








论文简述:
第一作者:Yair Kittenplon
发表年份:2021
发表期刊:IEEE Conference on Computer Vision and Pattern Recognition(CVPR)
探索动机:1、传统的基于学习的端到端3D流学习方法往往泛化性较差。2、场景流中场景之间会出现较大偏差的问题3、缺乏三维场景流的标注数据
工作目标:1、使得网络有更好的泛化性,更高效的内存,对于大位移有更好的处理效果。2、实现场景流的自监督学习
核心思想:
1、提出了第一个非刚性场景流的递归架构。 |
2、通过合并低分辨率相关性和展开的迭代求精过程,提供了一个小内存的all-to-all相关方法。 |
3、提出的网络在FlyingThings3D和KITTI测试集上取得了比现有自监督方法更大的提升。 |
实现方法:1、首先,使用一个全局相关单元通过all-to-all的方式来指导对齐。然后展开一个局部更新单元来学习精化点云的运动。其中局部更新单元实现了迭代最近点算法的一次迭代。2、利用Chamfer损失和正则化损失实现了点云的自监督学习
实验结论:在这项工作中,我们提出并研究了一种新的场景流估计方法,该方法通过使用一个循环架构来展开迭代方案,该方案学习通向解决方案的最佳步骤,称为FlowStep3D。我们展示了通过强正则化和重新编码扭曲场景在几个步骤中接近解决方案的好处,这与以前所有基于学习的解决方案相反。在合成和真实LiDAR扫描数据上进行的实验显示出很好的泛化能力,特别是对于自监督训练,大大改进了以前的方法。
论文翻译:
FlowStep3D: Model Unrolling for Self-Supervised Scene Flow Estimation
摘要:
估计场景中点的三维运动,称为场景流,是计算机视觉中的一个核心问题。传统的基于学习的端到端3D流学习方法往往泛化性较差。在这里,我们提出了一个循环架构,它学习一个展开迭代对齐过程的单个步骤,以改进场景流预测。受经典算法的启发,我们利用强正则化证明了迭代收敛到解。所提出的方法可以处理大规模的时间变形,并且比目前具有竞争性的全相关方法具有更小的结构。仅在FlyingThings3D合成数据上进行训练,我们的网络成功地泛化到真实场景,在KITTI自监督基准测试集上大大优于所有现有方法。
1、引言
理解运动是许多应用程序的基础在各种领域,如人机交互、机器人、自动驾驶。时间窗口内得到的信息不仅是图像的集合或结果的表征,也是对过程的描述。 它将我们从将颜色作为主要的对应特征中解放出来,并允许检查结构本身来理解运动。
几十年前,计算机视觉处理运动估计的任务,寻找两个图像之间的流(3、7、14、22、41]。一个重要的飞跃是3D几何的出现,定义为场景流。刚性[ 2、6]的公理化概念给场景流估计提供了快速和准确的结果,但一旦允许分段移动[ 9、10、39]或非刚体[ 1,15,23],场景流估计问题就变得不适定且很难解决。
人工智能[ 19 ]的兴起使得利用一个网络结构来解决三维流估计问题成为可能。事实上,在过去的几年中,不同的基于学习的方法[ 12、21、31、37、43]得到了改善,优于那些依赖于优化的方法。更重要的是,这些学习到的模型是快速和鲁棒的。
场景流估计是自动驾驶行业中不可或缺的组成部分,其中LiDAR数据被用于环境感知中。然而,LiDAR传感器具有稀疏性,直接影响了需要物体时空邻域知识的深度学习流算法。 换句话说,一旦结构没有完全重叠,过程就失败了。为了解决这个限制,我们最近已经看到了图像[ 36 ]和几何[ 31 ]的all-all机制。然而,这些方法消耗了大量的内存,并且容易产生异常值,因为现在附近的点可以被对齐到与不一致的时间位置。
在这个工作中,我们专注于场景流中场景之间会出现较大偏差的问题。一个小的点集被用来指导对齐,通过all-to-all的方法。我们训练我们的网络一步一步的预测并迭代收敛到最终流解,如图1所示。虽然在训练过程中进行了K次迭代,但我们的网络可以用更多的迭代次数进行推理,以处理更显著和复杂的变形。
仅在合成数据上进行训练,我们的方法在自监督KITTI基准测试集上的最新结果有相当大的提升。我们的架构在强监督框架中进一步测试,在受益于内存效率的同时,取得了比现有技术略好的结果。
本文的主要贡献如下:
•我们提出了第一个非刚性场景流的递归架构。
•我们通过合并低分辨率相关性和展开的迭代求精过程,提供了一个小内存的all-to-all相关方法。
•我们提出的网络在FlyingThings3D和KITTI测试集上取得了比现有自监督方法更大的提升。
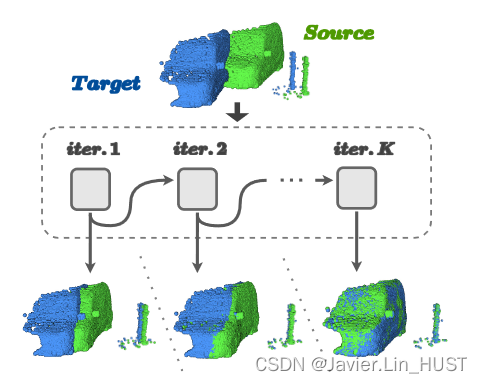
图1。模型展开。顶层:从KITTI [ 27 ]场景流数据集中采样的源(绿色)和目标(蓝色)输入点云。中间:说明我们的FlowStep3D架构在K次迭代中展开。Bottom:在每次迭代中,源对预测流的扭曲,在推理时刻指向静态目标。
2、相关工作
点云上的场景流估计。场景流估计最早在文献[ 38 ]中被提出,他建议使用线性算法从二维光流计算三维场景流。后来的方法使用立体序列[ 16 ]、RGB - D [ 13 ]和LiDAR [ 6 ]。随着点云深度学习新方法[ 32、33、35、42]的兴起以及自动驾驶领域范围数据的日益普及,最近的方法建议直接从原始数据空间位置学习三维场景流。
Liu等[ 21 ]在点网络[ 32 ]的基础上首次引入了一种聚合不同点云特征的相关层。然而,相关层是在特定的尺度下应用的,只能得到点云之间特定级别特征的相关性,同时固定的邻域半径只能允许点云之间的微小形变。Gu等人[ 12 ]通过引入多分辨率相关层来解决这些限制,并提出使用双边卷积层[ 17、18、35]。受经典金字塔方法的启发,Wu等[ 43 ]进一步改进了多分辨率流,采用由粗到粗到精的方式应用,并显示出优越的结果。然而,多分辨率方法需要许多可学习的参数,并且仅限于小于相关邻域的变化。在[ 37 ]中,作者建议将运动分为刚性自运动和非刚性自运动的精细化成分,基于与[ 12 ]相同的架构。文献[ 31 ]提出了一种基于全相关的方法,使用最优的传输工具来估计场景流,取得了很好的效果。然而,针对大规模点云的全相关矩阵是低效的。
我们采用了全相关的概念,但与[ 31 ]不同的是,我们建议在更深、更低分辨率的空间中有效地使用它。
自监督学习。学习以自监督的方式估计场景流是一个活跃的研究领域。Mittal等[ 29 ]研究表明,循环一致性和最近邻损失可以用于场景流学习的自我监督,使用FlowNet3D [ 21 ]的主干,在合成数据上以完全监督的方式进行预训练。Tishchenko等[ 37 ]将相同的自监督损失与全监督损失合并为" Hybrid loss ",而[ 43 ]则提出了一种全自监督过程,结合了Chamfer、最近邻和拉普拉斯损失。
我们遵循[ 43 ],选择Chamfer损失作为我们训练的数据项损失。尽管如此,受经典非刚性对齐算法的启发,我们认为这个数据项不足以用于一次性的端到端解决方案。因此,我们提出了一种场景流估计的迭代方法,并强调了强正则化损失项的必要性。
算法展开。虽然绝大多数深度学习方法提出了一种纯粹的数据驱动的、一次性的解决方案,但将迭代算法与神经网络架构相结合以同时利用学习和先验知识的趋势正在上升。最近的工作通过对能量最小化问题或模型的显式迭代求解,为信号和图像处理任务[ 8、20、25、28、30、44、45]展示了有希望的结果。一种名为RAFT [ 36 ]的当代方法提出了2D光流估计的模型展开,在4D全相关体上执行查找。
我们提出了展开单步流估计模型。受[ 36 ]的启发,我们还采用了使用门控循环单元进行迭代更新的思想。与[ 36 ]不同的是,我们方法是在每一次迭代中计算扭曲场景的新特征。这是必要的,因为所有的点云卷积方法都不是旋转不变的,所以在向目标旋转时,源特征会发生变化。我们认为这一过程是迭代学习微分器的关键部分。
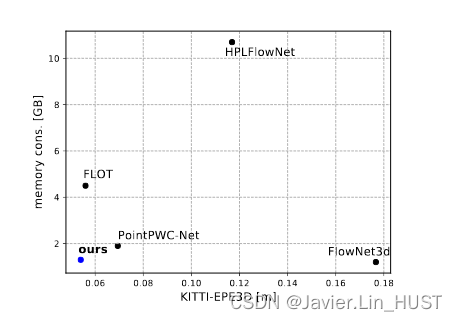
图2。内存消耗和精度权衡。KITTI测试中领先的强监督方法的平均端点误差( 第六节) vs .推理时的内存消耗,每个场景8192点
3、问题定义
场景流是场景中点的三维运动场。对于给定的两组点S = { pi∈R3 } n1i = 1和T = { qj∈R3 } n2j = 1,在连续两个时间帧从动态场景中采样,我们用fi∈R3表示点pi∈S从第一帧到第二帧新位置的平移运动矢量。我们的目标是估计描述最佳非刚性变换的场景流F = { fi } n1i = 1,它将S对齐到T。由于三维数据的稀疏性和可能存在的遮挡,点p′i可能不会出现在T中。因此,我们不学习S和T之间的对应关系,而是学习每个点pi∈S的流表示。
一般而言,每个点pi,qj可能具有颜色或几何特征等额外信息。源中的点数可能与目标中的点数不同,即n1和n2不一定相等。
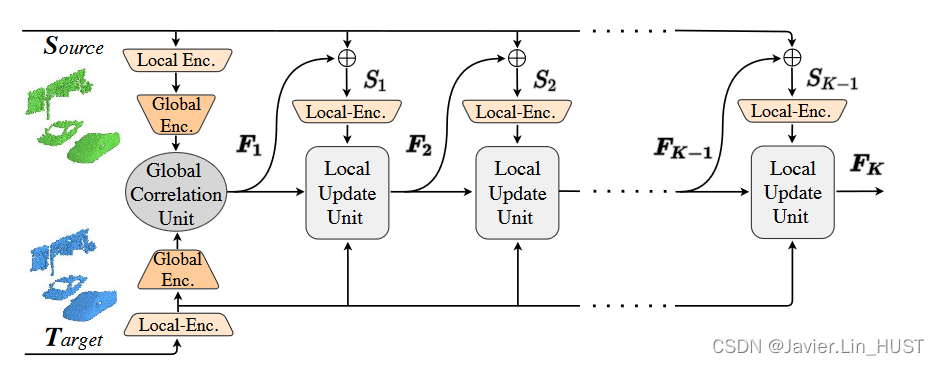
图3。Flowstep3D高层概览。在第1次迭代时,全局相关单元(图4 )根据深度编码得到的源和目标全局特征生成初始流F1。在每次迭代中,通过加入前一次迭代Fk - 1的预测流,使源点云向目标方向弯曲。然后对其进行局部编码并送入局部更新单元(图5 ),以精细化场景流的估计。局部更新单元和编码器的权重在所有外观上共享。
4、结构
我们提出一个迭代系统(图3 ),预测一个场景流序列{ F 1,..,F K },其中F K = F*是我们最终的场景流估计。首先,我们使用一个全局相关单元( Sec.4.2 )通过all-to-all的方式来指导对齐。接下来,我们展开一个局部更新单元( Sec.4.3 )来学习精化点云的运动。我们的局部更新单元实现了迭代最近点( Iterative Closest Point,ICP )算法[ 4、2]的一次概念迭代,将两个阶段的( a .寻找对应关系, b .根据对应关系估计最佳平滑变换)替换为学习组件。
迭代次数K是一个超参数,在推理过程中可以比在训练过程中更大,以处理更复杂和更大的变形,如6.3节中讨论的。
4.1 局部和全局特征编码
一方面,点的局部特征编码了其相对较小邻域的几何特征,对局部对齐细化很有用。另一方面,全局特征利用更大的感受野和更深的编码,捕获关于场景中点的相对位置的高级信息。我们方法的一个关键部分是点云的局部特征和全局特征的区分。
我们使用FlowNet3D [ 21 ]提出的set conv层作为我们的卷积机制和最远点采样方法进行下采样。我们的局部编码器g θ:Rn × 3 7→Rn′× dlocal仅由两个set conv层组成,捕获一个相对较小的感受野,使其输出编码一个输入的dlocal维度的浅层特征,分辨率为n′。首先对源点云和目标点云进行局部编码,产生g θ ( S ),gθ ( T ),然后在每一次迭代k时对扭曲的源点云Sk再次进行局部编码,产生g θ ( Sk )。
为了提取全局特征,将局部特征描述子g θ ( S ),gθ ( T )注入到一个额外的编码器h θ中:Rn′× dlocal 7→Rn′′× dglobal,产生h θ ( gθ ( S ) )和h θ ( gθ ( T ) ),对S和T进行维数为dglobal的更深层次的表示,分辨率n′′< < n′,记为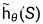 ,
,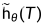 ,以方便记号。g θ和h θ编码器在所有外观上都有共享权重。
,以方便记号。g θ和h θ编码器在所有外观上都有共享权重。
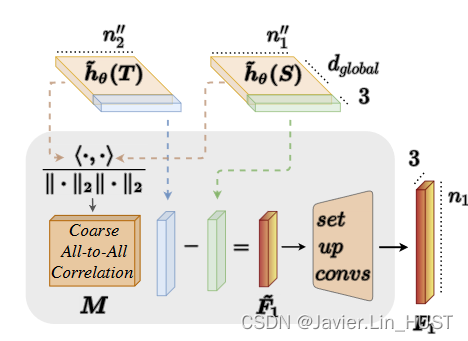
图4。全局相关单元。利用源和目标的全局特征,的内积生成粗略的全对全相关矩阵M,然后利用矩阵相乘和设置的一组set_up_conv层预测全局流F1,如4.2节所示。
4.2 全局相关单元
我们基于一个深度,粗糙的all-to-all机制,使用全局相关单元去估计一个初始的场景流F1,如图4.
粗糙的全相关矩阵。作为全局相关单元的第一步,我们使用,计算一个粗略的全相关矩阵M∈Rn″1 × n″2。受FLOT [ 31 ]的启发,我们计算特征向量之间的余弦相似度:
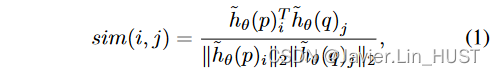
然后利用指数函数由其推导出软相关矩阵:
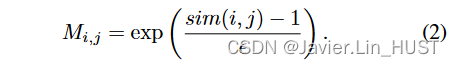
因此,每一个条目Mi,j都描述了θ ( p ) i和θ ( q ) j之间的相关性,并且softmax温度系数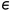 是一个超参数,设置为0.03。
是一个超参数,设置为0.03。
与[ 31 ]不同,我们在更低的维度上计算全相关矩阵M,n″1 × n″2 < < n1 × n2,从而显著减少所需的内存。
全局场景流估计。为了使用计算得到的相关矩阵在欧氏空间中进行全局流嵌入,我们应用了一个简单的矩阵乘法:
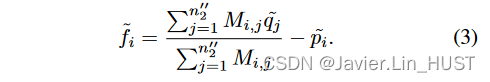
因此,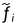 是
是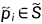 到所有点{ ' qj } n′′2 j = 1∈' T之间的平均距离,由它们的相关程度加权,其中' S∈Rn′′1 × 3和' T∈Rn′′2 × 3是编码器降采样后S和T坐标的粗略版本。第1次迭代流F1∈Rn1 × 3,由一组set_up_conv层回归出' F1 = { ' fi } n′′1i = 1 [ 33 ]。
到所有点{ ' qj } n′′2 j = 1∈' T之间的平均距离,由它们的相关程度加权,其中' S∈Rn′′1 × 3和' T∈Rn′′2 × 3是编码器降采样后S和T坐标的粗略版本。第1次迭代流F1∈Rn1 × 3,由一组set_up_conv层回归出' F1 = { ' fi } n′′1i = 1 [ 33 ]。
4.3 局部更新单元
我们使用迭代更新过程,从全局流估计F1开始,基于局部信息估计场景流流序列{ F2,..,FK }的其余部分。
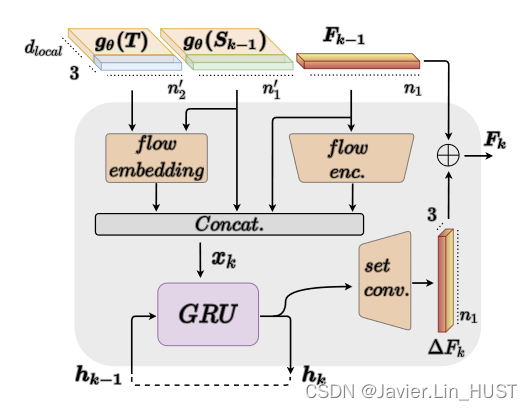
图5。局部更新单元。将前一次迭代预测流Fk - 1及其编码特征与当前状态源的局部特征描述子g θ ( Sk-1 )和目标的局部特征描述子g θ ( T )及其相关性(flow embedding( · , ·) )串联成xk。门控循环单元( Gated Recurrent Unit,GRU )后面跟着set up conv层产生流细化∆Fk,如4.3节所述。
Warp和Encode。在每次迭代k∈{ 2,. . .,K }时,我们使用上一次迭代的估计流来扭曲源点,即Sk - 1 = S + Fk - 1。接下来,利用局部编码器g θ,我们为扭曲源g θ ( Sk-1 )提取了一个新的局部特征描述子,我们将其用于局部相关性的计算(图3上)。
局部相关性。为了得到扭曲源和目标的局部特征之间的相关性,我们采用了FlowNet3D [ 21 ]提出的flow embedding相关层。提出的相关层聚合了局部邻域内点的特征相似性和空间关系,因此适用于局部细化。具体来说,在每次迭代k时,我们计算flow embedding:( gθ ( Sk-1 ),gθ ( T ) )∈Rn′1 × dcorr,它为warp后的源Sk - 1中的每一点编码流向目标T的流嵌入。
门控循环单元( GRU )。受RAFT [ 36 ]的启发,我们使用基于GRU单元设计的门控激活单元[ 5 ]作为更新机制。给定前一次迭代隐状态hk - 1,加上当前迭代信息xk,产生更新后的隐状态hk:

其中⊙是Hadamard积,[ · , ·]是级联,σ ( · )是sigmoid激活函数.
定义xk∈Rn′1 × ( dlocal + dcorr + 3 + dmotion )为扭曲源的局部特征、局部流嵌入、前一次迭代流和前一次迭代流特征的级联。前一次迭代流的特征是将其输入到flow_enc:Rn1 × 3 7→Rn′1 × dmotion得到的,其中flow_enc由两层set conv组成,如图5所示。
对于第一次迭代隐状态的初始化,我们通过两个set conv层传递源点云的局部特征g θ ( S )。
场景流预测。给定GRU单元产生的新隐状态hk,我们使用一个由两个set conv层组成的流回归器来估计流求精Δ Fk。更新后的流量计算为Fk = Fk-1 +∆Fk。
通过同一个CNN组件回归完全不同尺度的流精化是具有挑战性的。因此,为了鼓励我们的系统在第一次迭代中学习粗略的位移,我们将每个预测场景流的大小乘以一个因子1/ ( C · ( k-1 ) + 1 ),其中C是一个超参数。
5、训练损失函数
为了训练我们的迭代系统,我们展开K次迭代,并为每次迭代预测F k应用一个损失函数:
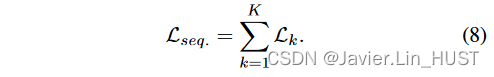
序列中的每个迭代损失Lk可以选择为自监督损失( Sec.5.1 )或强监督损失( Sec.5.2 )。
5.1 自监督损失
由于缺乏三维场景流的标注数据,我们设计了解决方案,以自监督的方式进行训练,即不需要场景流的GT。
Chamfer损失。我们沿用之前的工作[ 11、40、43],选择Chamfer距离,它强制源点云根据相互最近的点向目标移动,作为我们的自监督数据损失:
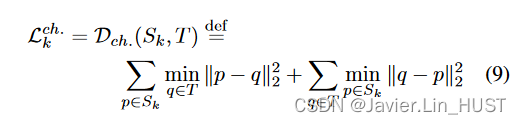
其中Sk:= S + Fk是根据迭代k时刻的预测流量得到的扭曲后的源点云。
正则化损失。由于Chamfer距离存在多个局部极小值,为了达到足够的收敛性,对其进行正则化是至关重要的。我们的系统需要强正则化的另一个原因是,在重新编码之前,我们根据预测的流来扭曲源。因此,我们需要小心地保存物体的结构,以便对扭曲的场景进行编码会产生有意义的局部几何特征(图8 )。
受[ 1、11、34、43]的启发,我们提出了一种强拉普拉斯正则化,即在根据预测流进行warp时,强制源保持其拉普拉斯:
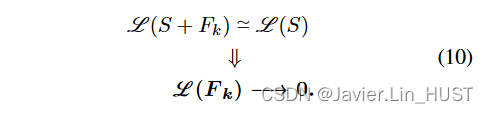
我们将点xi∈X上的Laplacian L ( X )近似为它到所有点xj∈N ( xi )的距离,其中N ( xi )是定义在序列中的xi附近的一个邻域内的点集,其大小为| N ( xi ) | .我们使用L1范数进行正则化,这样我们的正则化损失为:
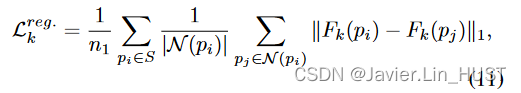
其中Fk ( pi )为预测场景流在点pi处的值,n1为源中点的个数。
为了减少大K的最近邻的计算开销,我们使用N ( pi ) = Na ( pi )∪Nb ( pi ),其中Na ( pi )是pi的Ka个最近邻,Nb ( pi )是通过在pi周围的一个半径为rb的欧氏球中随机采样Kb个点来计算的。
整个自监督损失是所有序列迭代中Chamfer损失和正则化损失的加权和:
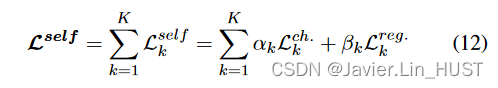
5.2 全监督损失
为了展示我们的架构效率,我们进一步以强监督的方式训练我们的系统,使用L1损失
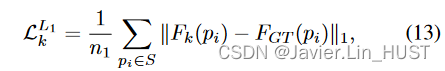
式中:FGT ( pi )为场景流在点pi处的GT值。
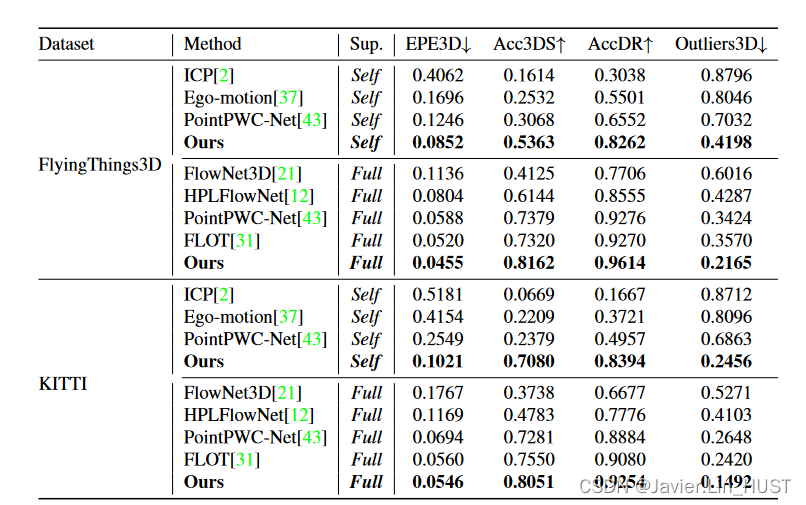
表1。在FlyingThings3D和KITTI数据集上的评估结果。所有方法仅在FlyingThings3D上训练。Self / Full表示自监督/强监督,其中在KITTI上Self / Full表示在KITTI上评估的各自模型在FlyingThings3D上的训练类型。我们的方法在强监督和自监督训练中的所有指标上都优于所有基线。我们的自监督版本是FlyingThings3D上唯一一个EPE3D在10m以下的自监督方法,它在KITTI上的泛化能力比现有基线提高了50 %以上。
与之前的方法不同,我们在强监督的训练中增加了一个拉普拉斯正则化损失,以鼓励我们的系统在迭代中保持对象的结构并接近目标。正则化损失与自监督情形下相同,如公式( 11 )。
整个强监督损失是L1和正则化损失在所有序列迭代中的加权和:
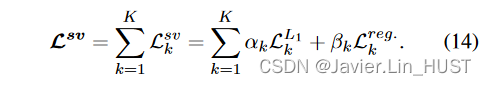
6、实验
按照[ 12、21、31、37、43]中建议的实验设置,我们首先使用自监督和强监督方法在合成数据集FlyingThings3D [ 24 ] ( Sec.6 . 1 )上训练和评估我们的模型。然后,我们在没有任何微调的真实世界KITTI场景流数据集[ 26、27] ( Sec.6.2 )上测试了模型的性能。最后,在6.3节,我们对推理迭代次数和正则化损失的重要性进行了消融研究。
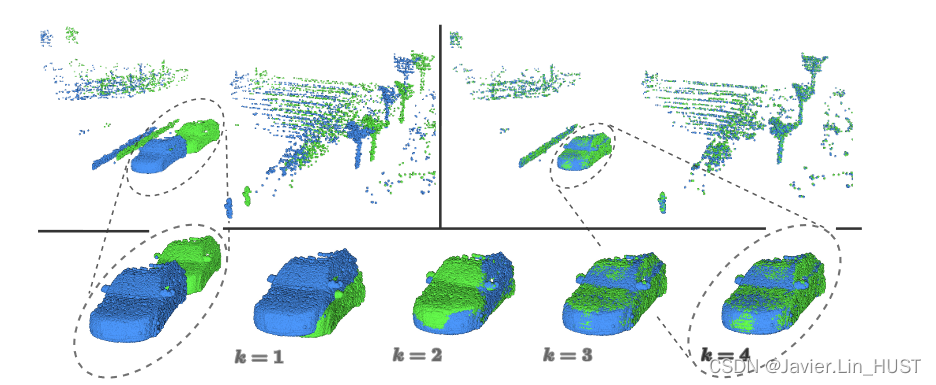
图6。推理迭代。自监督模型输出实例来自KITTI测试集。左上:输入源(绿色)和目标(蓝色)扫描。右上角:扭曲源与目标的叠加。底层:在流估计的四次迭代中,对扭曲源朝向目标的更近距离观测。
评估指标。我们使用与[ 21 ]相同的场景流评价指标,并被[ 12、31、43]所采用:

6.1 在FlyingThings3D上评估
由于难以获得稠密的场景流数据,我们沿用之前的方法[12、21、31、43],仅在合成的FlyingThings3D数据集上训练系统,采用与文献[ 12 ]相同的预处理方法。
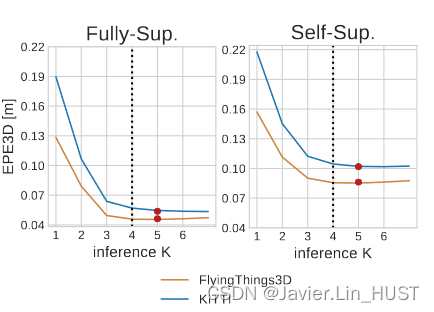
图7。对于强监督(左)和自监督(右)训练的模型,基于FlyingThings3D验证集(橙色)的最佳K (红色),用于测试KITTI (蓝色)。两个模型均以K = 4 (虚线)进行训练。
首先,我们关注一种自监督方法,该方法不需要任何带标签的数据。然后,为了证明我们的系统效率,我们还使用强监督损失进行了实验。
实现细节。FlyingThings3D数据集包含19 640对训练集点云和3 824对验证集点云。我们首先在四分之一的训练数据( 4910对)上训练系统,然后在完整的训练集上进行微调,以加速训练。我们使用FlyingThings3D验证集进行所有超参数调优。
我们使用8个GTX - 2080Ti GPU,每个点云使用n = 8192个点,批处理大小为16,在所有训练过程中unroll K = 4次迭代。对90个历元进行预训练,学习率为0.002,在[ 50、70]历元减少一半。自监督模型微调30个历元,学习率为0.002,在历元[ 5、15、25]时减少一半。对强监督模型进行40个历元的微调,学习速率为0.001,在历元[ 10、22、30]时减少一半。
为了减少异常值,我们将对应点的距离限制在一个合理的位移范围内,即在‖pi-qj‖2 > 10m的每个条目( i , j)处粗略的全对全相关矩阵进行置零。
最后,我们使用FlyingThings3D验证集来确定我们的模型在推断时的最佳迭代次数。正如在6.3节讨论的,我们对所有的测试都设定K = 5。
所有训练过程的损失权重{ αk } K k = 1,{ βk } K k = 1,我们的架构的详细方案可以在补充材料中找到。
结果。我们将我们的自监督方法与迭代最近点( ICP ) [ 2 ]、PointPWCNet [ 43 ]以及最近由Tishchenko等[ 37 ]提出的自监督方法进行比较,并将我们的强监督方法与FlowNet3D [ 21 ]、HPLFlowNet [ 12 ]、PointPWC-Net [ 43 ]以及FLOT [ 31 ]进行比较。
如表1所示,在FlyingThings3D数据集上,对于自监督和全监督框架,我们的方法在所有评价指标上都优于所有现有的方法。此外,我们的自监督方法是FlyingThings3D数据集上唯一的EPE3D在10m以下的自监督方法。
6.2 泛化到KITTI
为了检验我们的方法对真实数据的泛化能力,我们评估了一个使用FlyingThings3D训练的模型,在真实扫描的KITTI Scene Flow 2015 [ 26、27]数据集上,没有任何微调。在[ 12、43]的基础上,我们在训练集中所有142个具有可用三维数据的场景上评估我们的模型,并按高度( < 0.3m )从点云中删除地面点。
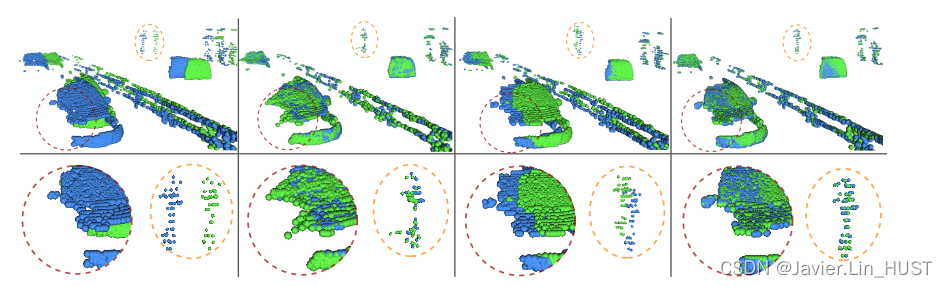
图8。正则化推理示例。用三种不同的正则化方案对我们的自监督模型进行预训练。从左到右:输入源(绿色)和目标(蓝色)扫描,欠正则化,过正则化和我们选择的正则化。有趣的工件在底部被圈出并放大。所有变异均以K = 4进行评价。
我们的自监督方法表现出了很好的泛化能力,比所有现有的自监督方法高出50 %以上。
我们的强监督模型实现了与最先进方法相当的EPE3D [ 31 ],具有最高的准确率、最低的异常值和内存效率(图2 )。
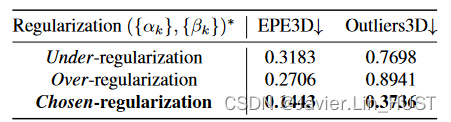
表2 .规则化。不同正则化损失权重{ αk },{ βk }预训练的自监督模型的EPE3D和离群率。均以K = 4进行评价。可以看出,过正则化和欠正则化都增加了误差.所有β k,α k的精确值在我们的补充中.
6.3 消融研究
迭代次数。虽然我们展开了4次迭代进行训练,但是我们测试了不同K值的推断(图7 )。有趣的是,在KITTI测试集上,我们的两个模型在更多的迭代中保持了轻微的改进。在FlyingThings3D验证集上,将模型优化为比训练迭代次数多1次。为了减少运行时间,可以选择将系统优化到更小的迭代次数,并且迭代2或3次也能得到很好的结果。然而,K = 4训练的模型不仅产生最好的结果,而且受益于最好的泛化能力,特别是在大变形下。图6展示了我们的自监督方法在4次推理迭代过程中的定性示例。
更新单元设计选择。使用GRU比使用简单的全连接层表现出更好的性能,将系统的泛化能力提高了40 %。关于其输入,我们发现单独使用流嵌入作为GRU输入会将验证误差提高30 %。
正则化。由于我们的方法在每次迭代时都会对扭曲的源进行重新编码,因此使用正则化损失对其进行训练至关重要。欠正则化训练可能会扭曲物体的结构,而过正则化可能会导致半刚性运动预测,从而导致不完美对齐。为了证明明智地选择正则化损失权重的重要性,我们在三种不同的正则化方案中预训练我们的自监督模型,只改变损失权重{ βk } K k = 1,{ αk } K k = 1,然后在KITTI测试集上对它们进行评估。我们给出了表2中的定量结果和图8中的定性例子。
7、总结
在这项工作中,我们提出并研究了一种新的场景流估计方法,该方法通过使用一个循环架构来展开迭代方案,该方案学习通向解决方案的最佳步骤,称为FlowStep3D。我们展示了通过强正则化和重新编码扭曲场景在几个步骤中接近解决方案的好处,这与以前所有基于学习的解决方案相反。在合成和真实LiDAR扫描数据上进行的实验显示出很好的泛化能力,特别是对于自监督训练,大大改进了以前的方法。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









