




 本文深入探讨数据库架构设计,包括关系型数据库的组成部分、索引优化策略(如B树、B+树、hash索引),以及锁机制和事务的管理。详细讲解了密集索引与稀疏索引的区别,慢查询的定位与优化方法,联合索引的最左匹配原则,以及MyISAM与InnoDB锁的不同。此外,还介绍了数据库事务的四大特性(ACID)和事务隔离机制。
本文深入探讨数据库架构设计,包括关系型数据库的组成部分、索引优化策略(如B树、B+树、hash索引),以及锁机制和事务的管理。详细讲解了密集索引与稀疏索引的区别,慢查询的定位与优化方法,联合索引的最左匹配原则,以及MyISAM与InnoDB锁的不同。此外,还介绍了数据库事务的四大特性(ACID)和事务隔离机制。
1. 数据库架构
如何设计一个关系型数据库:
将其划分为两个部分——一个是存储部分,把数据持久化在存储设备中。另一个是程序实例模块,又细分为存储管理(程序逻辑关系转换为存储关系)、缓存机制(优化执行效率)、SQL解析、日志管理(记录操作)、权限划分(多用户管理)、容灾机制、索引管理(优化数据查询效率)、锁管理(支持并发模块)。
2. 优化索引
(一)使用平衡二叉树或者红黑树,在每次节点的访问就会进行一次IO,如果数据很多,就会多次IO。速度比全表扫码慢很多。
(二)B树(平衡多路查找树),每个节点有M个孩子,就是M阶B树,每个存储块中有关键字和指向孩纸的指针。
特征(孩子):
根节点至少包括两个孩子
树中每个节点最多有m个孩子(m>=2,m取决于容量和数据库的配置)
除了根节点和叶节点外,其他节点至少有m/2(向上取整)个孩子,至少具备两个孩子
所有叶子节点都位于同一层
特征(关键字)
关键字是升序排列的
关键字个数永远比孩子数少一个
最左边的关键字大于最左边孩纸节点里面的值,最右边的关键字小于最右边孩子节点里面的值,而孩子i则在关键字(i-1)与关键字i之间(注:开区间的)。
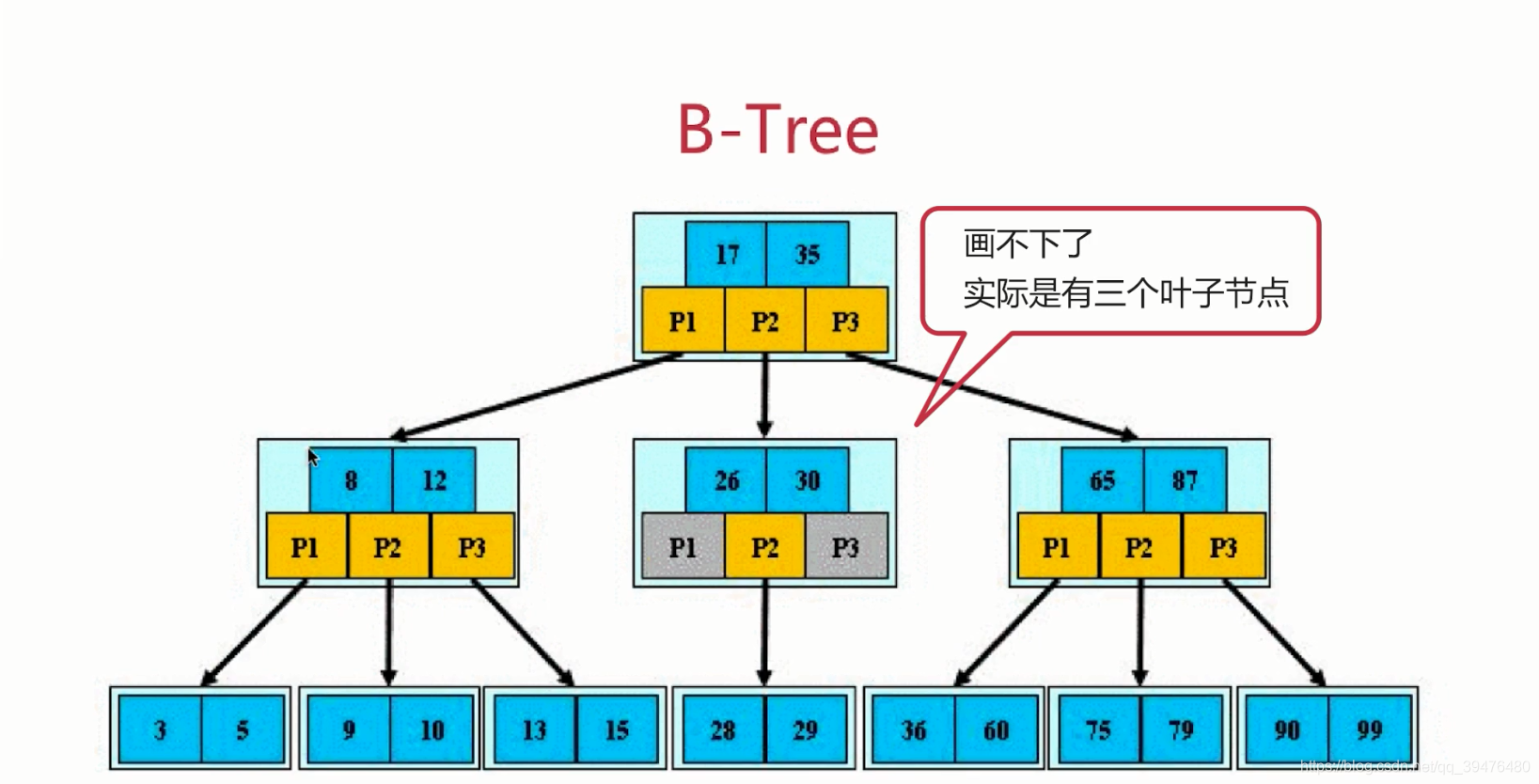
作为索引比二叉树好。因为深度更低、不会出现线性。
(三)B+树
孩子特征与B树相同
特征(关键字)
孩子与关键字个数相同
非叶子节点的子树指针P[i], 指向关键字的值[k[i],k[i+1])
非叶子节点仅用来索引,数据全保存在叶子节点
所有叶子节点均有一个链指针指向下一个叶子节点(方便做范围统计,可以横向的跨指数去统计)
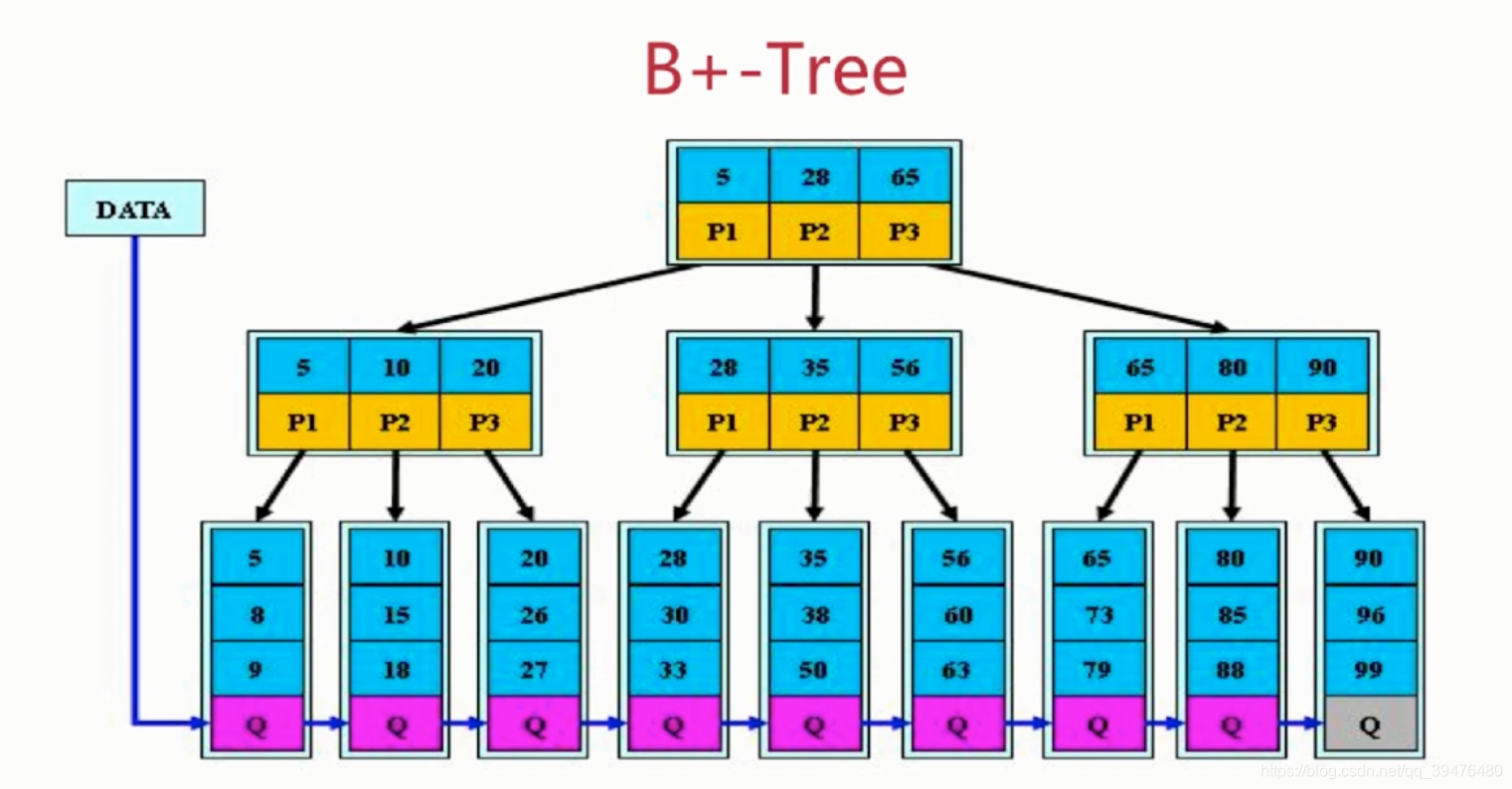
B+树更适合做索引:
1、B+树的磁盘读写代价更低。内部不存放数据,只存放索引信息,内部节点相对B树更小。
2、B+树的查询效率更稳定。内部节点并不是指向文件内的节点,所有关键字查询的长度相同,以至于每一个数据查询的效率差不多。
3、B+树更利于队数据库扫描。只需要遍历叶子节点就可以解决对全部关键字信息扫描。
(四)hash索引

优点:查询效率比B+树高
缺点:
仅仅能满足“=”,“IN”。他比较的是hash计算之后的hash值,所以不能进行范围查询。因为不能保证在hash计算前后的值是一样的
无法被用来避免数据的排序。也是由于hash计算的原因
不能利用部分索引键查询。
不能避免表扫描。可能有相同的hash值,然后entries中是一个列表,还是要一个一个找
大量的hash值相等后,性能不一定比B+树高。
- 密集索引和稀疏索引的区别
密集索引文件中的每个搜索码值都对应一个索引值。也就是,把所有行记录都存储在B+树的叶子节点上
稀疏索引文件只为索引码的某些值建立索引项。叶子节点存储的是主键,检索数据的时候还需要多走一次密集索引。
MyISAM中,所有索引都是稀疏索引。
InnoDB中,必须有且仅有一个密集索引,若一个主键被定义了,他就是密集索引。
若没有主键,该表的第一个唯一非空索引就是密集索引
若都没有,InnoDB内部会生成一个隐藏主键作为密集索引
问题:
(一)为什么使用索引
索引能够避免全表扫描,提高效率。
(二)什么样的信息能被称为索引
主键,唯一件等。能让数据有一定区分性的字段。
(三)索引的数据结构
主流是B+树,有时会有hash结构(引擎为MyISAM和InnoDB不显示支持hash)和bitmap(mysql不支持bitmap)
(四)密集索引和稀疏索引的区别
上面解释了
(五)如何定位并优化慢查询MySQL
根据慢日志定位慢查询sql。慢日志是记录我们执行比较慢的sql。可以在my.ini里面设置
show variables like ‘%quer%’; 查看属性
show status like ‘%slow_queries%’; 查看本次慢sql的数量
set global show_query_log = on; 打开慢日志
set global long_query_time = 1; 设置多久时间算慢,需要重新连接数据库。
explain 用来对sql语句进行,放在select前面。里面type字段表示mysql找到需要数据行的方式(如果是index或者all,那么就是全表查询需要优化),extra(using filesort表示mysql使用外部索引排序,用不到表里面的索引;using temporary表示把查询结果放在一个临时表,常见于grounp by和order by)
优化方式:修改sql,尽量让sql走索引。或者加索引——alter table 表名 add index index_name(列名);
(六)联合索引的最左匹配原则的成因
联合索引:将两个索引看成一个索引,如where a = and b=,就可以走ab的联合索引。如果调单独a=时也会走联合索引,但是单独b=是不会走联合索引。
最左匹配原则:mysql会一直向右匹配直到遇到范围查询(‘>’,‘<’,between,like)就停止匹配。=和in可以乱序,优化器会优化成能识别的索引。
成因:mysql在生成联合索引时,会对第一个字段进行排序,在此基础上再排上后面的字段。这样第一个索引字段就是绝对有序的,后面的就是无序的了。
(七)索引越多越好吗
数据量小的表不需要索引,建立会增加额外的开销
数据变更需要维护索引,因此更多索引意味着更多的维护成本。
更多的索引也意味着需要更多的空间。
3. 锁
MyISAM与InnoDB锁之间的区别。
1、MyISAM默认用的是表级锁,不支持行级锁。InnoDB默认使用行级锁,也支持表级锁,在sql没有用索引时使用表级锁。所以InnoDB的开销更大。
开锁:lock tables 表名 read/write;(读锁是共享锁;写锁是排它锁)
关锁:unlock tables;
将读锁变为排它锁:在select语句最后加入 for update。
加共享锁:在需要的地方后面加 lock in share mode。
2、InnoDB必须有且仅有一个聚集索引,数据文件和索引是绑定再一起的,必须有有主键。但是辅助索引需要查两次,先查到主键再查到数据。MyISAM是非聚集索引,索引和文件是分离的,索引保存的是数据文件的指针,主键索引和辅助索引是分离的。
MyISAM适合的场景:
频繁执行全表count语句。InnoDB不保存表的具体行数,MyISAM用一个变量保存行数,使用时直接取值就好。
队数据的增删改的频率不高,频繁查询。因为增删改要进行锁表操作,影响效率。
没有事务。
InnoDB使用的场景:
频繁增删改查,因为只锁行。
可靠性要求也比较高,要求支持事务的系统。
4、数据库事务的四大特性(ACID)
(一)原子性(Atomic),事务包含的操作,要么全做要么全不做。
(二)一致性(Consistency),事务应确保数据库的状态从一个一致状态转到另一个一致状态。
(三)隔离性(Isolation),多个事务并发执行时,一个事务的执行不应该影响其他的事务。
(四)持久性(Durability),一个事务的提交,对数据库的修改应该永久保存在数据库中。
5、事务隔离机制
select @tx_isolation:查看数据库的事务隔离级别
set session transaction isolation level 隔离级别:设置事务隔离级别
start transaction:开启事务
脏读:是指一个事务读到另一个事务还未提交的数据(将事务隔离级别设置为read committed(Oracle默认的隔离级别)及以上级别,只能读到其他事务提交的数据。)
不可重复读:事务A多次重复读取数据,事务B中其中某时对数据进行更新和提交,导致事务A多次读取同一数据时结果不一致。(将事务隔离级别设置为repeatable read(MySQL默认的隔离级别))
幻读:事务A在进行读取操作时,事务B在事务A的影响区间内插入或删除了数据,此时事务A在执行当前读操作就会出现幻行。(将事务隔离级别设置为最高级别serializable就可以避免,InnoDB在repeatable read的级别下就可以避免)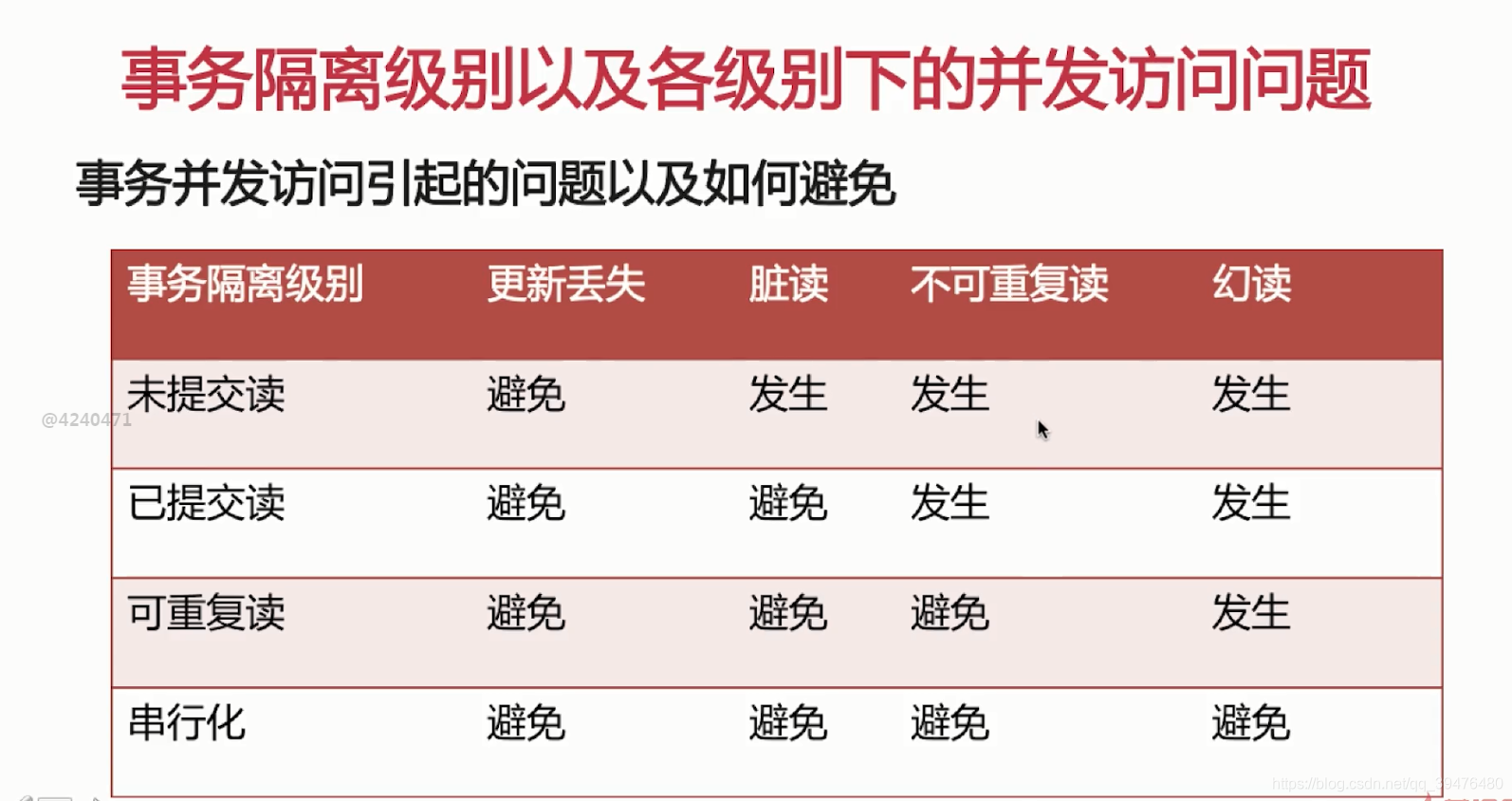
6、InnoDB可重复读的隔离级别下如何避免幻读
表象:快照读(非阻塞读)—伪MVCC(多版本并发控制,读不加锁,读写不冲突),并不是真正的多版本,所以是伪MVCC
当前读:加了锁的增删改查语句,他们读取的是记录的最新版本,对读取记录加锁。
快照读:不加锁的非阻塞读(InnoDB在RC、RR级别下使用:数据行里的DB_TRX_ID、DB_ROLLPTR、DB_ROW_ID;undo日志;read view实现)
内在:next-key(行锁+gap锁)
gap锁:gap是索引数中插入的空隙。gap锁锁定一个范围,但不包括记录本身。目的是防止同一事务的两次读,出现幻读的情况。低级别的隔离级别没有。对主键索引或者唯一索引,如果where条件全部名字,则没必要加gap锁。否则加gap锁。
(1)对于主键索引和唯一索引的当前读,用范围条件而不是相等条件检索数据时:
如果范围条件都命中,不会使用Gap锁,只会使用行锁。
如果范围条件部分命中或者都不命中,则使用Gap锁。
(2)对于主键索引和唯一索引的当前读,用相等条件检索数据时,使用行锁。
(3)对于非唯一索引的当前读:使用Gap锁。
(4)对于不走索引的当前读:使用Gap锁(相当于锁表)。
7、语法部分
GROUNP BY:根据给定数据列的每个成员,对查询结果进行分组统计。
HAVING:
通常和GROUNP BY一起使用,在GROUNP BY之后过滤条件。如果没有GROUNP BY ,HAVING就像where一样。
where用来过滤行,HAVING用来过滤组。
sql顺序where>GROUNP BY>HAVING


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









