰富的代表性特征之后,混合模型也使用这些预先训练的转移学习模型作为特征提取器,取得了巨大的成功[37]。 Ergen等人[38]提出了一种混合模型的变体,该模型考虑了特征提取器与OC-SVM(或SVDD)目标的联合训练以最大化检测性能。这些混合方法的显著缺点是缺乏可训练的,为异常检测而定制的目标,因此这些模型无法提取丰富的差异特征来检测异常值。为了克服这一限制,引入了异常检测的定制目标,例如Deep one-class classification[39]和One class neural networks[18]。
8.3.2 One-Class Neural Networks (OC-NN)
One class neural network (OC-NN) Chalapathy et al. [2018a] methods are inspired by kernel-based one-class classifification which combines the ability of deep networks to extract a progressively rich representation of data with the one-class objective of creating a tight envelope around normal data. The OC-NN approach breaks new ground for the following crucial reason: data representation in the hidden layer is driven by the OC-NN objective and is thus customized for anomaly detection.This is a departure from other approaches which use a hybrid approach of learning deep features using an autoencoder and then feeding the features into a separate anomaly detection method like one-class SVM (OC-SVM). The details of training and evaluation of one class neural networks is discussed in Section 10.4. Another variant of one class neural network architecture Deep Support Vector Data Description (Deep SVDD) (Ruff et al. [2018a]) trains deep neural network to extract common factors of variation by closely mapping the normal data instances to the center of sphere, is shown to produce performance improvements on MNIST (LeCun et al. [2010]) and CIFAR-10 (Krizhevsky and Hinton [2009]) datasets.
One class neural network(OC-NN)Chalapathy等 [2018a]方法的灵感来自基于核的one-class classifification,这种方法结合了深度网络的能力,以提取逐渐丰富的数据表示,这种数据表示带有在正常数据周围创造的紧密包络的单类目标。OC-NN方法由于以下关键原因而开辟了新天地:隐藏层中的数据表示由OC-NN目标驱动,因此可以针对异常检测进行定制。这与其他方法不同,其他方法使用混合方法,即使用自动编码器学习深层特征,然后将特征馈入单独的异常检测方法中,例如one-class SVM(OC-SVM)。第10.4节讨论了one class neural networks的训练和评估的细节。one class neural network体系结构的另一种变体深度支持向量数据描述(Deep SVDD)(Ruff等人[2018a])训练了深度神经网络,通过将正常数据实例紧密映射到球体中心来提取常见的变异因素。可以显示出在MNIST(LeCun等人[2010])和CIFAR-10(Krizhevsky and Hinton [2009])数据集上的性能提高。
8.4 Type of Anomaly 异常类型
Anomalies can be broadly classified into three types: point anomalies, contextual anomalies and collective anomalies. Deep anomaly detection (DAD) methods have been shown to detect all three types of anomalies with great success.
异常可以大致分为三类:点异常,上下文异常和集合异常。深度异常检测(DAD)方法已被证明能够成功检测这三种类型的异常。
8.4.1 Point Anomalies
The majority of work in literature focuses on point anomalies. Point anomalies often represent an irregularity or deviation that happens randomly and may have no particular interpretation. For instance, in Figure 10 a credit card transaction with high expenditure recorded at Monaco restaurant seems a point anomaly since it significantly deviates from the rest of the transactions. Several real world applications, considering point anomaly detection, are reviewed in Section 9.
文献中的大部分工作都集中在点异常上。点异常通常表示随机发生的不规则或偏差,可能没有特殊解释。例如,在图10中,在摩纳哥餐厅记录的高额信用卡交易似乎是一个点异常,因为它与其他交易有很大的偏差。考虑点异常检测的几个实际应用在第9节中进行了回顾。
8.4.2 Contextual Anomaly Detection
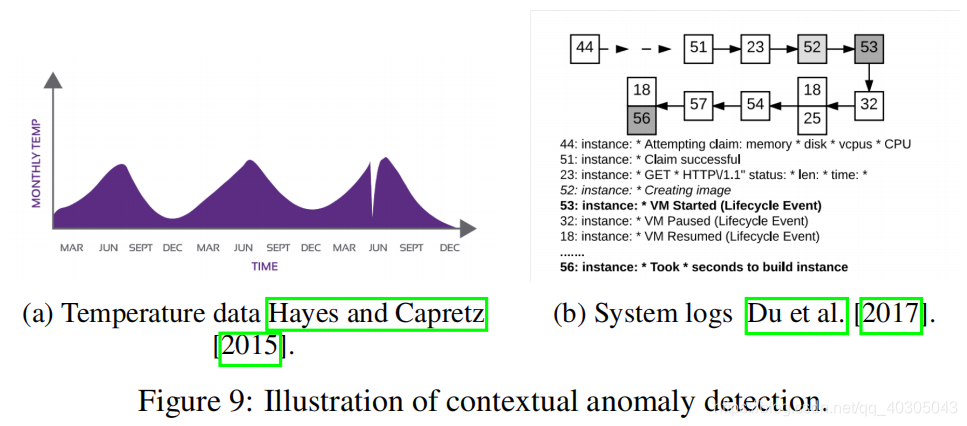
A contextual anomaly is also known as the conditional anomaly is a data instance that could be considered as anomalous in some specific context (Song et al. [2007]). Contextual anomaly is identified by considering both contextual and behavioural features. The contextual features, normally used are time and space. While the behavioral features may be a pattern of spending money, the occurrence of system log events or any feature used to describe the normal behavior. Figure 9a illustrates the example of a contextual anomaly considering temperature data indicated by a drastic drop just before June; this value is not indicative of a normal value found during this time. Figure 9b illustrates using deep Long Short-Term Memory (LSTM) (Hochreiter and Schmidhuber [1997]) based model to identify anomalous system log events (Du et al. [2017]) in a given context (e.g event 53 is detected as being out of context).
上下文异常也称为条件异常,它是在某些特定上下文中可以视为异常的数据实例(Song等人[2007])。通过考虑上下文和行为特征来识别上下文异常。通常使用的上下文特征是时间和空间。而行为特征可能是一种花钱的模式、系统日志事件的发生或用于描述正常行为的任何特征。图9a显示了一个上下文异常的例子,鉴于气温数据显示在6月之前急剧下降;该值并不表示在此期间找到的正常值。图9b说明了在给定上下文中使用深度长短期记忆(LSTM)(Hochreiter and Schmidhuber [1997])模型来识别异常系统日志事件(Du et al。[2017])(例如,事件53被检测为脱离上下文)。
8.4.3 Collective or Group Anomaly Detection
Anomalous collections of individual data points are known as collective or group anomalies, wherein each of the individual points in isolation appears as normal data instances while observed in a group exhibit unusual characteristics. For example, consider an illustration of a fraudulent credit card transaction, in the log data shown in Figure 10, if a single transaction of ”MISC” would have occurred, it might probably not seem as anomalous. The following group of transactions of valued at $75 certainly seems to be a candidate for collective or group anomaly. Group anomaly detection (GAD) with an emphasis on irregular group distributions (e.g., irregular mixtures of image pixels are detected using a variant of autoencoder model (Chalapathy et al. [2018b], Bontemps et al. [2016], Araya et al. [2016], Zhuang et al. [2017]).
单个数据点的异常集合称为集合异常或组异常,其中孤立的每个点作为正常数据实例出现,而在组中观察到的每个点则表现出不寻常的特征。例如,在图10所示的日志数据中,考虑一个欺诈性信用卡交易的例子,如果发生了单个“MISC”交易,它可能看起来并不异常。下面这组价值75美元的交易显然是集体或群体异常的候选者。群体异常检测(GAD)侧重于不规则的群体分布(例如,使用一种自编码模型的变体来检测图像像素的不规则混合(Chalapathy等[2018b], Bontemps等[2016],Araya等[2016],Zhuang等[2017])。

8.5 Output of DAD Techniques
A critical aspect for anomaly detection methods is the way in which the anomalies are detected. Generally, the outputs produced by anomaly detection methods are either anomaly score or binary labels.
异常检测方法的关键方面是检测异常的方式。通常,由异常检测方法产生的输出是异常评分或二进制标签。
8.5.1 Anomaly Score:
Anomaly score describes the level of outlierness for each data point. The data instances may be ranked according to anomalous score, and a domain-specific threshold (commonly known as decision score) will be selected by subject matter expert to identify the anomalies. In general, decision scores reveal more information than binary labels. For instance, in Deep SVDD approach the decision score is the measure of the distance of data point from the center of the sphere, the data points which are farther away from the center are considered anomalous (Ruff et al. [2018b]).
异常评分描述了每个数据点的异常程度。数据实例可以根据异常得分进行排序,主题专家将选择特定领域的阈值(通常称为决策得分)来识别异常。一般来说,决策得分比二元标签揭示更多的信息。例如,在深度SVDD方法中,决策得分是数据点到球体中心的距离的度量,那些离中心较远的数据点被认为是异常的(Ruff et al. [2018b])。
8.5.2 Labels:
Instead of assigning scores, some techniques may assign a category label as normal or anomalous to each data instance. Unsupervised anomaly detection techniques using autoencoders measure the magnitude of the residual vector (i,e reconstruction error) for obtaining anomaly scores, later on, the reconstruction errors are either ranked or thresholded by domain experts to label data instances.
有些技术可能会将类别标签指定为正常或异常,而不是为每个数据实例指定分数。使用自动编码器的无监督异常检测技术测量残差向量(即重构误差)的大小,以获得异常值,然后由领域专家对重构误差进行排序或阈值化,以标记数据实例。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









