






 本文作者从自身经验出发,探讨了AI的定义,指出AI是计算机模拟人类决策行为。AI的爆火源于大数据、深度学习的突破以及新应用场景的出现,但理论层面并未有本质突破。AI的三要素包括问题确定性、检验合理性及标注数据,这些在现实场景中往往难以同时满足。此外,文章还分享了对AI工程师角色的理解和AI在公司中的合理定位。
本文作者从自身经验出发,探讨了AI的定义,指出AI是计算机模拟人类决策行为。AI的爆火源于大数据、深度学习的突破以及新应用场景的出现,但理论层面并未有本质突破。AI的三要素包括问题确定性、检验合理性及标注数据,这些在现实场景中往往难以同时满足。此外,文章还分享了对AI工程师角色的理解和AI在公司中的合理定位。
“90%的人认为正确的,往往是我反对的 -- Paul Yang’
1. 前言
我与AI还是能扯上点关系的。硕士读的NLP,自认为真的用心学了。我可能算是百度第一个“算法工程师”,也是NLP团队的第一任Leader。近些年又重度经历All in AI投入很大最终打了水漂的过程。
我从算法转到工程,又从工程转到管理。但AI相关的工作也一直没中断。本文就谈谈我对AI的理解。但脱产已久,水平有限,错误之处欢迎交流。
2. 关于AI的定义
谈一件事情,首先要对它有个定义。以防止争执了半天,实际没在讨论同一个概念。
每个人都在谈论AI,但对于AI的定义确定性并不强。有的人认为AI是黑客帝国一样的程序自主意识。有人认为所有的计算机技术也可以叫AI技术。

我的定义是:AI是计算机模拟人类的决策行为。决策就是做决定,做判断。在有限状态的世界中,可以认为决策==分类。
语音识别,图像识别,NLP,下棋,搜索问题,推荐问题等本质上都是分类模型。
普通的计算机工程,例如一套Saas系统,整体不是AI范畴,但其中某项具体的技术有可能用到AI技术。
3. AI爆火现象分析
3.1 大数据带来效果提升

互联网带来了大数据积累。数据是支持算法效果的基石,在我上学的时代,1M数据就属于相当大的数据了。而互联网数据,通常是以PB级别的。十几年前,搜狗输入法横空出世,效果吊打其他输入法。本质的原因是搜狗输入法引入了互联网大数据做训练。至于模型,没啥突破。语音识别,图像识别,都有了飞跃性的突破,本质上更多归功于大数据的积累。
hadoop系列的并行计算平民化导致算力暴涨,以前千百台计算机并行计算是高技术活,世界上没几家公司运用自如。现在谁都可以做了,TB级的机器学习成了家常便饭。
3.2.深度学习的突破降低了标注门槛
经典统计AI算法中,标注数据是一大门槛。也许就是最大的门槛。深度学习的突破一定程度上降低了这个门槛。还是非常值得赞赏的创新点。但我认为深度学习理论上属于微创新,并不是本质创新。深度学习带来的效果提升远远不如大数据。
深度学习的标杆应用是AlphaGo战胜人类最佳围棋手。这确实令人振奋。但之前没用深度学习的围棋程序,也有不俗的表现,至少普通人是下不过电脑的。围棋每走一步是一次决策,最终的输赢可能是100步决策的乘积。每一步提升那么一点点,100次方就是不得了的结果。所以下棋也是AI效果被严重低估,或严重高估的场景。
3.3 新应用场景拓展了想象空间
智能手机,可穿戴设备的发展。人脸识别作为ID鉴别已经非常普遍 。SIRI等在探索语音操作是否可以成为更普世的入口。但触屏设备点击天然优于语音。
智能音箱,能否成为智能家电新的控制中枢?语音识别效果的提升给人带来更大的信心。重投AI的公司谁不做智能音箱就OUT了。AI音箱销量很大,但绝大多数人买了之后都当做普通蓝牙音箱使用。
自动驾驶,所有车厂都在做,另外还有谷歌,百度等大厂强势杀入。L3级别已经成为标配。

很多AI应用场景有想象空间,但基本上还没有摆脱AI领域70多年的规律:实验室玩具容易,社会产品化难。
3.4 AI理论层并无本质突破
一个领域的巨大变革,要以理论突破为基础。
前文已经说过深度学习是微创新。而大数带来的提升是有限的,还不足以应对NP问题
3.5 创投的泡沫
此处省略500字。
4. AI三要素
AI决策的本质是用局部最优模拟全局最优。那么什么场景下这种模拟容易成立呢?
- 问题确定且不变。
- 检验合理且确定不变。
- 标注数据充足。
广告点击反馈,就是典型的三个条件都满足的场景。所以AI技术应该是这个领域的backbone
但真实世界中同时满足这3个条件的场景并不多。
4.1 问题的确定性
首先来看问题的确定性。举个例子:新闻网页的分类。什么网页是新闻网页呢?可能一开始概念是清晰的,新闻网页是互联网上最规范的一类网页。但随后问题来了:
- 人物专访算不算新闻?
- 纪实报道算不算新闻?
- 小说连载算不算新闻?
- 街道办事处公告算不算新闻?
- 知识性的小贴士算不算新闻?
问题突然变得没那么确定了。最终如何定义要看应用场景。真实世界中问题的定义不仅不确定,而且经常变来变去,不信问你们的产品经理或老板。
4.2 检验的合理性
检验的合理与确定是更难的问题。目标提的合理吗?最终的检验是开放测试还是封闭测试?用什么样的数据和什么样的方法进行测试?什么指标作为主指标?互相冲突的指标如何取舍?检验目标是前进的方向。但复杂场景下这个问题经常埋下很多雷。
4.3 标注数据
标注数据不足。绝大多数场景都是标注数据不足的。那么怎样确定标注数据量级够了呢?我的方法是:当标注更多的数据,模型结果也不会有显著变化的时候。标注是巨大的投入,有个说法叫做”有多少智能,就有多少人工“。而且标注的数据通常会随着母体的改变而过期。
所以,把一个大型的问题上来就套用AI的框架去解,通常是不合适的。因为三要素并不满足。但可以把问题确定和分解之后,找到满足AI三要素的点。
5. 关于AI工程师
我曾经遇到过一个项目,负责网页分类的几位工程师拒绝标注数据,也不屑于了解产品,但口口声声"我是机器学习工程师,我只负责利用ML框架把标注数据训练出局部最优"。近些年发现很多大厂里的AI工程师编程方面严重不及格。
首先我不太喜欢AI工程师,或机器学习工程师这样的title。我更喜欢算法工程师,策略工程师的叫法。因为前者突出技能,后者突出综合解决问题的能力。
对于算法工程师我有几条建议:
- 首先是个工程师,至少编程得及格吧。最基本的工程素养都没有,结果很难让人相信。
- 结果导向而不是方法导向。因为问题和结果不会去调整适应你的方法。
- 好的算法工程师必须是半个产品经理。了解产品,了解用户,才明白什么是对错。
- 愿意做手工活。在数据中发现规律,并乐在其中。
6. AI在公司中的定位
6.1合理期待
评价一个技术团队的工作好坏有四个维度:
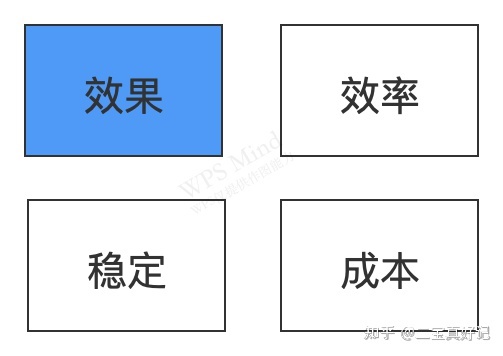
其中稳定和成本是最好衡量的。效率通常等同于项目效率。而效果则是产品表现:例如推荐系统的精准度,人脸识别的准确率等等。
效果通常是老板最关心的指标,所以最近所有公司都在抢AI大牛,恨不得一个牛人+一个公式就把公司带飞。
老板们喜欢举例头条:他们就是被推荐算法带飞的。目前这也是微博上大众认可的观点。
我不同意这个观点。
产品的效果由整个生态决定。online的推荐算法只是生态中一个环节。头条的成功更多在于offline制造了大量的迎合大众的八卦内容。至于online算法,各家大同小异。让一个环节背负整个生态是不公平的。除非原来的算法远远不及格,新算法补上漏洞,这可以有明显的提升。
尽量不要让DAU,收入等一级指标成为某个AI团队的主指标。让他们主做二级指标,同时把一级指标作为gate keepter之一就好。
6.2 如何设置算法部门
不合理的组织形式
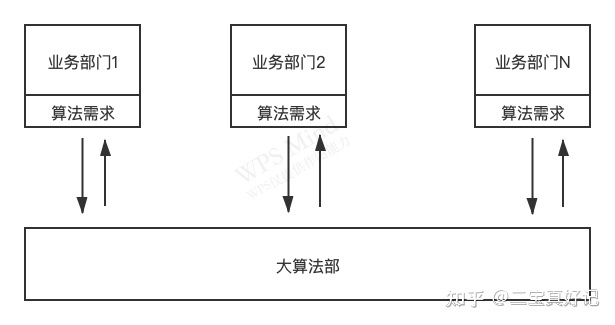
公司有一个大算法部。各个业务部门需要用到算法支持时候,向大算法部提需求。
很多公司结构都是如此。优点是共享算法工程师的资源。至于缺点嘛,那就太大了。
- 产品效果不会太好。因为效果的关键是工程师对业务的理解,策略与场景灵活结合的能力。并不是什么ML框架的运用。这种组织不利于算法工程师对业务的了解。
- 跨部门合作,加大成本。
不过有一种大算法部是可以存在的,就是研究院。如果公司花得起钱,请一帮人做研究也好,做PR也好,做新业务也好。但应该让研究院尽量少的跟其他部门进行项目合作。
合理的组织形式
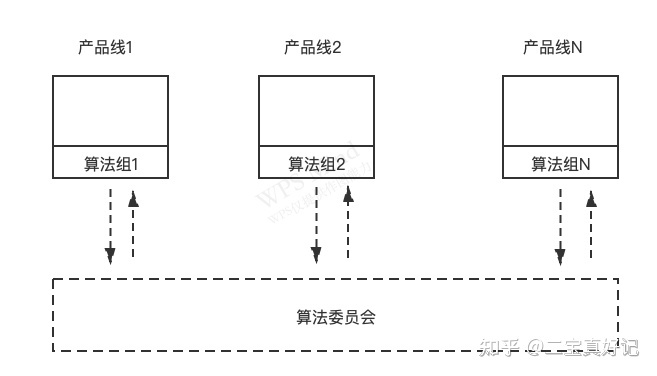
把算法工程师打散到各个产品线。也不要什么部门内部的算法中枢。然后成立一个叫做算法委员会的虚拟组织,负责培训、技术交流,工程师定级。但不参与任何的业务。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











