






 该研究介绍了一种结合唇型和文本信息的实时配音技术,用于影视剧配音。方法基于FastSpeech框架,利用PhoneEncoder和VideoEncoder捕获口型和文本特征,并通过Text-VideoAligner实现精确对齐。实验使用Lip2Wav和LRS2数据集,结果显示音频质量和口型同步度高,解决了Lip2Phone识别错误问题。
该研究介绍了一种结合唇型和文本信息的实时配音技术,用于影视剧配音。方法基于FastSpeech框架,利用PhoneEncoder和VideoEncoder捕获口型和文本特征,并通过Text-VideoAligner实现精确对齐。实验使用Lip2Wav和LRS2数据集,结果显示音频质量和口型同步度高,解决了Lip2Phone识别错误问题。
会议:2021 NIPS
单位:字节 & 清华交叉信息
作者:Chenxu Hu, wangyuxuan
abstract
motivation:给影视剧配音,通过唇型得到音素时间,辅助TTS生成语音;通过人脸识别给spk-id,指导TTS生成不同的音色。要求内容和输入的文本一致,韵律和输入的video一致(只有图像,没有音频)。
related work
- TTS: text-to-speech,Dubber的输入不仅是text,还有vedio,多模态的任务;
- Talking Face Generation:wav2lip,给语音(phone+duration),生成2D/3D的人脸+口型
- Lip to Speech Synthesis:根据video中人物的口型,生成语音。Vid2Speech/Lipper/Lip2Wav模型在做这件事情,但是会有一些字发音错误的问题,主要是因为lip reading的错误率。在Dubber任务中,已经有文本的信息,再辅助上video中口型和phone的对齐,因此会避免lip2phone识别错误的问题。
method
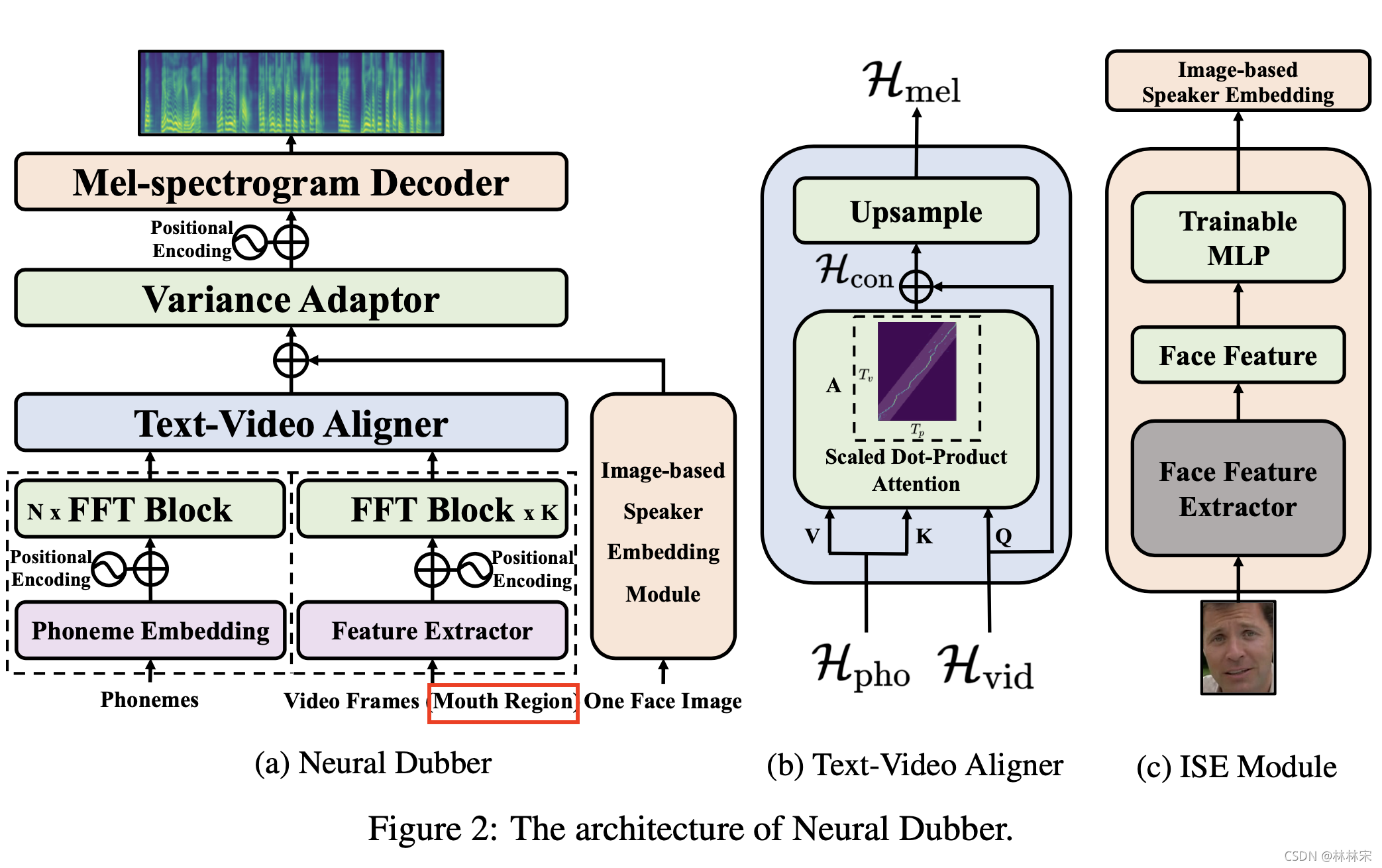
因为要实时生成配音,采用fastspeech的框架。
-
phone encoder + video encoder(只从视频中裁取唇部的图像输入)
-
Text-Video Aligner:
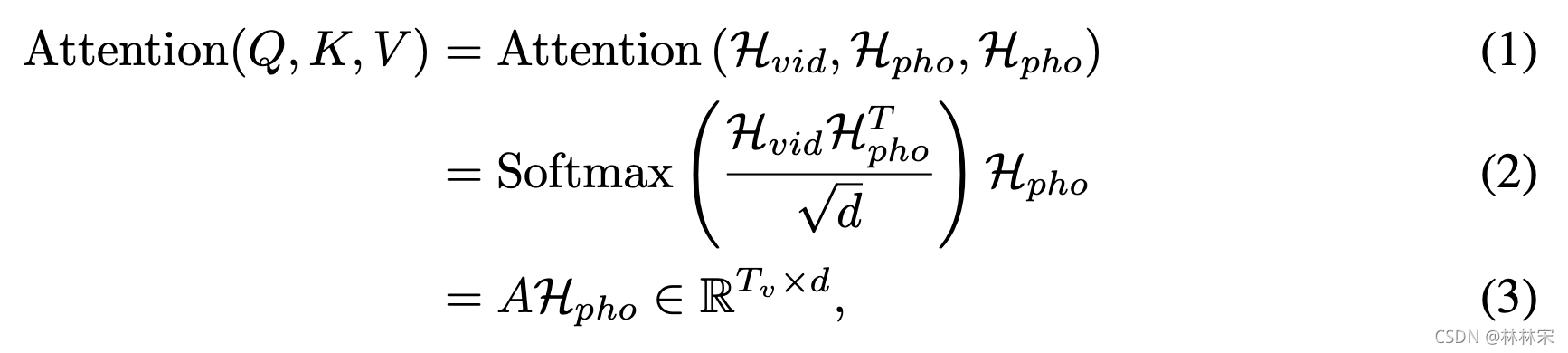
H v i d H_{vid} Hvid 实际上控制了attention的系数,精确的控制对齐; -
Image-based Speaker Embedding Module:预训练的人脸识别模型,将送入的人物图片编码成high-level embedding,然后送入ISE模块一起参与训练,生成ISE。作者认为这种方式可以让模型自己学到ISE和音色之间的相关性(比如性别、年龄)----------video的ISE与对应的音频匹配训练,没有其他用于监督训练的说话人身份信息
Experiments and Results
dataset
- 单人数据集:Lip2Wav,从youtube中拿到对应句子级别的文本;然后对video按照对应的文本进行切分,会存在部分有语音但是没有人物唇形的数据,删除不用;最后可用的数据一共9h;
- LRS2数据集:BBC的多人数据集,有video和文本;训练集29h
测试
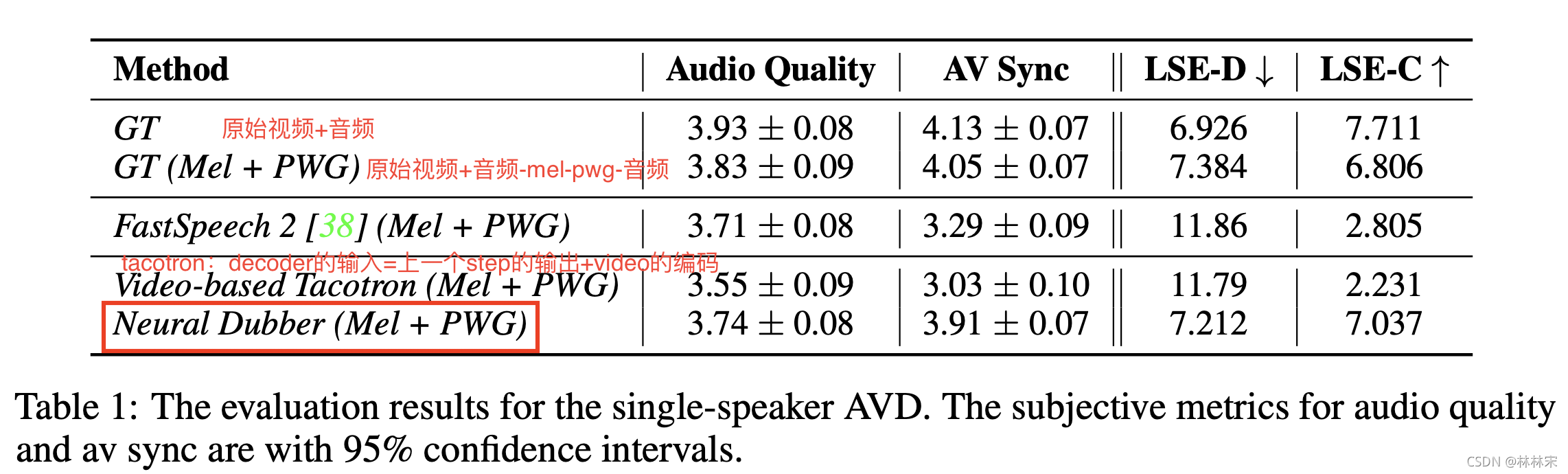
- 测试指标:生成音频的质量,以及音频内容和视频口型的一致性;
- 测试方式:主观评测(亚马逊众包)& SyncNet(开源的检测语音和口型一致)
- Lip Sync Error Distance (LSE-D) :音频和视频特征的距离,值越小一致性越高;
- Lip Sync Error Confidence (LSE-C) : 音频和视频特征一致性的置信度,值越高越好;
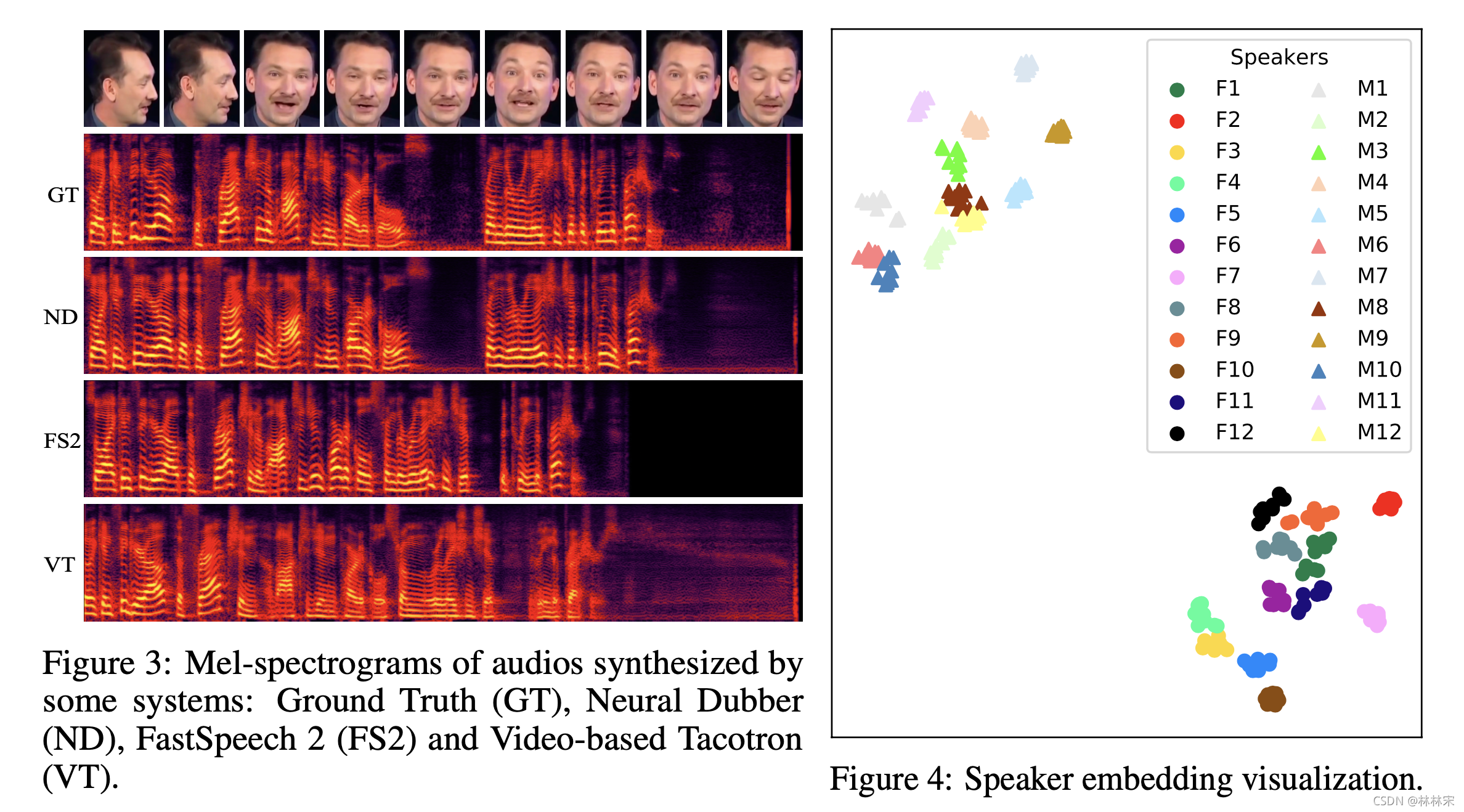
conclusion
如果演员的口型和文本对不上,infer的时候会因为不一致而出错;


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









