




摘要
最近,纯基于attention的神经网络被证明能够用于图像理解任务,例如图像分类。这些高性能的Vision Transformers需要使用数亿张图像和庞大的基础设施进行预训练,因此限制了它们的普及。
在本工作中,我们仅在ImageNet上训练,生成了具有竞争力的无Convolution的Transformers。我们在单台计算机上训练它们,不到3天即可完成。我们的参考Vision Transformer(86M参数)在ImageNet上实现了83.1%的top-1准确率(single-crop),且未使用外部数据。
更重要的是,我们引入了一种专门针对Transformers的Teacher-Student策略。它依赖于一个Distillation Token,确保Student通过attention从Teacher学习。我们展示了这种基于token的蒸馏方法的优势,特别是在使用ConvNet作为Teacher时。
这一方法使得我们的模型在ImageNet上达到了85.2%的准确率,并且在迁移到其他任务时表现同样出色,与ConvNets相比具有竞争力。我们公开了我们的代码和模型。
1 引言
卷积神经网络(Convolutional Neural Networks)长期以来一直是图像理解任务的主要设计范式,这一点最初在图像分类任务中得到了验证。它们成功的一个关键因素是大规模训练集的可用性,即ImageNet [13, 42]。
受Attention-based模型在自然语言处理(Natural Language Processing, NLP)中的成功 [14, 52] 启发,越来越多的研究开始关注在ConvNets中引入Attention机制的架构 [2, 34, 61]。最近,一些研究者提出了混合架构,将Transformer的组件移植到ConvNets中,以解决视觉任务 [6, 43]。
Dosovitskiy等人 [15] 提出的Vision Transformer(ViT)是一种直接继承自自然语言处理 [52] 的架构,但其应用于图像分类时,输入是原始的图像Patch。他们的论文展示了使用Transformers在一个大规模的私有标注图像数据集(JFT-300M [46],包含3亿张图像)上训练所取得的卓越结果。该论文的结论指出,Transformers“在训练数据不足的情况下泛化能力较差”,并且这些模型的训练需要大量的计算资源。
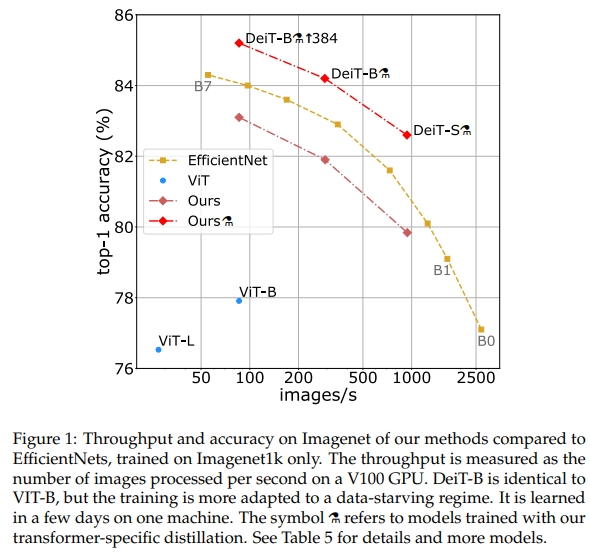
在本文中,我们在单个8-GPU节点上训练了一个Vision Transformer,在两到三天内完成(预训练53小时,可选的微调20小时)。该模型在参数量和计算效率上与ConvNets具有竞争力,并且仅使用ImageNet作为训练集。我们基于Dosovitskiy等人 [15] 提出的Visual Transformer架构,并结合了timm库 [55] 中的改进。通过我们的数据高效图像Transformer(Data-efficient image Transformers, DeiT),我们在现有结果的基础上取得了显著提升,见图1。我们的消融研究详细分析了超参数和训练成功的关键因素,例如重复增强(Repeated Augmentation)。
我们还探讨了另一个问题:如何对这些模型进行蒸馏?我们提出了一种基于Token的策略,专门用于Transformers,并称之为 DeiT⚗,它能有效替代传统的蒸馏方法。
总结而言,我们的工作主要贡献如下:
- 我们证明了不含卷积层的神经网络可以在ImageNet上实现与当前最先进模型(State-of-the-art)相竞争的结果,并且无需外部数据。 这些模型在单个4-GPU节点上用时三天即可完成训练。我们的两个新模型DeiT-S 和 DeiT-Ti 参数更少,可视为ResNet-50和 ResNet-18 的对应版本。
- 我们提出了一种新的蒸馏方法,基于Distillation Token(蒸馏Token),它与Class Token的作用类似,但目标是复现Teacher估计的标签。这两个Token通过Attention机制在Transformer中交互。该专门针对Transformers的策略比传统的蒸馏方法效果更优。
- 有趣的是,我们的蒸馏策略使得Image Transformers能从ConvNet中学习得比从另一个性能相当的Transformer中更多。
- 我们在ImageNet上预训练的模型,在多个流行的公开基准数据集上表现出色,适用于不同的下游任务,如细粒度分类。这些数据集包括CIFAR-10、CIFAR-100、Oxford-102 Flowers、Stanford Cars 和 iNaturalist-18/19。
论文结构如下:
我们在第2节回顾相关工作,并在第3节重点介绍用于图像分类的Transformers。第4节介绍我们提出的Transformer蒸馏策略。第5节进行实验分析,并将我们的模型与ConvNets及其他最新Transformers进行比较,同时评估我们的Transformer专属蒸馏方法的有效性。第6节详细介绍我们的训练方案,包括对数据高效训练方法的深入消融研究,以解析DeiT成功训练的关键要素。最后,我们在第7节给出结论。
2 相关工作
图像分类是计算机视觉的核心任务,通常被用作衡量图像理解进展的基准。任何在该任务上的进步通常也会促进其他相关任务的提升,例如目标检测或图像分割。自2012年的AlexNet [32] 以来,ConvNets 在该基准上占据主导地位,并已成为事实上的标准。ImageNet数据集 [42] 上的最先进模型(State-of-the-art)的演变,反映了卷积神经网络架构及其学习方法的进步。
尽管曾有多次尝试使用Transformers进行图像分类 [7],但直到最近,其性能仍逊色于ConvNets。然而,结合了ConvNets和Transformers(包括Self-Attention机制)的混合架构,近年来在图像分类 [56]、目标检测 [6, 28]、视频处理 [45, 53]、无监督目标发现 [35] 以及统一文本-视觉任务 [8, 33, 37] 等方面展现出具有竞争力的结果。最近,Vision Transformer(ViT)[15] 在ImageNet上取得了与最先进方法相当的性能,且未使用任何卷积结构。这一成果尤为显著,因为ConvNets在图像分类任务上的成功得益于多年的调优和优化 [22, 55]。然而,该研究 [15] 指出,想要使Transformer在图像任务上有效,必须在大规模精心整理的数据集上进行预训练。在本论文中,我们在仅使用ImageNet1k的情况下,实现了强大的性能,而无需依赖大规模的训练数据集。
Transformer架构 由Vaswani等人 [52] 首次提出,用于机器翻译,并已成为所有自然语言处理(NLP)任务的参考模型。许多图像分类ConvNets的改进也受到Transformers的启发。例如,Squeeze and Excitation [2]、Selective Kernel [34] 和 Split-Attention Networks [61] 等方法,都采用了类似于Transformer Self-Attention(SA)机制的技术。
知识蒸馏(Knowledge Distillation, KD由Hinton等人 [24] 提出,是一种训练范式,在该范式下,Student模型利用来自强Teacher网络的“Soft”标签进行学习。这些Soft标签是Teacher模型Softmax函数的输出向量,而不仅仅是得分最高的“Hard”标签。这样的训练能够提高Student模型的性能(或者,也可以将其视为将Teacher模型压缩到一个更小的Student模型中)。一方面,Teacher的Soft标签具有类似标签平滑(Label Smoothing)[58] 的作用;另一方面,正如Wei等人 [54] 所示,Teacher的监督能够考虑数据增强的影响,而数据增强有时会导致真实标签与图像之间的错位。例如,假设一张图像的标签是“猫”,但它实际展示的是一个宽广的风景,而猫只是角落里的一个小物体。如果数据增强的裁剪部分不再包含猫,那么这将隐式地改变该图像的标签。KD可以以Soft的方式将归纳偏差 [1] 传递到Student模型,而不是像在Teacher模型中那样以Hard的方式固化。例如,使用ConvNet作为Teacher可以在Transformer模型中引入卷积的归纳偏差,这可能是有益的。在本文中,我们研究了使用ConvNet或Transformer作为Teacher对Transformer Student进行蒸馏的效果。我们提出了一种专门针对Transformers的新蒸馏方法,并展示了其优越性。
3 Vision Transformer:概述
在本节中,我们简要回顾与Vision Transformer相关的基础知识[15, 52],并进一步讨论位置编码和分辨率问题。
多头自注意力层(Multi-head Self Attention, MSA)。注意力机制基于一个可训练的关联记忆,其中包含(Key, Value)向量对。查询向量 q ∈ R d q \in \mathbb{R}^d q∈Rd 通过内积与 k k k 个Key向量(打包成矩阵 K ∈ R k × d K \in \mathbb{R}^{k \times d} K∈Rk×d)进行匹配。然后,这些内积被缩放,并通过Softmax函数归一化,以获得 k k k 个权重。注意力的输出是 k k k 个Value向量(打包成 V ∈ R k × d V \in \mathbb{R}^{k \times d} V∈Rk×d)的加权和。对于一组 N N N 个查询向量(打包成 Q ∈ R N × d Q \in \mathbb{R}^{N \times d} Q∈RN×d),最终输出一个大小为 N × d N \times d N×d 的矩阵:
Attention ( Q , K , V ) = Softmax ( Q K T d k ) V (1) \text{Attention}(Q, K, V) = \text{Softmax}\left(\frac{Q K^T}{\sqrt{d_k}}\right)V\tag{1} Attention(Q,K,V)=Softmax(dk
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











