






 本文介绍了XML文件的基本结构、特点及应用,详细讲解了如何使用Java中的DOM解析器读取和解析XML文件,并展示了如何创建、修改和输出XML文档。
本文介绍了XML文件的基本结构、特点及应用,详细讲解了如何使用Java中的DOM解析器读取和解析XML文件,并展示了如何创建、修改和输出XML文档。
一个典型的XML文件
<?xml version="1.0" encoding="UTF-8"?>
<books>
<book id="001">
<bookinfo>
<title>雪中悍刀行</title>
<author>烽火戏诸侯</author>
</ bookinfo>
</book>
<book id="002">
<bookinfo>
<title>圣墟</title>
<author>辰东</author>
</ bookinfo>
</ book>
<book id="003">
<bookinfo>
<title>凡人修仙传</title>
<author>忘语</author>
</bookinfo>
</ book>
<books>XML的由来:
1、XML(可扩展标记语言)是从标准通用标记语言(SGML)衍生而来的文件格式,SGML是从70年代就被开始用来描述复杂的文件结构,它有两个跟重要的简化版本:HTML和XML。其中XML被设计成在Internet上处理和转化信息的工具。
2、在XML中用户可以自定义标记、属性,进而形成自己的数据格式和规范,并验证数据文件是否符合格式规范,换句话说,用户可以自己决定数据文件中应该有哪些内容、应该以何种结构组织数据,并根据自定义的规则对获得的数据文件进行校验。
XML的作用:
1、XMl文件直观、清晰,能够表达具有复杂的层次结构或者重复的数据内容;
2、使用XML标记语言可以做到数据或数据结构在任何编程语言环境下的共享。例如我们在某个计算机平台上用某种编程语言编写了一些数据或数据结构,然后用XML标记语言进行处理,那样的话,其他人就可以在其他的计算机平台上来访问这些数据或数据结构,甚至可以用其他的编程语言来操作这些数据或数据结构了。这就是XML标记语言作为一种数据交换语言存在的价值。
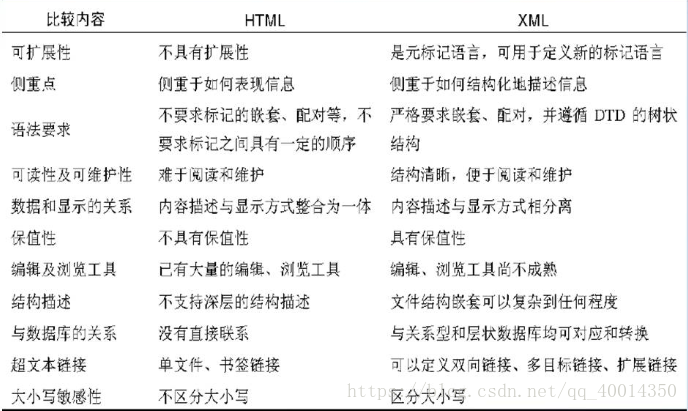
HTML VS XML:
虽然两者都来自于SGML,但存在很大差异:
1、在XMl中对大小写是敏感的;
2、在HTML中允许省略部分结束标签,但XML不允许;
3、在XML中,属性值必须以“ ”括起来;
4、在XML中,每个属性必须有属性值。
XML的优势:
XML最大的优势在于它能对各种编程语言编写的数据进行管理,使得在任何平台下都能通过解析器来读取XMl数据。可以归纳为以下几点:
1、数据的搜索:在XML中可以提取文档中任何位置的数据;
2、数据的显示:XML将数据的结构和数据的显示形式分开,根据需要使数据呈现多种显示方式。如HTML、PDF等格式。
3、数据的交换:XML标记语言的语法非常简单,可以通过解析器在任何机器上解读。并可以在各种计算机平台上使用。逐渐成为一种数据交换语言。
XML文档的结构:
XML文档主要有7个主要部分:序言码、处理指令、根元素、元素、属性、CDATA和注释。
1、序言码:包含XML声明、处理指令

2、根元素:根元素是XML文档的主要部分,包含文档数据以及描述数据结构的信息

3、元素:是XML文档的重要组成部分,在XML文档中必须存在元素。XML文档的元素一般是由标记头、标记末和标记间的字符串数据构成,如下代码所示:

XML文档中的第一个元素被称为根元素,在任何一个XML文档中又且只有一个元素被称为根元素。其余所有元素都是子元素,子元素必须正确的嵌套在根元素中。
标记间的字符串数据就是该元素的值,在XML中,如果元素的值中存在空格,那么这些空格将按原样解析出来
实体:
预定义实体表,如下图所示:
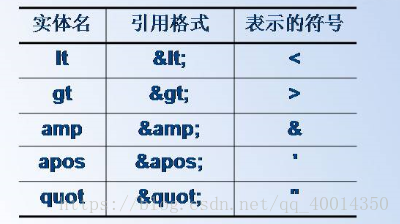
实体在XML文档中的一般引用格式如下:
&实体名;
属性:
属性是用来修饰某个元素的,如:

关于元素的属性需注意如下几个问题:
1、属性的值必须用引号括起来,如:atr1="a"或atr2="aa";
2、元素的属性以名和值成对出现;
3、用来修饰同一个元素的属性的属性名不能相同;
4、属性值不能包含“&”,“ ' ”,“<”等字符;
CDATA节:
通过CTATA节可以通知分析器,在CDATA节包含的字符中没有标记。这样,如果文档包含可能会出现的标记字符,但我们又不是把它当做标记来使用,而只是属于文本字符,那么使用CDATA节来创建这样的文档就容易的多。CDATA节主要用于脚本语言内容、示例XML文档内容和HTML内容。如下所示
<?xml version="1.0" encoding="gb2312"?>
<程序>
<title>test</title>
<内容>
<[CDATA[
if(20<10){
retur "你好";
}else{
retum "thello";
}
]]>
</内容>
</程序>注意:在"<![CDATA["和"]]>"之间不能再加入CDATA节或“]]>”
注释:
XML可以包含注释,也可以没有注释

XML文档结构总结:
1、XML文档应当以一个文档头开始:

2、文档头之后通常是文档类型定义(可以省略)

3、XML文档的正文以一个根元素开始,根元素中包括其他一些元素
4、在元素中可以包含子元素、文本和属性;元素、文本和属性构成了XML的主要部分。
在XML中可能出现的其他标记还有:
1、字符引用:&#d;或&#xh;分别引用十进制和十六进制的Unicode字符
2、实体字符:“<;”、“>;”、“";”等等
3、CDATA:<![CDATA[.......]]>标记用来处理包含了“<”,“>”和“&”之类特殊的字符文本,对特殊字符 不解释为XML文档的标记
4、处理指令:<?......?>用来标记处理指令,在处理XML时为解析器提供指示
5、注释:<!--......-->用来在XML文件中加入注释信息
解析XML文件:
在处理XML文件之前,需要使用解析器来解析XML文件。在Java中提供了两种XML解析器:
DOM(文档对象模型)解析器
SAX(Simple API for XML)解析器
解析器是一个程序(一组Java类),用来读入一个XML文件,首先确认文件内容正确,然后将XML的内容分解为各种元素,使开发人员可以对其他的元素分别处理。
DOM解析器的接口已经被W3C组织标准化定义了,可以将读入的XML文件转化为文档树结构交给程序员来处理,由不同的软件厂商如Sun、IBM、Apache提供实际标准接口的解析器,在通常情况下都可以很方便的实现大多数的编程需要。
一切都是节点:
1、Node对象:DOM结构中最为基本的对象;
2、Document对象:代表整个XML的文档由多个实现Node接口的类的对象构成
3、Attr对象:表示ELement对象中的属性
4、Element对象:代表XML文档中的标签元素
5、Text:表示Element或Attr的文本内容(在XML中称为字符数据)
使用DOM解析XML文件:
1、通过DocumentBuilderFactory获得一个DocumentBuilder对象
DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();
DocumentBuilder builder = factory.newDocumentBuilder();
2、读入一个XML文档
Document doc = builder.parse(new file(XML文件路径));
3、 获取XML文档的根节点
Element root = doc.getDocumentElement();
Node接口定义了getTagName、getChildDodes、getFirstChild、getNextSibling方法;
Element接口定义的方法包括getAttributes、getAttribute等;
Text接口提供了getData方法;
例如:
....
//获得DocumentBuilder
DocumentBuilderFactoryfactory= DocumentBuilderFad tory.newInstance();
DocumentBuilder builder= factory.newDocumentBuilder();
//加载XML文件
Documentdoc= builder.parse( xmlFile);
//获取根节点
Elementroot = doc.getDocumentElement();
//从XML的根节点开始遍历处理XML文件中的子元素
NodeList books= root.getChildNodes();
for(inti =0;i< bool ks.getLength();i++)
{
Node child = books.item(i);
//判晰是否将空白区域当作是学元素处理了
if (childgetNodeType()== Node.ELEHENT_NODE)
{
//查找到个Book元素
Elementbool kElement= (Element) child;
Bookb= new Book();
//使用元素的同性作为bookid
b.setBookid(bookElementgetAttribute("id'));
节点的相关操作:
1、修改元素的文本内容:node.getFirstChild().setNodeValue(elemValue);
2、添加子元素: Text newText = doc.crdateTextNode("233.3");
Element newElement = doc.createElement("total");
newElement.appendChild(newText);
parent.insertBefore(newElement,parent,getFipstChild());
或parent.appendChild(newElement);
3、删除元素:thisNode.getParentNode().removeChild(thisNode);
4、替换子元素:parent.replaceChild(newElement,oldelement) ;
5、设置元素属性:element.setAttribute(“attributeName“,“attributeValue”);
6、删除元素属性:element.removeAttribute("attributeName");
生成XML文档:
经过修改或是通过创建节点构建的DOM文档还可以输出到一个XML文件中。
可以通过DocumentBulider类的newDocument方法得到一个空的DOM文档
//method one
XmlDocument xmlDoc = (XmlDocument)doc;
xmlDoc.write(new FileOutputStreame(new File(uri)));
//method two
DOMSource source = new DOMSource(doc);
StreamResult sr = new StreamResult(new FileOutputStream(new File(uri)));
TransformerFactory = TransformerFactory.newInstance();
Transformer ttran = tf.newTransformer();
ttran.transform(source,sr);

















 60
60

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









