




 Redis是一个高性能的内存数据库,常用于缓存、消息代理等场景。本文介绍了Redis的安装过程、基本数据类型如String、List、Hash、Set和SortedSet的使用,以及NIO(非阻塞I/O)的工作原理,强调了NIO如何通过多路复用减少用户态和内核态的切换以提高效率。
Redis是一个高性能的内存数据库,常用于缓存、消息代理等场景。本文介绍了Redis的安装过程、基本数据类型如String、List、Hash、Set和SortedSet的使用,以及NIO(非阻塞I/O)的工作原理,强调了NIO如何通过多路复用减少用户态和内核态的切换以提高效率。
Redis 介绍及 NIO 原理介绍
磁盘的寻址速度是 ms 级的,内存的寻址速度是 ns 级的,内存寻址速度比磁盘快了 10w 倍。
成本问题:磁盘有磁道和扇区,一个扇区 512Byte,为了降低索引成本;4k 对齐,一般磁盘的默认格式化为 4k,操作系统无论你读多少,最少都是 4k;随着文件变大,访问速度变慢,硬盘 I/O 成为瓶颈;
数据库 4k 每页,索引 4k 每页
关系型数据库建表:必须给出 schema【类型:字节宽度】,存的时候更倾向于行级存储;内存里面准备了一个 b+ 树,b+ 树的叶子就是 4k 索引
读取数据 --> b+ 树叶子 --> 磁盘
单机部署
官网地址:https://redis.io/ 中文网地址:http://www.redis.cn/
下载地址:https://download.redis.io/releases/redis-6.2.6.tar.gz
yum install weget
cd /opt
mkdir soft
wget https://download.redis.io/releases/redis-6.2.6.tar.gz
tar xf redis-6.2.6.tar.gz
cd redis-src
make
...yum install gcc
... make distclean
make
make install PREFIX = /opt/middleware/redis6
vi /etc/profile
...export REDIS_HOME=/opt/middleware/redis6
...export PATH=$PATH:$REDIS_HOME/bin
source /etc/porfie
cd utils
./install_service.sh 【安装服务实例】
service redis_6379 start/stop/stauts 【服务实例 启动/关闭/运行状态 命令】
cd /etc/init.d/ 【查询实例脚本】
$ find . -type f -executable
./redis-benchmark //用于进行redis性能测试的工具
./redis-check-dump //用于修复出问题的dump.rdb文件
./redis-cli //redis的客户端
./redis-server //redis的服务端
./redis-check-aof //用于修复出问题的AOF文件
./redis-sentinel //用于集群管理
//这样来启动redis客户端了
$ ./redis-cli
//用set指令来设置key、value
127.0.0.1:6379> set name "roc"
OK
//来获取name的值
127.0.0.1:6379> get name
"roc"
//通过客户端来关闭redis服务端
127.0.0.1:6379> shutdown
127.0.0.1:6379>
NIO 原理介绍
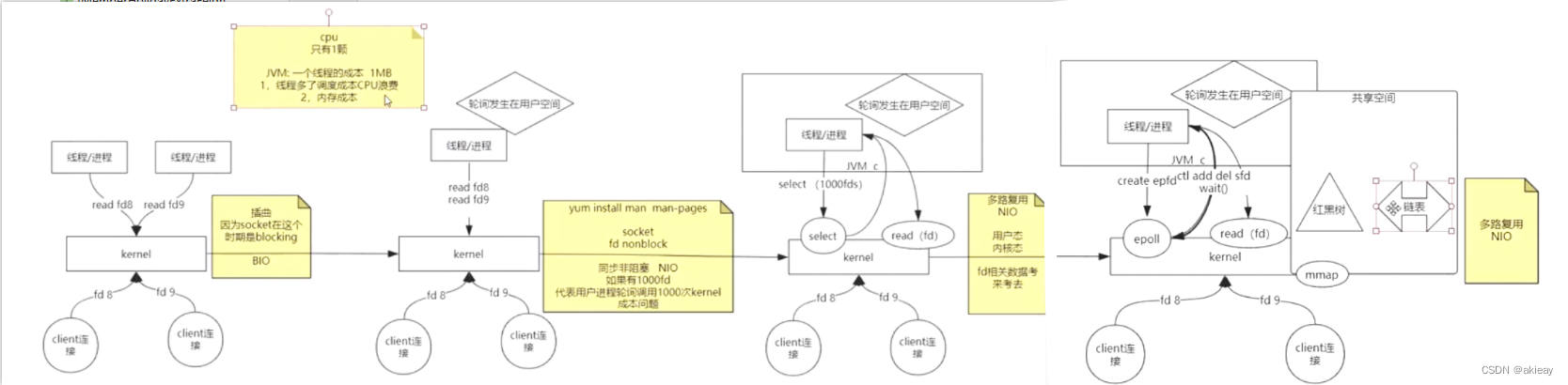
NIO:每次请求启动一个线程来处理,当多个请求并发访问时,需要启动多个线程。socket 在这个时期是blocking 的。
NIO:内核中的socket 可以是 nonblock 的,一个线程死循环遍历文件描述符;轮询发生在用户空间,同步非阻塞;问题:若有1000fd代表用户需要轮询调用1000次kernel【成本问题,内核态->用户态切换】
NIO:轮询发生在用户空间,内核一次性 select 1000fd,返回准备好了的 fd,减少【用户态->内核态】的切换。多路复用
NIO:为避免fd数据在内核和用户间拷来拷去,引入共享空间【mmap】,用户态和内核态共享这个空间;用户空间只需要将1000fd写入共享空间的红黑树,内核拿到fd,判断是否准备好数据,准备好则将其放到链表中,用户则只需要读取链表准备好的数据。
Redis 介绍
Redis 是一个开源(BSD 许可)的内存数据结构存储系统,用作数据库、缓存和消息代理。Redis 提供数据结构,例如字符串、哈希、列表、集合、具有范围查询的排序集合、位图、超日志、地理空间索引和流。Redis 具有内置复制、Lua 脚本、LRU 驱逐、事务和不同级别的磁盘持久性,并通过 Redis Sentinel 和 Redis Cluster 自动分区提供高可用性。
与传统关系型数据库不同的是 Redis 的数据是存在内存中的,所以读写速度非常快,因此 redis 被广泛应用于缓存方向,每秒可以处理超过 10万次读写操作,是已知性能最快的 Key-Value DB。另外,Redis 也经常用来做分布式锁。除此之外,Redis 支持事务 、持久化、LUA脚本、LRU驱动事件、多种集群方案。
Redis的优点和缺点
优点:
- 读写性能优异, Redis读取速度高达110000次/s,写的速度也达到了81000次/s。
- 数据结构丰富,有五种数据类型的value,分别是 String、Hash、List、Set、ZSet。
- 支持数据持久化,有AOP和RDB两种持久化方式。
- 支持事务,Redis是单进程单线程的,其所有操作都是原子性的,同时Redis还支持对几个命令合并后的原子性操作;但是与传统数据库事务不同的是,其不支持回滚操作。
- 支持主从复制,主机会自动将数据同步到从机,可以支持读写分离。
- 可以通过 Redis Sentinel 和 Redis Cluster 自动分区提供高可用。
缺点:
-
Redis是内存数据库,数据库容量受物理内存限制,不能用作海量数据的高性能读写,虽然redis本身有key过期策略,但是还是需要提前预估和节约内存。如果内存增长过快,需要定期删除数据。
-
如果进行完整重同步,由于需要生成rdb文件,并进行传输,会占用主机的CPU,并会消耗现网的带宽。不过redis2.8版本,已经有部分重同步的功能,但是还是有可能有完整重同步的。比如,新上线的备机。
-
修改配置文件,进行重启,将硬盘中的数据加载进内存,时间比较久。在这个过程中,redis不能
提供服务。
Redis为什么这么快
-
完全基于内存,绝大部分请求是纯粹的内存操作,非常快速。数据存在内存中,类似于 HashMap,HashMap 的优势就是查找和操作的时间复杂度都是O(1)
-
数据结构简单,对数据操作也简单,Redis 中的数据结构是专门进行设计的
-
采用单线程,避免了不必要的上下文切换和竞争条件,也不存在多进程或者多线程导致的切换而消耗 CPU,不用去考虑各种锁的问题,不存在加锁释放锁操作,没有因为可能出现死锁而导致的性能消耗
-
使用多路 I/O 复用模型,非阻塞 IO
-
使用底层模型不同,它们之间底层实现方式以及与客户端之间通信的应用协议不一样,Redis 直接自己构建了 VM 机制 ,因为一般的系统调用系统函数的话,会浪费一定的时间去移动和请求
基本数据类型
redis提供了五种基本数据类型:字符串(strings)、散列(hashes)、列表(lists)、集合(sets)、有序集合(sorted sets)。
| 数据类型 | 简介 | 应用场景 |
|---|---|---|
| String | 字符串,数值,bitmap,二进制安全 | 秒杀、活跃用户统计、点赞数、评论数 |
| Hash | 键值对的散列表 | 详情页 |
| List | 链表(双向链表) | 消息队列 |
| Set | 哈希表实现,元素不重复 | 共同好友,抽奖 |
| Sorted Set | 有序集合,跳跃表 | 排行榜,带权重的消息队列 |
正反向索引:正向索引 0-(len-1) ,反向索引 -1~(-len)
二进制安全:redis存储的是字节
时间单位:
EXseconds – 设置指定的过期时间,以秒为单位。
PX毫秒——设置指定的过期时间,以毫秒为单位。
EXATtimestamp-seconds – 设置密钥过期的指定 Unix 时间,以秒为单位。
PXATtimestamp-milliseconds – 设置密钥过期的指定 Unix 时间,以毫秒为单位。PERSIST – 删除与密钥关联的生存时间。
Redis 的 String 类型 和 bitmap
官网命令:https://redis.io/commands#string
String 不仅可以面向
字符串操作,还可以面向数值操作和bitmap操作。
redis-cli -p 6379
select 0
set k1 hello
help @string
keys *
FLUSHDB
一、面向String操作
| 命令 | 描述 |
|---|---|
APPEND key value | 追加一个value到key上 |
GET key | 返回key的value |
GETDEL key | 获取key的value,并删除 |
GETEX key[EX seconds …] | 获取key的值,并可选择设置其过期时间 |
GETRANGE key start end | 获取存储在key上的value的一个子字符串 |
GETSET key | 设置一个key的value值,并获取设置前的值 |
LCS key1 key2 | 获取多个key的value中都同时存在的字符并返回 |
MGET key [key…] | 批量获取key 对应的value值 |
MSET key [key value…] | 批量设置 key-value 键值对 |
MSETNX key value [key value…] | 批量设置 key-value 键值对【若key不存在】 |
PSETEX key milliseconds value | 与SETEX完全相同,唯一的区别是过期时间以毫秒单位 |
SET key value [EX seconds …] | 设置一个key的value值,并可选择设置其过期时间 |
SETEX key seconds value | 设置key-value并设置过期时间(单位:秒) |
SETNX key value | 当key不存在时,设置key的value值 |
SETRANGE key offset value | 覆盖指定key部分value,从指定的偏移量开始,覆盖value的整个长度 |
STRLEN key | 获取指定key的值的长度 |
SUBSTR key start end | 获取存储在key上的value的一个子字符串 |
set k1 ssss nx k1不存在则设置k1的值为ssss
set k2 ssss xx k2存在则更新k2的值为ssss
mset k1 ssss k2 dddd 设置k1的值为ssss、k2的值为dddd
mget k1 k2 获取k1、k2的值
append k1 work 在k1的值后面追加work
GETRANGE K1 0 5 获取k1 索引0-5的值
GETRANGE K1 0 -1 获取k1 索引0到-1的值【即所有】
SETRANGE K1 6 SSDDDDS 设置K1 从索引6开始后续的值
STRLEN K1 获取k1值的长度
GETSET K1 121 设置k1为121并且返回设置前的k1的值
MSETNX k1 123 k2 456 批量设置k的值
二、面向数值操作
| 命令 | 描述 |
|---|---|
INCR key | 执行原子加1操作 |
INCRBY key increment | 原子增加一个整数 |
INCRBYFLOAT key increment | 原子增加一个浮点数 |
DECR key | 整数原子减1 |
DECRBY key decrement | 原子减少指定的整数 |
TYPE K1 【描述的是value的类型】
OBJECT encoding k1
SET K1 99
TYPE K1
INCR K1
TYPE K1
DECR K1
INCRBY K1 11
DECRBY K1 12
INCRBYFLOAT K1 0.5
使用案例:秒杀,抢购,详情页,点赞数,评论数,关注数;规避并发下对数据库的事务操作,完全由redis内存操作代替
三、面向bitmap操作
| 命令 | 描述 |
|---|---|
BITCOUNT key [start end [BYTE|BIT]] | 统计字符串被设置为1的bit数 |
BITFIELD key [Get encoding offset]… | 对字符串执行任意位域整数运算 |
BITFIELD_RD key GET encoding offset | 对字符串执行任意位域整数运算。BITFIELD 的只读变体 |
BITPOS key bit [start…] | 返回字符串里面第一个被设置为1或者0的bit位 |
GETBIT key offset | 返回存储在 key 的字符串值中偏移处的位值 |
SETBIT key offset value | 设置或清除存储在 key 的字符串值的偏移量位 |
BITOP operation destkey key [key…] | 在字符串之间执行按位运算 |
SETBIT k1 1 1 设置k1的索引为1的bit的二进制位为1
SETBIT K1 7 1
GETBIT k1 7
BITPOS k1 1 0 0 查找k1的值中索引0~0之间的字节中二进制位为1的第一个二进制位的索引【字符串中的字符索引】
BITCOUNT K1 0 0 字符串索引【0-0】之间的字符中二进制位1出现的次数
# 位运算
FLUSHDB
SET k1 A
SET K2 B
BITOP AND andkey k1 k2
get andkey => @
BITOP OR orkey k1 k2
get orkey => C
使用案例:
一、统计用户的登录天数,且查询日期随机
用户ID做key,一年中的第几天为 二进制位索引 登录时,其位置的值置为1
SETBIT ak 1 1 SETBIT ak 365 1 BITCOUNT ak 0 -1 ===> 2 # 一年登录了两次 STRLEN ak # 查看一年占用的字符总数为【46】,占用空间小二、某商城618活动:送礼物,需要备货多少礼物;存在2e用户;活跃用户统计
# 时间作为key 用户ID映射到二进制位 # 如下,用户1 2022-01-01 登录,用户6 2022-01-02 登录 SETBIT 20220101 1 1 SETBIT 20220102 6 1 BITOP OR activeKey 20220101 20220102 BITCOUNT activeKey 0 -1
Redis 的 List 类型
官网命令:https://redis.io/commands#list
同向命令:栈,反向命令:队列,数组,阻塞、单播队列FIFO
| 命令 | 描述 |
|---|---|
LPUSH RPUSH | 从队列左边/右边入队一个或多个元素 |
LPUSHX RPUSHX | 当队列存在时,从队列左边/右边入队一个或多个元素 |
LPOP RPOP | 从队列左边/右边出队一个元素 |
LINDEX | 通过索引获取一个元素【索引从0开始】 |
LINSERT | 在列表中的一个元素【值】之前/之后插入一个元素 |
LLEN | 获取列表的长度 |
LMOVE | 从列表中弹出一个元素,将其推送到另一个列表并返回 |
LMPOP | 从提供的key列表中的第一个非空列表中弹出指定个数的元素,返回元素个数受列表限制,最多为列表所有元素。 |
LPOS | 返回元素在列表中出现的索引位置【可以存在多个】 |
LRANGE | 从列表获取指定索引范围内的元素 |
LREM | 移除列表中指定个数的元素【正数:左到右,负数:右到左,0:所有】 |
LSET | 设置队列里面一个元素的值 |
RPOPLPUSH | 原子删除列表的最后一个元素(尾部),并将该元素推到目标列表的第一个元素(头部)处 |
LTRIM | 修剪现有列表,使其仅包含指定范围内的元素 |
BLPOP BRPOP | 从第一个非空列表的左边/右边弹出一个元素,若所有列表都不存在元素,则阻塞等待直到有元素可以弹出【可以设置超时时间】 |
BLMOVE | 从列表中弹出一个元素,将其推送到另一个列表并返回,若不存在元素则阻塞等待【可以设置超时时间】 |
BLMPOP | 从提供的key列表中的第一个非空列表中弹出指定个数的元素,返回元素个数受列表限制,最多为列表所有元素;若不存在元素,则阻塞等待【可以设置超时时间】 |
BRPOPLPUSH | 该命令与RPOPLPUSH行为一样,只是当列表不存在元素时,会阻塞等待【可以设置超时时间】 |
简单使用
LPUSH K1 a b c d e f => f e d c b a
RPUSH K2 a b c d e f => a b c d e f
LPOP K1 => f
RPOP K2 => f
RPOP K1 => a
LPOP K2 => a
同向命令: 栈,反向命令:队列
LRANGE k1 0 -1 => e d c b
LRANGE K2 0 -1 => b c d e
LINDEX K1 2 => c
LSET K1 2 3333 => e d 3333 b
LPUSH k1 2 2 2
RPUSH k1 2 2 => 2 2 2 e d 3333 b 2 2
LREM K1 2 2 => 2:正数,移除左边开始两个2 => 2 e d 3333 b 2 2
LPUSH k3 1 2 3 4 5 6 => 6 5 4 3 2 1
LINSERT K3 after 6 a => 从左边开始在第一个元素6后面插入一个a => 6 a 5 4 3 2 1
LINSERT K3 before 3 a => 从左边开始第一个元素3前面插入一个a => 6 a 5 4 a 3 2 1
LLEN K3 => 8
LTRIM K3 2 5 ==> 移除K3 索引2~5[不包含]两端的元素 =》 5 4 a 3
Redis 的 Hash 类型
官网命令:https://redis.io/commands#hash
| 命令 | 描述 |
|---|---|
HSET | 设置hash里面一个字段的值 |
HMSET | 设置hash多个字段的值 |
HGET | 获取hash中指定字段的值 |
HMGET | 获取hash中多个字段的值 |
HKEYS | 获取hash的所有字段 |
HVALS | 获取hash的所有值 |
HGETALL | 获取hash中全部的字段的键值对 |
HINCRBY | 将hash中指定字段的值增加给定的数值 |
HINCRBYFLOAT | 将hsah中指定字段的值增加给定的浮点数 |
HDEL | 删除一个或多个hash的字段 |
HEXISTS | 判断字段是否存在于hash中 |
HLEN | 获取hash中所有字段的数量 |
HRANDFIELD | 随机从hash中获取指定个数的字段【最多为所有的字段】 |
HSCAN | 迭代hash里面的元素 |
HSETNX | 当字段不存在时,设置这个字段的值 |
HSTRLEN | 获取hash里面指定字段的长度 |
简单使用
HSET akieay name akieay
HMSET akieay age 22 sex 2 address 0151
HGET akieay name => akieay
HMGET akieay name age sex => akieay 22 2
HKEYS akieay => name age sex address
HVALS akieay => akieay 22 2 0151
HGETALL akieay => name:akieay age:22 sex:2 address:0151
HINCRBY akieay age 3 => age:25
HINCRBYFLOAT akieay age 0.5 => age:25.5
HDEL akieay address
HGETALL akieay => name:akieay age:22 sex:2
HEXISTS akieay name => 1
HEXISTS akieay address => 0
HLEN akieay => 3
HRANDFIELD akieay 2 => name sex
HSETNX akieay address 1065
HGETALL akieay => name:akieay age:22 sex:2 address:1065
HSTRLEN akieay name => 6
HSCAN akieay 2
场景:点赞,收藏,详情页
Redis 的 Set 类型
无序、去重
官网命令:https://redis.io/commands#set
| 命令 | 描述 |
|---|---|
SADD | 添加一个多多个元素到Set集合里 |
SREM | 从集合里面删除一个或多个元素 |
SPOP | 从集合中移除并返回一个或多个随机成员] |
SCARD | 获取集合里面的元素数量 |
SISMEMBER | 确定一个给定的成员是否是集合的成员,1:是,0:不是 |
SMISMEMBER | 返回每个成员是否为存储到key中的集合成员,1:是,0:不是 |
SMEMBERS | 返回集合中的所有成员 |
SRANDMEMBER | 从集合中随机获取指定个数的元素(默认1);当数值为正数时,不重复,不一定满足个数;当数值为负数时,可重复,一定满足个数 |
SSCAN | 迭代集合里面的元素 |
SINTER SINTERSTORE | 获取多个集合的交集,【SINTERSTORE会将结果存储到指定的结果集中】 |
SUNION SUNIONSTORE | 获取多个集合的并集,【SUNIONSTORE会将结果存储到指定的结果集中】 |
SDIFF SDIFFSTORE | 获取多个集合的差集,【SDIFFSTORE会将结果存储到指定的结果集中】 |
SINTERCARD | 这个命令类似于SINTER,但是它不返回结果集,而是返回结果的基数 |
SMOVE | 移动集合里面的一个元素到另一个集合中 |
简单使用
SADD k1 1 2 3 4 5 6
SMEMBERS k1 => 1 2 3 4 5 6
SREM k1 4 5 6
SMEMBERS k1 => 1 2 3
SPOP k1 2
SMEMBERS K1 => 2
SCARD k1 => 1
SISMEMBER k1 2 => 1
SISMEMBER k1 1 => 0
SMISMEMBER k1 1 2 3 => 0 1 0
SADD k1 1 2 3
# 正数,不重复,不一定满足个数;负数,可重复,一定满足个数;0,不返回
SRANDMEMBER k1 4 => 1 2 3
SRANDMEMBER k1 -4 => 2 1 3 3
SADD k2 1 2 3 4 5
SADD k3 4 5 6 7 8
SINTER k2 k3 => 交集:4 5
SINTERSTORE inkey K2 K3
SMEMBERS inkey => 4 5
SUNION K2 K3 => 并集:1 2 3 4 5 6 7 8
SDIFF K2 K3 => 取k2相对于k3的差集:1 2 3
SDIFF K3 K2 => 取k3相对于k2的差集:6 7 8
SMOVE k2 k3 1
SMEMBERS k2 => 2 3 4 5
SMEMBERS k2 => 1 4 5 6 7 8
应用场景:抽奖
用户 <10 或 用户 > 10
很多粉丝,三个礼物,每个人只有一件:k1存人,SRANDMEMBER K1 3
很多粉丝,三个礼物,每个人可以多件:k1存人,SRANDMEMBER K1 -3
很多礼物,20个礼物,3个人,可以多件:k1存礼物,SRANDMEMBER K1 3公司年会:一次抽一件礼物
SPOP K1 弹出一个
Redis 的 Sorted Set 类型
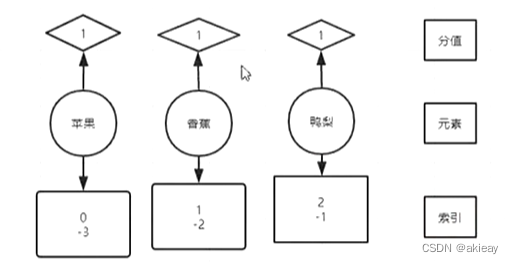
排序:分值,名称字典序
官网命令:https://redis.io/commands#sorted-set
| 命令 | 描述 |
|---|---|
ZADD | 添加一个或多个成员到集合【重复的成员会更新分数】 |
ZRANGE | 返回集合中指定范围内的成员 |
ZREVRANGE | 从最高到最低排序,返回集合中指定范围内元素 |
ZRANK | 返回集合成员在集合中的排名 |
ZREVRANK | 除了颠倒了顺序外,其行为与 ZRANK 基本一致 |
ZSCORE | 返回集合成员分数 |
ZMSCORE | 返回集合中指定成员的分数 |
ZINCRBY | 为指定成员增加指定的分数 |
ZCARD | 获取集合中的成员数量 |
ZCOUNT | 返回分数范围内的成员数量 |
ZREM | 移除集合中的指定成员 |
ZSCAN | 迭代集合里面的元素 |
ZREMRANGEBYSCORE | 删除集合中分数介于min和max之间的元素 |
ZREMRANGEBYRANK | 根据rank移除处于start到stop之间的排名的元素,正数表示正序排名,0表示分数最低的,负数表示倒叙排名 |
ZPOPMIN | 移除并返回集合中已排序的最低分的成员 |
ZPOPMAX | 移除并返回集合中已排序的最高分的成员 |
ZRANDMEMBER | 从集合中随机获取指定个数的元素(默认1);当数值为正数时,不重复,不一定满足个数;当数值为负数时,可重复,一定满足个数 |
ZRANGESTORE | 返回集合中指定排名范围内的成员,并将结果存储到指定key中 |
ZRANGEBYSCORE | 返回已排序集合中分数介于min和max之间的元素,并且按分数从低到高排序【包含min和max】 |
ZREVRANGEBYSCORE | 除了颠倒了顺序外,其行为与 ZRANGEBYSCORE 基本一致 |
ZLEXCOUNT | 当以相同的分数插入已排序集合中的所有元素时,为了强制按字典顺序排序,该命令返回已排序集合中的元素数量,其值介于min和max之间 |
ZRANGEBYLEX | 当以相同的分数插入已排序集合中的所有元素时,为了强制按字典顺序排序,该命令返回已排序集合中的元素,其值介于min和max之间 |
ZREVRANGEBYLEX | 除了颠倒了顺序外,其行为与 ZRANGEBYLEX 基本一致 |
ZINTER | 取多个集合的交集,并将结果返回给客户端 |
ZINTERCARD | 取多个集合的交集,并将结果集的基数返回给客户端 |
ZINTERSTORE | 取多个集合的交集,并将结果存储在指定的key中 |
ZUNION | 取多个集合的并集,并将结果返回给客户端 |
ZUNIONSTORE | 取多个集合的并集,并将结果存储在指定的key中 |
ZDIFF | 取多个集合的差集,并将结果返回给客户端 |
ZDIFFSTORE | 取多个集合的差集,并将结果存储在指定的key中 |
ZMPOP | 从提供的集合中的第一个非空集合中弹出一个或多个成员-分数对元素。 |
ZREMRANGEBYLEX | 当以相同的分数插入已排序集合中的所有元素时,为了强制按字典顺序排序,该命令删除集合中min到max位置的所有元素 |
BZMPOP | ZMPOP 的阻塞体,行为与 ZMPOP 基本一致,没有元素时会阻塞等待 |
BZPOPMAX | ZPOPMAX 的阻塞体,行为与 ZPOPMAX 基本一致,没有元素时会阻塞等待 |
BZPOPMIN | ZPOPMIN 的阻塞体,行为与 ZPOPMIN 基本一致,没有元素时会阻塞等待 |
简单使用
ZADD k1 8 apple 2 banana 3 organge => 添加元素 前面为分数,后面为元素值
ZRANGE k1 0 -1 => 元素按分数从小到大排序:banana organge apple
ZREVRANGE k1 0 -1 => 元素按分数从大到小排序:apple organge banana
ZRANK k1 banana => 获取元素 "banana"【从小到大】的排名:0 【排名索引从0开始】
ZREVRANK k1 banana => 获取元素 "banana"【从大到小】的排名:2
ZSCORE k1 apple => 获取元素 "apple" 的分值:8
ZMSCORE k1 apple banana organge => 获取多个元素的分值:8 2 3
ZCARD k1 => 获取集合中成员的数量:3
ZCOUNT k1 0 5 => 获取集合中分数[0-5]之间的元素数量:2
ZREM k1 apple => 删除元素 "apple"
ZRANGE k1 0 -1 => banana organge
ZINCRBY k1 2 banana => 元素 "banana" 分值增加2
ZSCORE k1 banana => 4
ZADD k1 8 apple 2 banana 3 organge
ZREMRANGEBYSCORE k1 0 5 => 删除分数在[0-5]之间的元素
ZRANGE k1 0 -1 => apple
ZADD k1 8 apple 2 banana 3 organge
ZREMRANGEBYRANK k1 2 3 => 删除排名在[2-3]之间的元素,排名从0开始
ZRANGE k1 0 -1 => banana organge
ZADD k1 8 apple 2 banana 3 organge
ZPOPMIN k1 2 => 根据排名从小到大弹出2个元素
ZRANGE k1 0 -1 => apple
ZADD k1 8 apple 2 banana 3 organge
ZPOPMAX k1 2 => 根据排名从大到小弹出2个元素
ZRANGE k1 0 -1 => banana
ZADD k1 8 apple 2 banana 3 organge
# 从集合中随机获取指定个数的元素(默认1);当数值为正数时,不重复,不一定满足个数;当数值为负数时,可重复,一定满足个数
ZRANDMEMBER k1 4 => apple organge banana
ZRANDMEMBER k1 -4 => banana apple organge banana
# 返回集合中指定排名【从小到大】范围内的成员,并将结果存储到指定key中【排名从0开始】
ZRANGESTORE newkey k1 0 1
ZRANGE newkey 0 -1 => banana organge
ZRANGEBYSCORE k1 0 5 => 获取分数为[0-5]之间的元素并从小到大排列:banana organge
ZREVRANGEBYSCORE k1 5 0 => 获取分数为[5-0]之间的元素并从大到小排列:organge banana
ZADD k2 0 a 0 b 0 c 0 d 0 e
ZLEXCOUNT k2 - + => 5 【可以使用 - 和 + 表示得分最小值和最大值】
ZLEXCOUNT k2 [b [f => 4
ZRANGEBYLEX - + => a b c d e
ZRANGEBYLEX k2 [b [e => b c d e
ZREVRANGEBYLEX k2 [e [b => e d c b
ZREMRANGEBYLEX k2 [b [e => a
# 集合操作 交、并、差集
FLUSHDB
ZADD k1 80 tom 70 jk 60 kk 30 cc
ZADD k2 60 tom 94 jk 40 kk 20 tt
# 交集
ZINTER 2 k1 k2 withscores => kk:100 tom:140 jk:164
ZINTERSTORE inkey 2 k1 k2 => 取k1与k2的交集,并将结果存入inkey
ZRANGE inkey 0 -1 withscores => kk:100 tom:140 jk:164
# 并集
ZUNION 2 k1 k2 withscores => tt:20 cc:30 kk:100 tom:140 jk:164
# 取k1与k2的并集,并根据权重合并分数,然后添加到unkey中,分数计算如下:
# k1中tt分数不存在,k2中tt分数为20,而k1与k2权重比为1:0.5,所以合并后tt分数为10
# 同理,k1 jk:70,k2 jk:94,k1:k2 = 1:0.5,分数合并k1-jk:70,k2-jk:47,合并后jk:117
ZUNIONSTORE unkey 2 k1 k2 weights 1 0.5
ZRANGE unkey 0 -1 withscores => tt:10 cc:30 kk:80 tom:110 jk:117
# 取k1与k2的并集,并根据权重合并分数【合并方式为取最大值】,然后添加到unkey中,分数计算如下:
# k1 tt不存在,k2 tt:20,k1:k2 = 1:0.5,分数合并k1-tt不存在,k2-tt:10,合并取最大值tt:10
# k1 jk:70,k2 jk:94,k1:k2 = 1:0.5,分数合并k1-jk:70,k2-jk:47,合并取最大值jk:70
ZUNIONSTORE unk2 2 k1 k2 weights 1 0.5 aggregate MAX
ZRANGE unk2 0 -1 withscores => tt:10 cc:30 kk:60 jk:70 tom:80
# 差集
ZDIFF 2 k1 k2 withscores => 取k1与k2的差集,以k1数据为主:cc:30
ZDIFF 2 k2 k1 withscores => 取k2与k1的差集,以k2为主:tt:20
应用:
ZRANGE k1 0 -1 withsocres => 会根据分值的改变而改变元素的位置 歌曲热度排行
跳跃表
普通链表

跳跃表
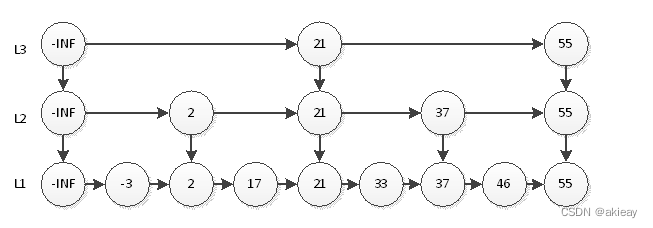
跳跃列表是一种高效的动态数据结构,它是基于链表实现的。它允许快速查询一个有序连续元素的数据链表,而其快速查询是通过维护一个多层次的链表来实现的,且每一层链表中的元素是前一层链表元素的子集。
一开始时,算法在最稀疏的层次进行搜索,直至需要查找的元素在该层两个相邻的元素中间。这时,算法将跳转到下一个层次,重复刚才的搜索,直到找到需要查找的元素为止。
可以看到,这里一共有3层,最上面就是最高层 L3,最下面的层就是最底层 L1,然后每一列中的链表节点中的值都是相同的,用指针来连接着。跳跃表的层数跟结构中最高节点的高度相同。理想情况下,跳跃表结构中第一层中存在所有的节点,第二层只有一半的节点,而且是均匀间隔,第三层则存在1/4的节点,并且是均匀间隔的,以此类推,这样理想的层数就是 logN。
跳跃表的特性:
- 跳表是基于链表建立多级索引的动态数据结构,每一层都是一个有序的链表;
- 每一层都是一个有序的链表,排列顺序为由高层到底层,都至少包含两个链表节点,分别是前面的head节点和后面的nil节点;
- 最底层的链表包含了所有的元素;
- 如果一个元素出现在某一层的链表中,那么在该层之下的链表也全都会出现(上一层的元素是当前层的元素的子集);
- 链表中的每个节点都包含两个指针,一个指向同一层的下一个链表节点,另一个指向下一层的同一个链表节点;
- 跳表的查询时间复杂度是 O*(log(*n)),而单链表的查询时间复杂度是 O(n)
- 跳表需要额外的内存空间存储索引,实现空间换时间
- 动态插入,删除数据时,跳表需要维护索引大小平衡性,避免退化为单链表

















 5511
5511

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









