






一:DeepFM算法的提出
由于deepFM算法结合了因子分解机和深度神经网络算法在特征学习中的优点:同时提取到了底阶组合特征和高阶组合特征,所以被广泛利用。
在DeepFM算法中,FM算法负责一阶特征和由一阶特征两两组合而成的二阶特征进行特征提取,DNN算法负责对输入的一阶特征进行全链接操作而形成的高阶特征进行特征抽取。
具有以下特点:
1,结合了广度和深度模型的优点,联合训练FM和DNN模型,同时学习低阶特征组合和高阶特征组合。
2,端到端模型,无需特征工程
3,FM模块和DNN模块共享相同的输入和Embedding victor,训练更高效
4,评估模型时,用到了基尼系数。
二:DeepFM算法结构图
算法整体结构图如下所示:
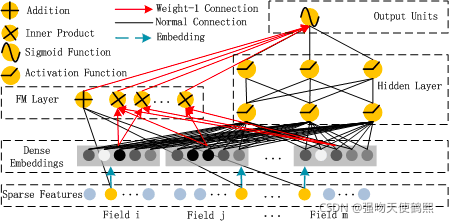
其中,DeepFM的输入可由连续型变量和类别型变量共同组成,且类别型变量需要进行One-Hot编码。而正由于One-Hot编码,导致了输入特征变得高维且稀疏。
应对的措施是:针对高维稀疏的输入特征,采用Word2Vec的词嵌入(WordEmbedding)思想,把高维稀疏的向量映射到相对低维且向量元素都不为零的空间向量中。
由上面网络结构图可以看到,DeepFM 包括 FM和 DNN两部分,所以模型最终的输出也由这两部分组成:
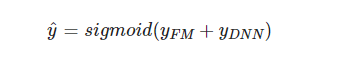
下面,把结构图进行拆分。首先是FM部分的结构:
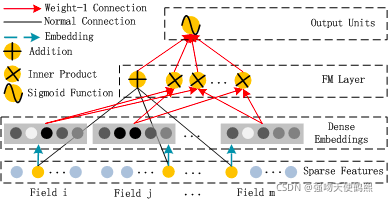
FM 部分的输出如下:
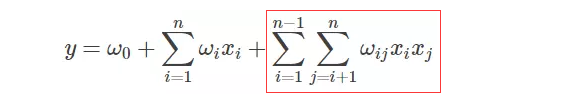
这里需要注意三点:
这里的wij,也就是<vi,vj>,可以理解为DeepFM结构中计算embedding vector的权矩阵(看到网上很多文章是把vi认为是embedding vector,但仔细分析代码,就会发现这种观点是不正确的)。
由于输入特征one-hot编码,所以embedding vector也就是输入层到Dense Embeddings层的权重.在我的前面的Fnn文章中,对这点阐述的很详细
Dense Embeddings层的神经元个数是由embedding vector和field_size共同确定,再直白一点就是:神经元的个数为embedding vector*field_size。
然后是DNN部分的结构:
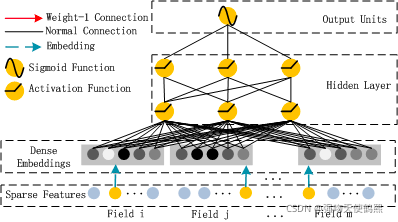
这里DNN的作用是构造高维特征,且有一个特点:DNN的输入也是embedding vector。所谓的权值共享指的就是这里。
关于DNN网络中的输入a处理方式采用前向传播,如下所示:
这里假设a(0)=(e1,e2,…em) 表示 embedding层的输出,那么a(0)作为下一层 DNN隐藏层的输入,其前馈过程如下。
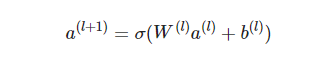
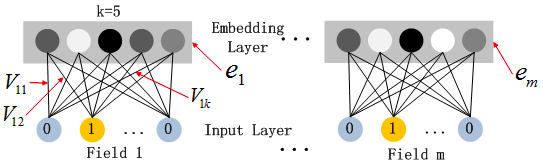
子网络设计时的两个要点:
1,不同field特征长度不同,但是子网络输出的向量需具有相同维度;
2,利用FM模型的隐特征向量V作为网络权重初始化来获得子网络输出向量;
这里的第二点可以这么理解,如上图假设k=5,对于输入的一条记录,同一个field只有一个位置是1,那么在由输入得到dense vector的过程中,输入层只有一个神经元起作用,得到的dense vector其实就是输入层到embedding层该神经元相连的五条线的权重,即vi1,vi2,vi3,vi4,vi5。这五个值组合起来就是我们在FM中所提到的Vi。文中将FM的预训练V向量作为网络权重初始化替换为直接将FM和DNN进行整体联合训练,从而实现了一个端到端的模型。
假设子网络的输出层为:
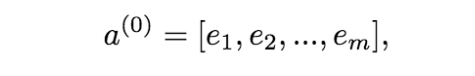
DNN网络第l层表示成:
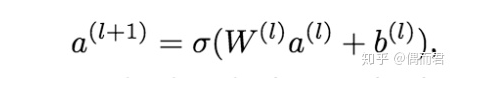
假设一共有H个隐藏层,DNN部分对CTR预测结果可以表示为:
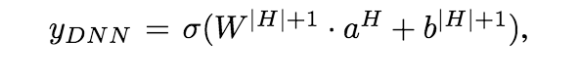
三:DeepFM重要参数
文中通过在Criteo数据集和Company*数据集进行大量实验,证明DeepFM在效果上超越了目前最优的模型,效率上的与当前最优模型相当。实验评价指标采用AUC和Logloss两个离线指标。
1,激活函数
relu 函数和 tanh 函数比sigmod函数效果更好。
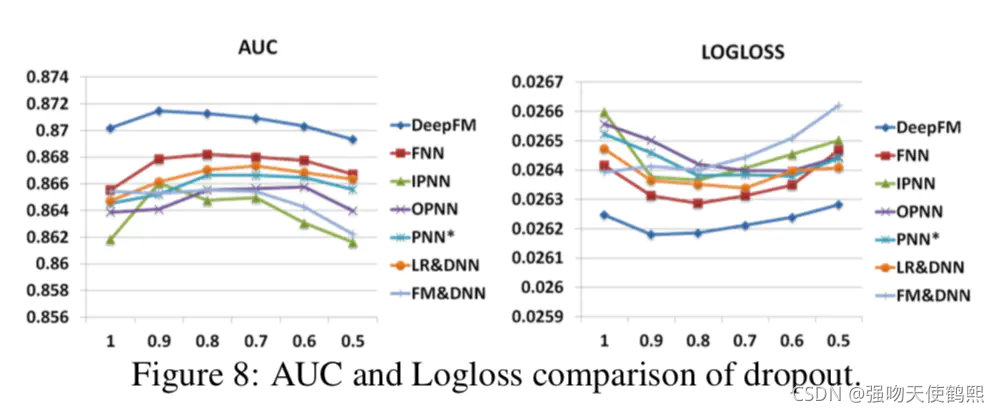
2,Dropout
采用适合的随机性能够加强模型的鲁棒性,建议采用dropout比率在0.6~0.9之间。
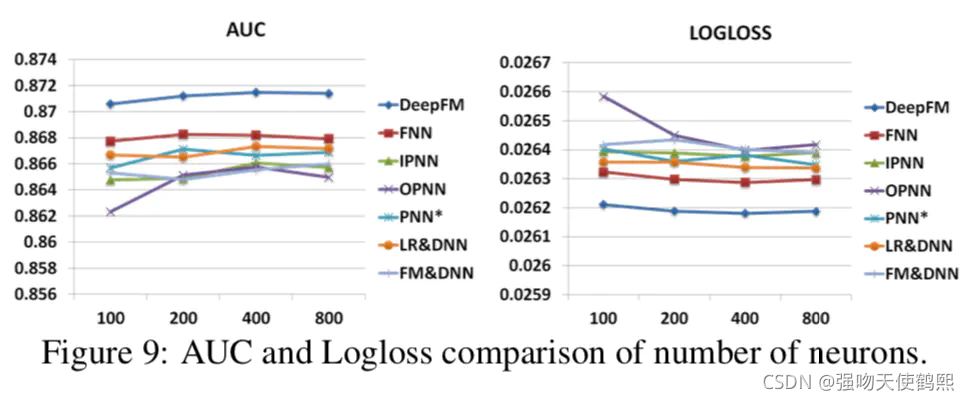
3,每层神经元个数
建议采用200~400个神经元能够给模型更好效果。
4,隐含层数量
增加隐含层的数量能够一定程度提升模型效果,但是要注意过拟合的情况。建议3~5个隐藏层为妙。
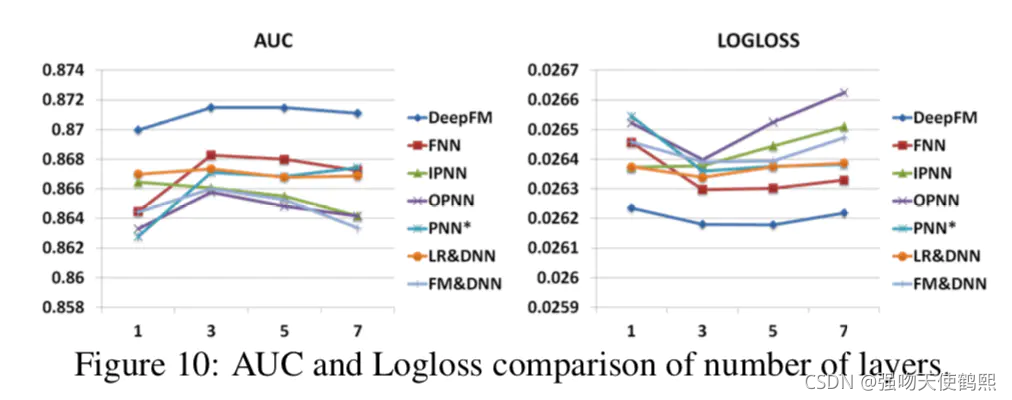
四:DeepFM与其他算法的比较(面试重点)
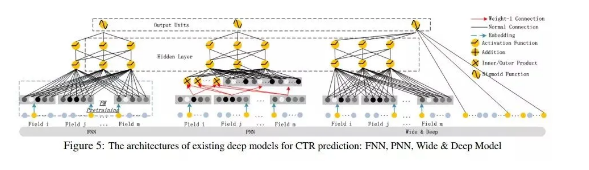
FNN:如图5(左)所示,FNN是FM初始化的前馈神经网络。FM预训练策略存在两个局限性:
1)嵌入参数可能会受到FM的影响;
2)预训练阶段的引入会降低效果。此外,FNN仅捕获高阶特征交互。相比之下,DeepFM不需要预训练就可以学习到高阶和低阶特征交互。
PNN:如图5(中)所示,为了捕捉到高阶特征,PNN在嵌入层与第一层隐含层之间引入了product layer。而根据不同的乘积方式,PNN有三种变种:IPNN,OPNN,PNN*,分别对应内积,外积,内积与外积。在具体使用中,因为外积的近似计算损失了大量的信息,使得外积的结果不如内积可靠。然而尽管如此,考虑到product layer的输出与第一层隐含层的连接为全连接,内积计算的计算复杂度也比较高。不同于PNN,DeepFM的procdut layer只和最终的输出连接,也就是一个神经元。因此与FNN相似,不同类型的PNN都忽略了低阶特征的重要性。
Wide&Deep:如图5(右)所示, Wide&Deep是google提出的可以同时提取低阶和高阶组合特征的模型,但其wide部分的输入需要进行人工特征工程。相应地,DeepFM可以直接处理原始输入特征而不需要人工特征工程。
总结:在DeepFM中,FM部分与DNN部分的feature embedding是共享的。而这种共享的策略又进一步通过反向传播的方式影响了低阶与高阶的特征组合,从而构建出更具有表征能力的特征。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









