




文章目录
related work
- wang2024 通过级联ASR+LLM+TTS,实现speech2speech对话,但是用户音频和系统返回音频被编码成同一个token stream;当两个音频有时间交叉时,这样是不合理的;
- dGSLM 提出将用户音频和系统返回音频当成两个流处理,属于fully-duplex的系统,但是他只建模semantic token,不是实时系统;
model
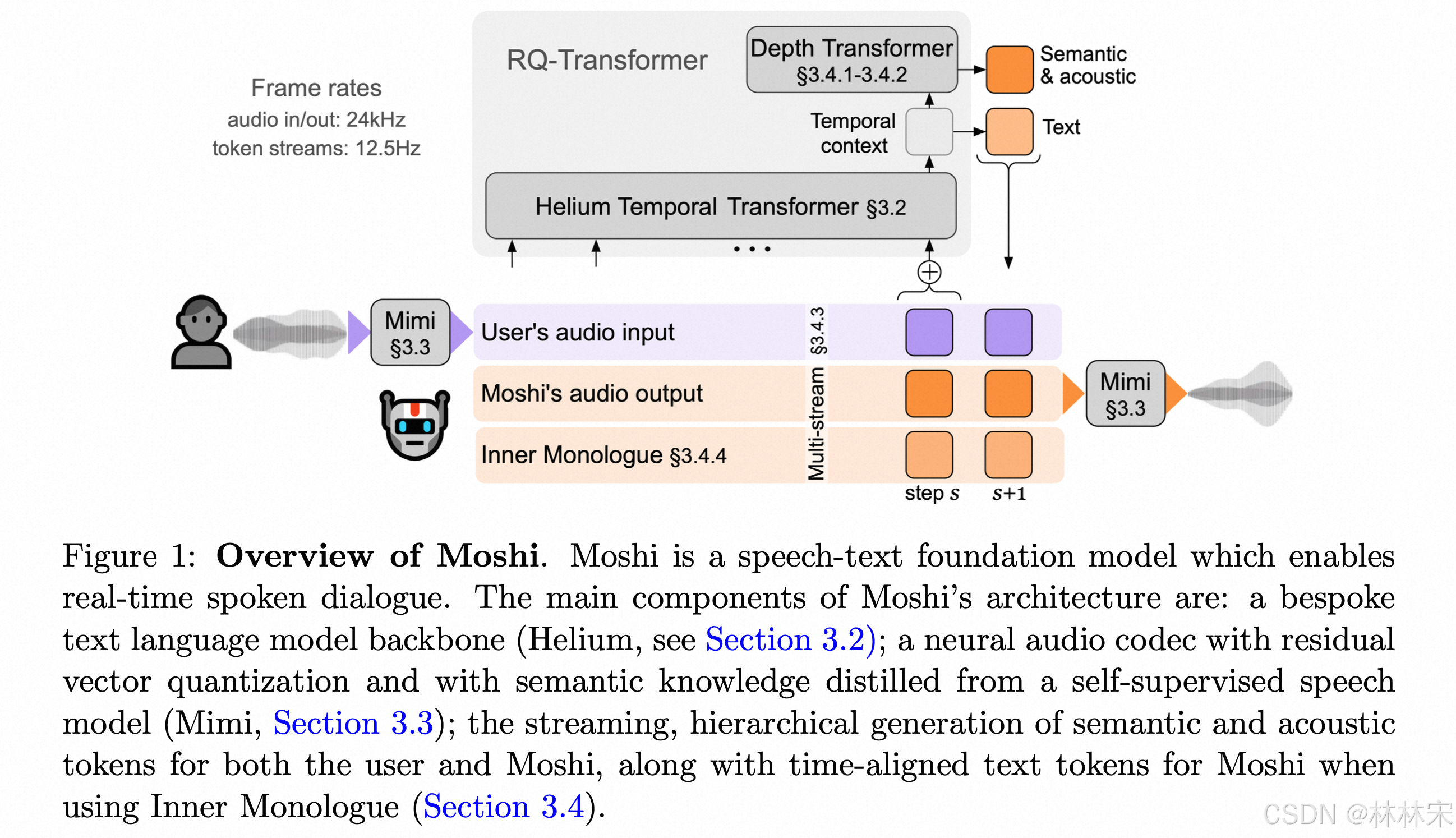
- Moshi 创新:
- 有一个基座的text LLM ,具备因果推理能力,将此能力扩展到audio上;
- 提出Inner Monologue的方式,同时建模text,semantic , acoustic token,delay的方式预测,层级建模;保证能够充分利用text模态的能力,同时具备speech2speech的能力;
- 使用Mimi,保证高质量的音频交互,同时建模semantic & acoustic 信息;
- 实时交互;并且能够生成任意的音频【voice,emotion,aoucstic condition】
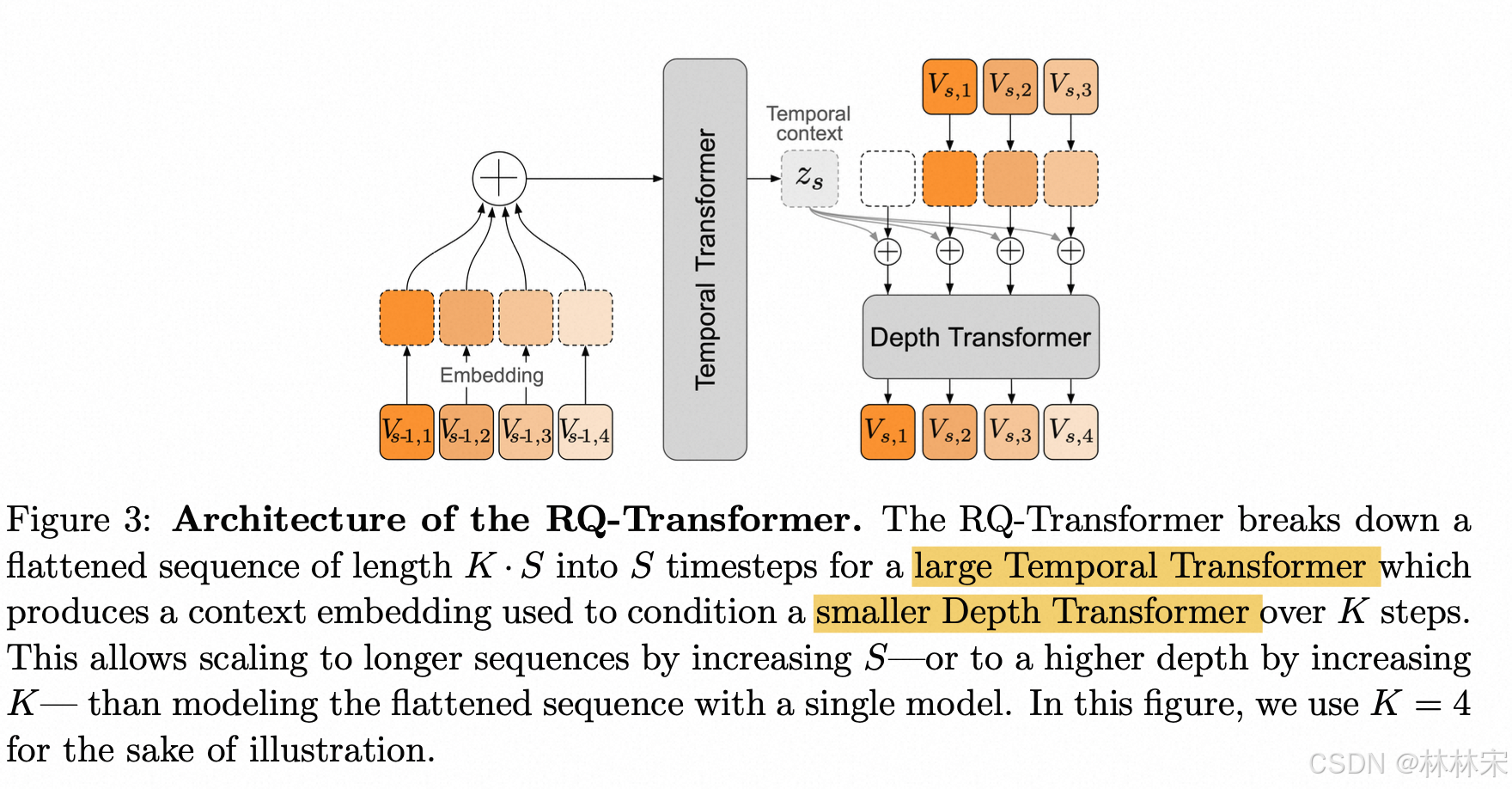
- 大的LLM先生成temporal context,只需要预测S步【text 长度】,然后depth transformer预测多个码本的结果,K步l
Audio Tokenization
- semantic tokens的预测是非因果的,需要offline manner;如果使用不同的encoder 预测semantic tokens和 acoustic tokens,计算开销会比较大;受SpeechTokenizer启发,Mimi 使用蒸馏的方法,将semantic tokens转换成可以由因果模型生成的token;从而使得流式的编解码成为可能。
- Q=8 quantizers,codebook size of N A N_A NA = 2048,12.5ms/frame,latent dimension = 512,VQ的时候,先把embedding压缩到256,量化之后再反压缩到512;小trick:训练的时候,50%的概率,encoder的结果直接送给decoder重建音频,而不经过VQ-DVQ,作者发现这样做能显著提升重建音频的质量,尤其是在低码率的时候。
- 只用对抗loss,不用重建loss,训练指标会变差,但是生成的质量会更好;
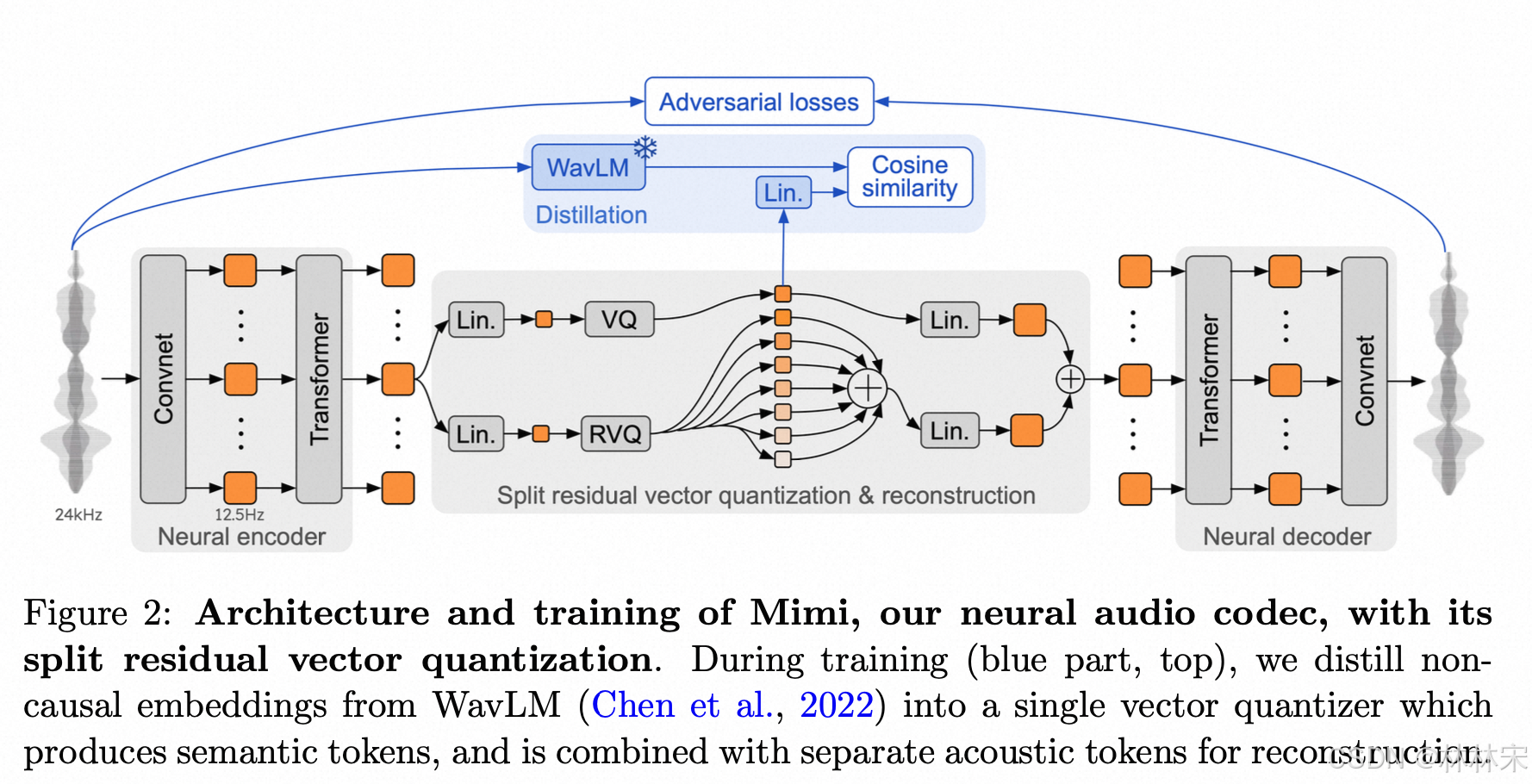
- 不再使用一个具有8个级别的单一RVQ,而是将语义信息提取到一个普通的向量量化(VQ)中,并行应用一个具有7个级别的RVQ。【这样可以在提升phone分辨准确率的时候,不用考虑重建音频质量】我们将它们的输出相加,这样两者都可以用于重建,同时去除了语义量化器残差中需要保留声学信息的限制。图2展示了这一架构,而表3则表明,这一解决方案整体上提供了更好的语义-声学平衡。
- 如果第一级是semantic token,剩下7个是第一级的RVQ,重建的音质会比较差。我们假设这是因为将语义信息提取到单个RVQ的第一级上:由于高阶量化器是对第一个量化器的残差进行操作,因此后者需要在音频质量和音素可区分性之间进行权衡。实验结果见table 3。
- WaveLM和Mimi的帧长不一致,(50ms vs 12.5ms),可以使用线性插值;
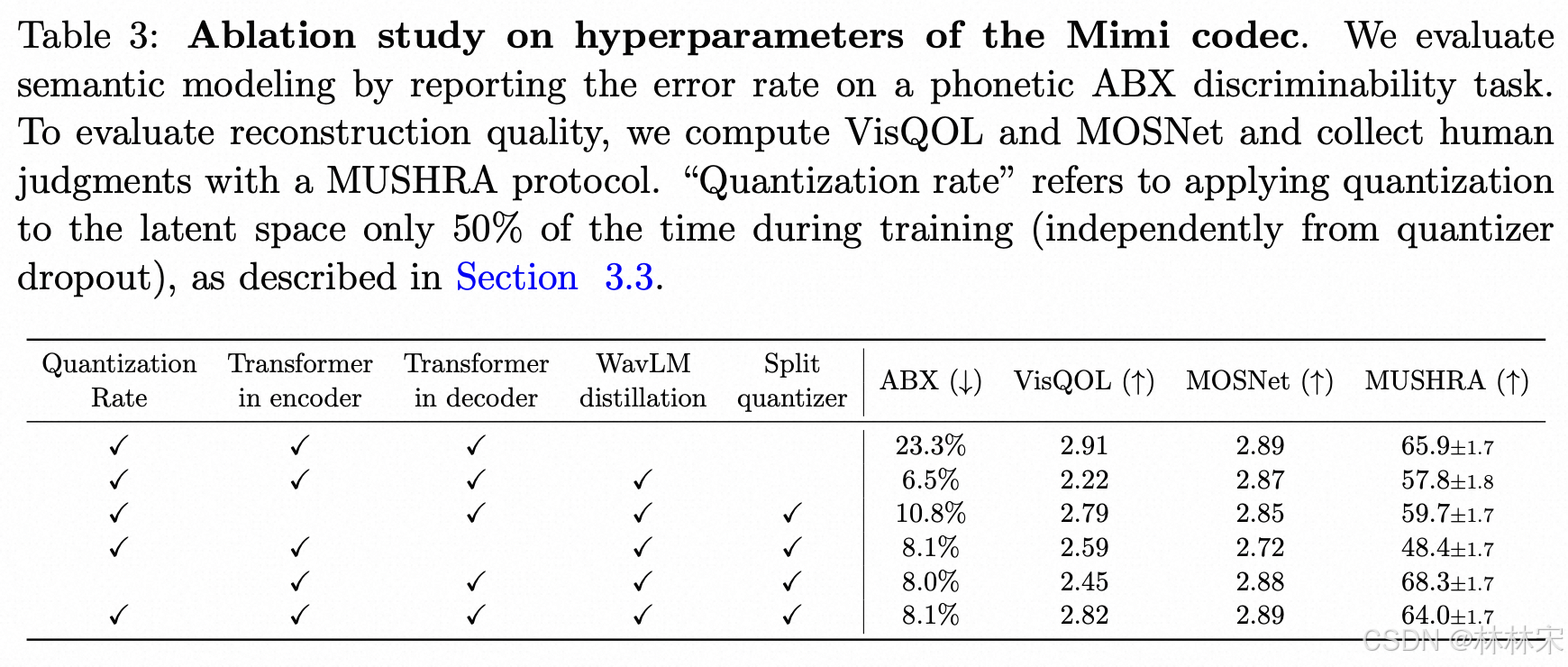
- WaveLM的蒸馏可以显著提升音素分辨率,基于transformer encoder 结构的蒸馏效果更好(更大的模型能力 & 感知野)
- 单独的RVQ可以提升重建音频质量;
Inner Monologue
- temporal transformer 预测一个text token,这个token是speech 经过whisper 识别之后,再经过SentencePiece tokenizer编码;
- 文本和audio的对齐:因为文本和音频的时长不一致,对齐问题通过引入两个特殊的token实现,【PAD, EPAD]。因为文本对应的时间戳可以从whisper获得,文本后重复的帧使用PAD表示,一直到下一个有效文本出现,上一个文本的结束用EPAD。比如【text1, PAD,PAD, EPAD,text2】。基于英文数据统计,大概有65%的概率插入特殊token
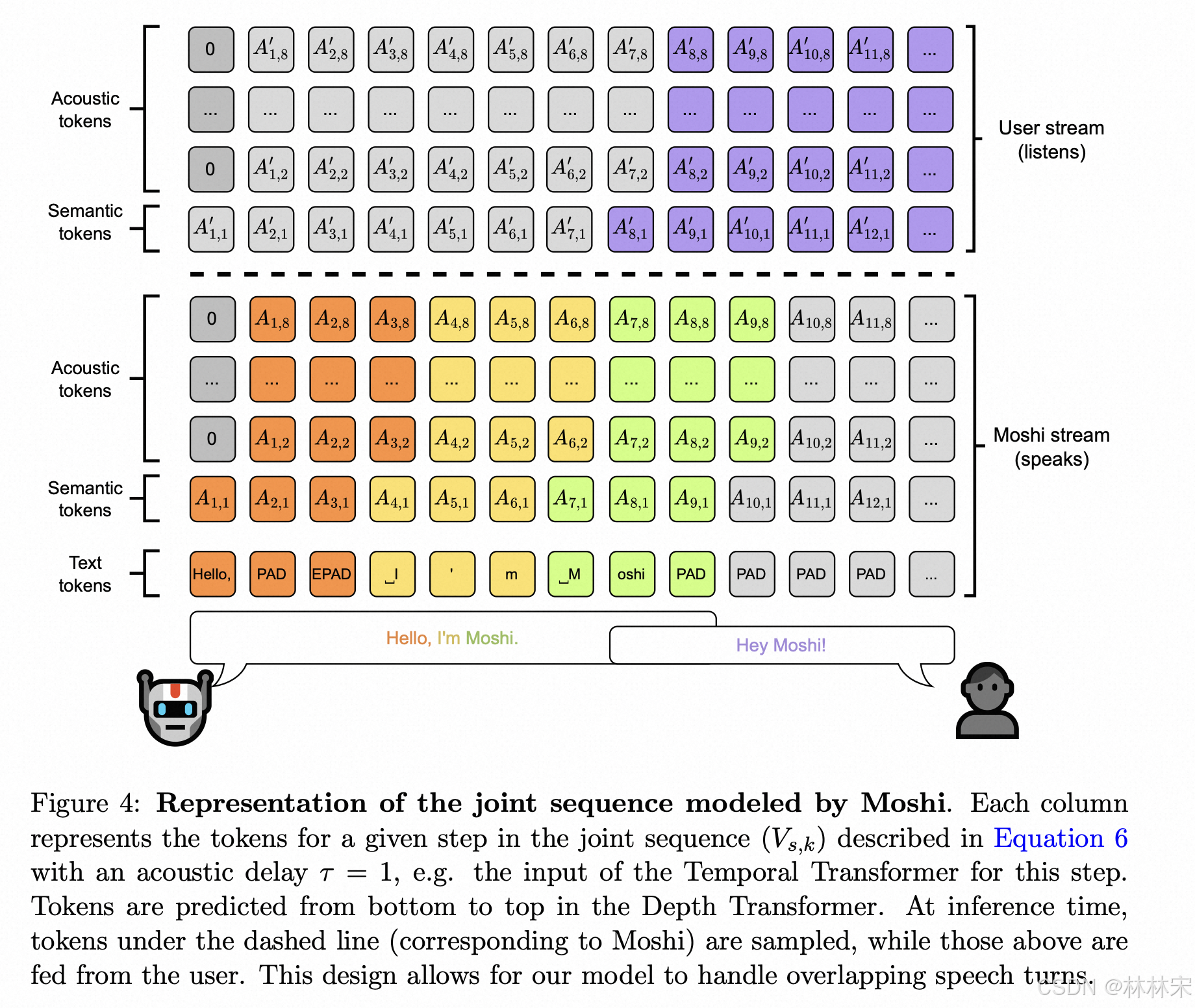

- 双流控制:
- moshi‘s speech 后边会接usr’s speech,semantic token的预测是连续的,训练的时候先预测moshi,再预测speaker;(这对于离线评估是必要的);预测speaker token的时候,text token持续输出PAD,如果需要启动回复,强制采样EPAD即可;
emperiment
dataset
- Audio data:7 million的音频数据预训练;
- 2000h Fisher dataset 的对话数据(8k 模型上采样到24k);
- 170h 精选的对话数据集;
- 后两个数据集,ask 和answer的音频已经分成不同的channel,因此随机选一个作为moshi speech,另一个作为usr speech;moshi speech需要转录文本,usr则不需要;
Speech-Text Instruct data
- Helium 是基于真实对话数据finetune之后的语言模型,更适合对话任务;
- 设定一个特定的音色作为moshi的音色,包括70种说话风格【表19】
- 鲁棒性:
- 对于用户question中说错的词,moshi 会和用户确认【 asking the user to repeat herself or to clarify the questio】
- 事实性错误的问题,回复No 【比如:Is the Eiffel Tower in Beijing?】
- 常识问题用专门的数据集加强,【比如加法问题】
- 不道德或非法的问题,拒绝回答
training stages
| stage | data | temporal lr | depth lr | step | batch_size | others |
|---|---|---|---|---|---|---|
| Helium pre-training | only text | / | / | 500k | 4.2M tokens | / |
| Moshi pre-training | 50% text + 50% audio | 3 × 1 0 − 5 3 \times 10^{−5} 3×10−5 | 2 × 1 0 − 4 2 \times10^{−4} 2×10−4 | 1 million | 16h | 文本-audio对齐; text和audio token 的delay 随机设成 0.6s / -0.6s; train text:文本嵌入和文本线性层的学习率乘以0.75; train audio: 填充标记,交叉熵损失中将它们的权重减少50% |
| Moshi post-training | 10% text + 90% audio | 3 × 1 0 − 6 3\times10^{−6} 3×10−6 | 5 × 1 0 − 5 5\times10^{−5} 5×10−5 | 10k | 8h | 处理multi-stream, 随机选择一个speaker作为moshi speaker,其他部分标记为usr, audio-text 设置可变延迟 |
| Moshi finetuning | Fisher dataset(2k h对话数据集) | 2 × 1 0 − 6 2\times10^{−6} 2×10−6 | 4 × 1 0 − 6 4\times10^{−6} 4×10−6 | 10k | 40min | 模拟真实场景overlap speech的问题 |
| intruct tuning | 170h 精选的对话数据集 | 2 × 1 0 − 6 2\times10^{−6} 2×10−6 | 2 × 1 0 − 6 2\times10^{−6} 2×10−6 | 30k | 2.7h | 固定一个音色为moshi speaker,使用instruct data |
- intruct tuning阶段的更多工作:
- usr stream 使用不同的增益;
- 混不同信噪比的不同噪声;
- 当采样新的噪声时,50%的概率插入最长30s的静音,模拟noisy to silent的情况;
- 把moshi的音频scale[0, 0.2] 到usr speech中,delay [100ms, 500ms];
- 用户音频回声增广
- TTS Training
- 也可以用于训练tts,数据前后的构造略有区别
results
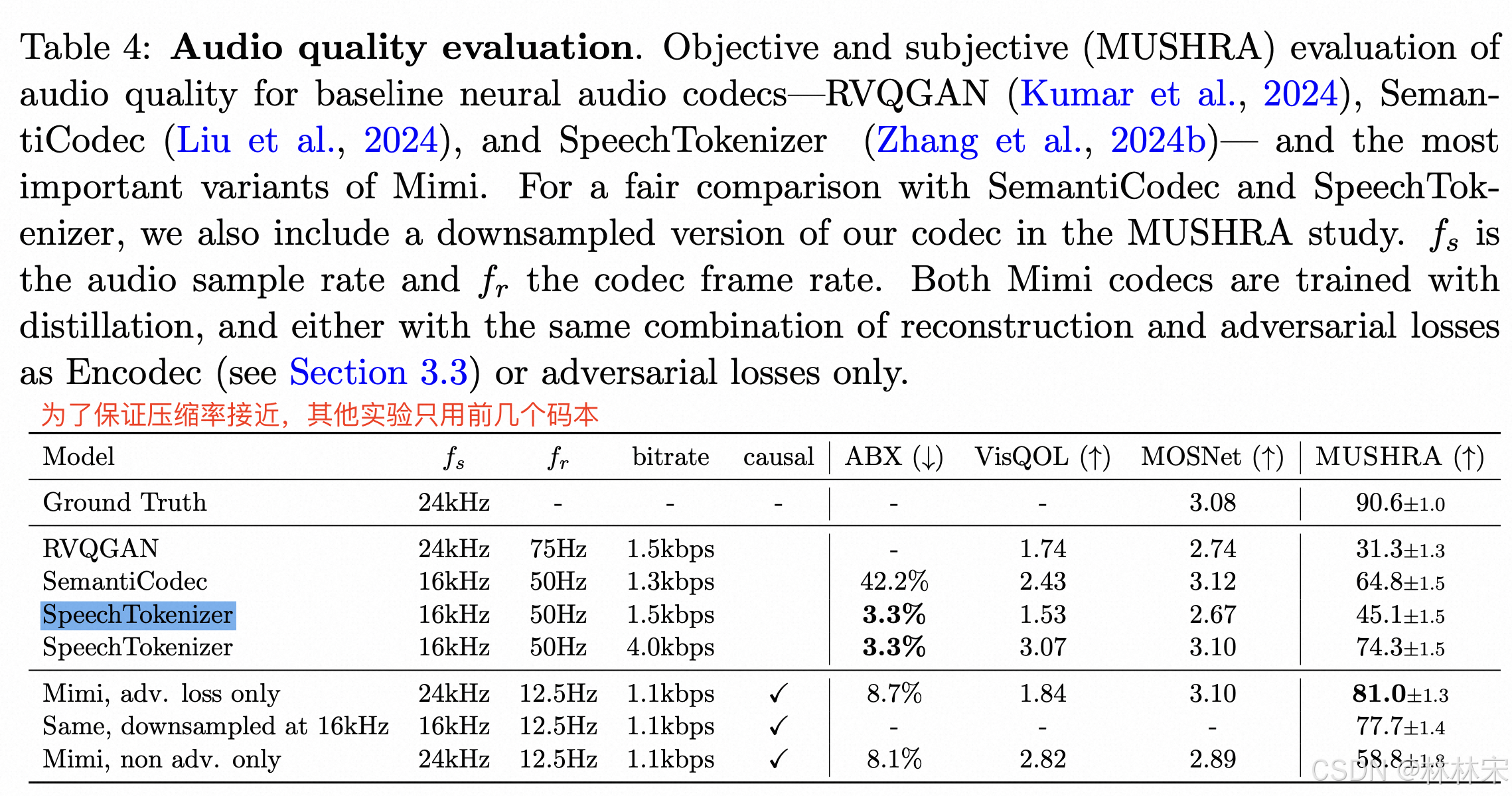
- 因为speechtokenizer没有用到全部的码本,MUSHRA低是有原因的;【如果全部用上】
speech tokenizer
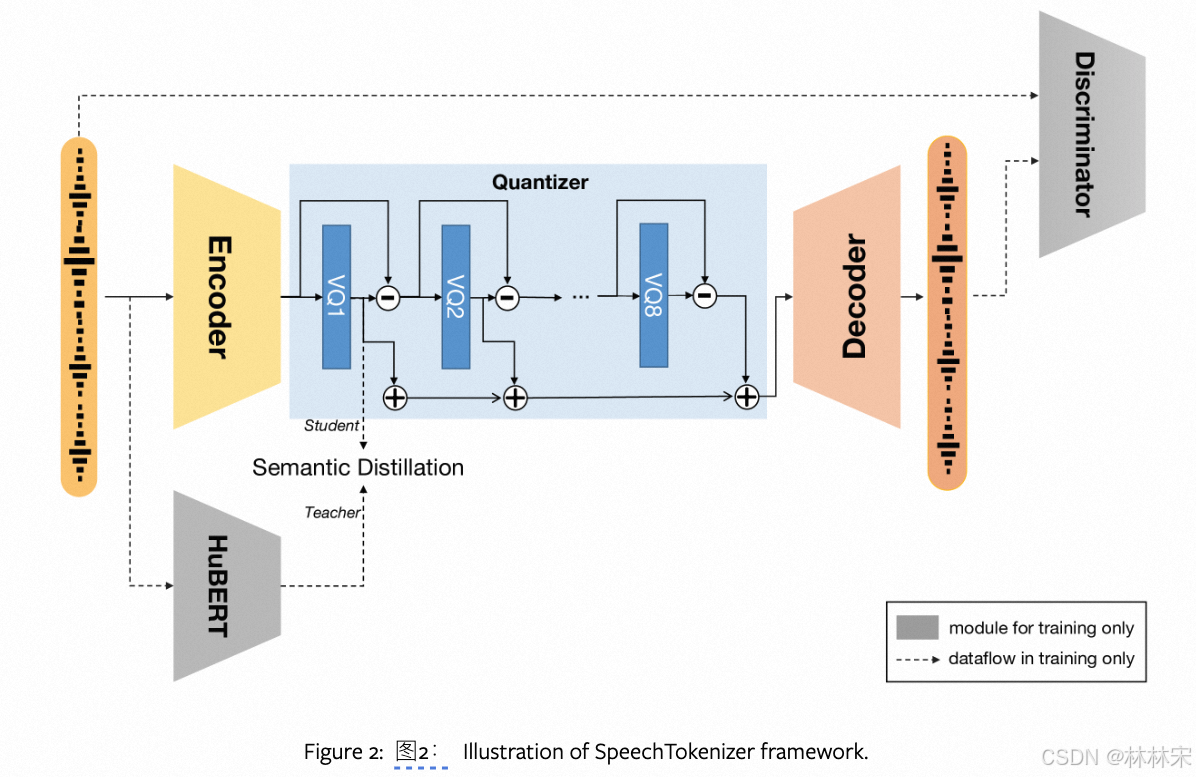
- RVQ 结构,第一级预测semantic token,使用hubert 第9层的特征作为target;embedding distill loss + pseudo index loss。
- AR 预测semantic token,NAR预测acoustic token,


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









