




 本文详细介绍了MapReduce中Shuffle机制的运行原理,包括数据分区、排序和缓存过程,以及Shuffle对MapTask和ReduceTask的影响。同时,讨论了Combiner的作用,作为局部汇总工具,减少网络传输量,但需确保不影响最终业务逻辑。
本文详细介绍了MapReduce中Shuffle机制的运行原理,包括数据分区、排序和缓存过程,以及Shuffle对MapTask和ReduceTask的影响。同时,讨论了Combiner的作用,作为局部汇总工具,减少网络传输量,但需确保不影响最终业务逻辑。
转载:https://blog.youkuaiyun.com/github_36444580/article/details/75208992
2.4.1 概述
1)mapreduce中,map阶段处理的数据如何传递给reduce阶段,是mapreduce框架中最关键的一个流程,这个流程就叫shuffle;
2)shuffle: 洗牌、发牌(核心机制:数据分区、排序、缓存);
3)具体来说:就是将maptask输出的处理结果数据,分发给reducetask,并在分发的过程中,对数据按key进行了分区和排序。
2.4.2 Shuffle结构
Shuffle缓存流程:
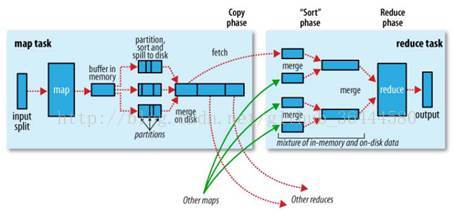
shuffle是MR处理流程中的一个过程,它的每一个处理步骤是分散在各个map task和reduce task节点上完成的。
2.4.3 partition分区
如果reduceTask的数量> getPartition的结果数,则会多产生几个空的输出文件part-r-000xx;
如果1<reduceTask的数量<getPartition的结果数,则有一部分分区数据无处安放,会Exception;
如果reduceTask的数量=1,则不管mapTask端输出多少个分区文件,最终结果都交给这一个reduceTask,最终也就只会产生一个结果文件 part-r-00000;
例如:假设自定义分区数为5,则
(1)job.setNumReduceTasks(1);会正常运行,
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 136
136

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









