




目录
- 系统盘清理
- 1.查看
- 2.关闭占用文件的进程
- 3.vim中代码多行删除
- 4.top按内存占用排序
- 5.Linux关闭命令行正在执行的程序
- 6.修改文件权限
- 7.Ubuntu 常用解压与压缩命令
- 8.使用sed、echo删除、添加指定行文件
- 9.多线程执行for循环shell脚本
- 10.linux利用公钥免密登入
- 11. vscode远程链接服务器
- 12.文件内查找指定内容
- 13.kill 僵尸进程
- 14.将普通用户添加到sudo组
- 15.设置服务器断开时长
- 16.查看机器配置
- 17.查看用户相关信息
- 18.rm 删除-(破折号)开头文件
- 19.nautilus 用命令打开文件
- 20.命令行启动 TeamViewer
- 21.Ubuntu下U盘只读文件系统的解决办法
- 22.如何安装软件,让所有用户都能使用
- 23.关闭linux终端还让程序继续执行的方法
- 24.更改分区挂载点
- 25. Read-only file system
- 26.指定密钥路径登录/传输
- 27.测试磁盘性能
- 28.程序挂起执行
- 39.linux下编译出现tmp空间不足解决办法
- 40.终端光标消失的问题
- 41.htop
- 42.fsck.ext4 与 mkfs.ext4区别
- 43.sudo免输密码
- 44.最大打开文件数(句柄)
- 45.关闭swap
- 46.理解virt res shr之间的关系
- 47.文件传输
- 48.设置代理(vpn)
- 49.mac 安装 Homebrew
- 50.修改终端命令提示符及其颜色配置
- 51. 信号量不够
- 52. Ubuntu下的终端多标签切换快捷键
- 53. centos 7 系统设置时区及同步时间
系统盘清理
当系统盘空间不足时,连tab键自动补全都用不上了,得清理下空间。
- cd 到 /tmp目录下,利用du -h 查看已经使用的空间,如果太大,看着没用的内容进行删除;
- cd 到自己的/home目录上,利用du -h 查看已经使用的空间,如果太大,看着没用的内容进行删除。
1.查看
1.1查看文件大小
ls -l -h
输出:
-rw-rw-r-- 1 neu neu 5.5G Aug 3 16:24 web-uk-2002-all_w.base
-rw-rw-r-- 1 neu neu 55M Aug 3 16:24 web-uk-2002-all_w.update
-rw-rw-r-- 1 neu neu 5.5G Aug 3 16:24 web-uk-2002-all_w.updated
查看所有文件(包括隐藏文件):
ls -al -h
1.2查看文件夹大小
Linux中查看各文件夹大小命令du -h --max-depth=1
查看当前路径下各子文件夹大小:
du -h --max-depth=1
sudo du -sh /home/* #查看每个用户的磁盘占用量
1.3 查看进程
查看进程:
1、ps aux查看所有进程的详细信息
2、ps a | grep 进程名查询进程名对应的进程信息。
3、netstat -nlp查看所有处于网络连接的进程,适合服务器端使用。
4、pstree树状显示进程信息,便于查看子进程和父进程。
我们可以通过上一步查看的进程号pid关闭进程,执行以下任一指令即可关闭该进程:
1、kill pid关闭进程。
2、kill -9 -pid强制关闭进程。
3、kill -KILL pid更加强制关闭进程。
4、killall -u username # kill该用户的所有进程
当然,我们也可以通过进程名command来关闭进程。执行下面任一指令即可关闭该进程:
1、pkill 进程名 关闭进程。
2、killall 进程名 关闭同一进程组内的所有进程。
ps aux查看所有进程的详细信息:

ps a查看所有进程:

ps a | grep .*gnup.*或者ps aux |grep .*Chat.*查找特定进程:

1.4 查看系统资源
查看内存:
cat /proc/meminfo 或者 更直观的查看内存的命令:free -m, free -g
查看cpu:
1.cat /proc/cpuinfo 或者 更直观的查看 cpu 的型号命令:dmesg |grep -i xeon
2.直接用top, 然后按 1
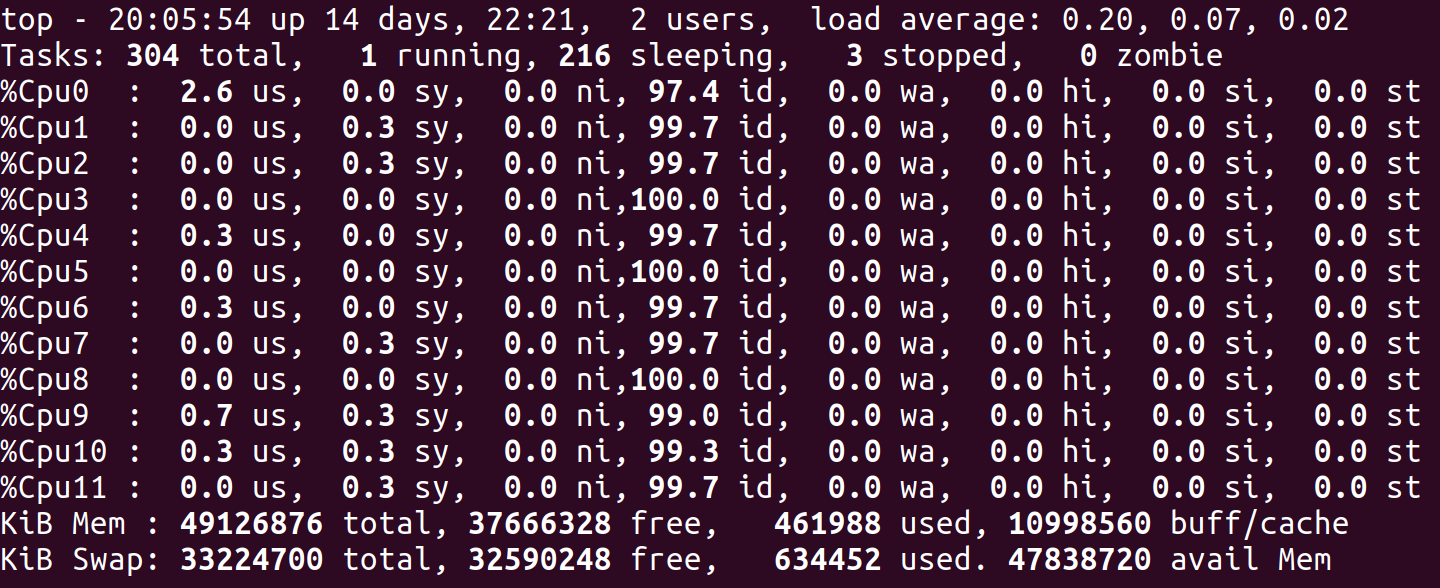
查看硬盘大小:
df -h # 所有盘大小
du -h # 当前目录下已用大小
查看显卡信息:
lspci | grep -i vga
使用 nvidia GPU 可以:
lspci | grep -i nvidia
2.关闭占用文件的进程
ls -al -h
-rw-rw-r-- 1 neu neu 2.9G Aug 5 09:03 .nfs0000000002a502f70000016e
-rw-rw-r-- 1 neu neu 1.2G Aug 5 09:29 .nfs0000000002a504b400000172
当你rm:
rm .nfs0000000002a502480000016f
rm: cannot remove '.nfs0000000002a502f70000016e': Device or resource busy
参考:用 fuser 终止进程
在通过参数指定挂载点时,fuser 命令的 -k 选项会自动地终止找到的进程。当然,必须作为root执行 fuser 命令,才能终止属于其他用户的进程。
命令格式为
fuser -k filename
例如:
fuser -k .nfs0000000002a504b400000172
/expr2/.nfs0000000002a504b400000172: 10795 10796 11692 11694
[19] Killed ./run.sh &>> log_2
[20]- Killed ./run.sh &>> log_2
3.vim中代码多行删除
https://www.cnblogs.com/littleswan/p/12109656.html
删除
dd:删除游标所在的一整行(常用)
ndd:n为数字。删除光标所在的向下n行,例如20dd则是删除光标所在的向下20行
d1G:删除光标所在到第一行的所有数据
dG:删除光标所在到最后一行的所有数据
d$:删除光标所在处,到该行的最后一个字符
d0:那个是数字0,删除光标所在到该行的最前面的一个字符
x,X:x向后删除一个字符(相当于[del]按键),X向前删除一个字符(相当于[backspace]即退格键)
nx:n为数字,连续向后删除n个字符
dd
删除一行
ndd
删除以当前行开始的n行
dw
删除以当前字符开始的一个字符
ndw
删除以当前字符开始的n个字符
光标移动到需要复制的行,输入p,行前复制则输入大写P
光标进行快速移动:
Esc 切换到 Normal Mode 下,然后 hjkl 一顿操作
翻页(适合大范围移动)
ctrl+f表示向下翻页
ctrl+b表示向上翻页
在编辑的情况下CTRL + H是缩进
CTRL+J 是回车
esc的代替键是CTRL+c 或者是CTRL+【‘符号
复制
yy复制游标所在行整行。或大写一个Y。
2yy或y2y复制两行。 ㄟ ,请举一反三好不好! :-)
y^复制至行首,或y0。不含游标所在处字元。
y$复制至行尾。含游标所在处字元。
yw复制一个word。
y2w复制两个字(单词)。
yG复制至档尾。
y1G复制至档首。
p小写p代表贴至游标后(下)。
P大写P代表贴至游标前(上)。
如果只是想使用系统粘贴板的话直接在输入模式按Shift+Inset就可以了
剪切
ndd:其中n是剪切的行数
粘贴
p:粘贴在这行后面
P:粘贴在这行前面
4.top按内存占用排序
1:在命令行提示符执行top命令
2:输入大写P,则结果按CPU占用降序排序。输入大写M,结果按内存占用降序排序。(注:大写P可以在capslock状态输入p,或者按Shift+p)
https://m.linuxidc.com/Linux/2011-03/33582.htm
5.Linux关闭命令行正在执行的程序
https://www.cnblogs.com/sinferwu/p/11056636.html
Ctrl + C 终止 是强制中断程序的执行,进程已经终止。
Ctrl + Z 是将任务中止(暂停的意思),但是此任务并没有结束,他仍然在进程中他只是维持挂起的状态,用户可以使用fg/bg操作继续前台或后台的任务,fg命令重新启动前台被中断的任务,bg命令把被中断的任务放在后台执行。
Ctrl + S 挂起
Ctrl + Q 解挂
Ctrl + D 退出Shell
6.修改文件权限
Ubuntu chmod 命令修改文件chmod读写权限
Ubuntu chmod 命令可以用来修改文件或文件夹的读写权限
chmod 命令有两种使用方式
一、
chmod [u/g/o/a] [+/-/=] [r/w/x] filename
[ ]里都代表的意思:
u表示User,是文件的所有者
g表示跟User同Group的用户
o表示Other,即其他用户
a表示ALL,所有用户
+表示增加权限
-表示取消权限
=表示取消之前的权限,并给予唯一的权限
r表示Read,即读文件
w表示Write,即写文件
x表示运行文件
例如:
sudo chmod u+rw /media/name/name.text
sudo chmod u+rw /media/name/
二、
chmod [xyz] file
[xyz]分别表示数字(最大不超过7),并分别对应User、Group、Other
x,y,z的值由r(r=4),w ( w=2 ),x ( x=1 )来确定
例如:
sudo chmod 765 /media/name/name.text
当然,你也可以使用通配符 ‘*’,来设置当前路径下的所有文件的权限
假如,当前你的路径下有文件:1.txt, 2.html, 3.py
使用命令:
chmod 777 *
可以同时设置上述三个文件的权限为rwx
————————————————————————————
如果你要修改整个文件夹的权限,比如你有一个文件夹WhoJoy,
你想修改这个文件夹(包括内部的所有文件)的权限,那么
可以使用命令:
chmod -R 777 WhoJoy/
其中:-R表示以递归整个文件夹中的子文件
7.Ubuntu 常用解压与压缩命令
.tar.gz压缩文件、 .tgz文件 (推荐!!!)
参考
# .tar.gz 和 .tgz
tar -xzvf FileName.tar.gz # 解压
tar -czvf FileName.tar.gz DirName # 将DirName和其下所有文件(夹)压缩
tar -C DesDirName -zxvf FileName.tar.gz # 解压到目标路径
.tar 打包文件
# 仅打包,并非压缩
tar -xvf FileName.tar # 解包
tar -cvf FileName.tar DirName # 将DirName和其下所有文件(夹)打包
.gz文件
# .gz
gunzip FileName.gz # 解压1
gzip -d FileName.gz # 解压2
gzip FileName # 压缩,只能压缩文件
# 上面的压缩后,原文件会没有,下面的则会保留原文件
gzip -c file1 > file1.gz
gunzip -c file1.gz > file_new # 保留gz文件,并解压到指定文件file_new

.zip文件
# 感觉.zip占用空间比.tar.gz大
unzip FileName.zip # 解压
zip FileName.zip DirName # 将DirName本身压缩
zip -r FileName.zip DirName # 压缩,递归处理,将指定目录下的所有文件和子目录一并压缩
.rar文件
# mac和linux并没有自带rar,需要去下载
rar x FileName.rar # 解压
rar a FileName.rar DirName # 压缩
.tar是打包,.tar.gz才是压缩过的文件,.tar.gz常见于unix系统,在ubuntu或macos可以直接解压,而.zip常见于windows系统,详情可见 .zip和.tar.gz的文件有什么区别?。
zstd 文件压缩和解压命令
详见:zstd 文件压缩和解压命令
sudo apt install -y zstd && zstd --version
单个文件
压缩 zstd a.sql
解压 zstd -d a.sql.zst
tar解压 tar -I zstd -xvf a.tar.zst
tar解压(tar-1.31及以上版本) tar xvf s.tar.zst
压缩文件夹(和tar整合)
方法一 tar cvf nginx.tar /etc/nginx;zstd nginx.tar
方法二 tar -I zstd -cvf nginx.tar.zst /etc/nginx
方法三(tar-1.31及以上版本) tar cvfa nginx.tar.zst /etc/nginx
方法四(tar-1.31及以上版本,不建议,太慢) tar cvfz nginx.tar.zst /etc/nginx
8.使用sed、echo删除、添加指定行文件
Ubuntu/linux使用sed、echo删除、添加指定行文件
一、sed进行数据操作
1、删除file.txt的第一行、最后一行
sed -i '1d' file.txt # 删除第一行
sed -i '$d' file.txt # 删除最后一行
3、删除file.txt的第N行、第M到N行
sed -i 'Nd' file.txt # N为具体数字,指第N行,如10
sed -i 'M,Nd' file.txt # 删除M到N行
sed -i 'M,$d' file.txt # 删除第M行到最后一行的所有行
4、删除file.txt中包含某个关键字开头的所有行
sed '/^abc/d' file.txt # "^abc"表示abc必须出现在行的开头,即删除abc开头的所有行
5、删除file.txt中包含某个关键字的所有行
sed '/abc/d' file.txt # 删除包含abc的所有行(任意位置)
6、替换字符串
sed -i 's/abc/ABC/' file.txt # 替换file.txt每一行的第一个abc为ABC
sed -i 's/abc/ABC/g' file.txt # 使用后缀g,替换file.txt每一行的所有abc为ABC
sed -i 's/^/ABC/' file.txt # 在file.txt每一行的行首追加字符串ABC
sed -i 's/$/ABC/' file.txt # 在file.txt每一行的行尾追加字符串ABC
7、追加行
sed -i 'Na hello_world' file.txt # 在file.txt第N行后面追加一行"hello_world",a表示追加
sed -i 'Ni hello_world' file.txt # 在file.txt第N行前面插入一行"hello_world",i表示插入
sed -i '/hello/a hello_world' file.txt # 在file.txt包含"hello"的所有行后面追加一行"hello_world"
*备注:以上所有命令中 -i 指在原文件上操作,操作后的结果保存到原文件;当然也可以用 - e 关键字输出操作结果到新文件。
# eg.
sed -e '1d' file.txt > new_file.txt # 删除文件file.txt的第一行,将操作后的结果保存到new_file.txt
# 其余命令类似
二、echo进行数据操作
1、显示行
echo "hello world" # 在终端打印"hello world"
2、写入行
echo "hello world" >> file.txt # 在文件file.txt末尾写入行"hello world"
3、覆盖写入
echo "hello world" > file.txt # 文件file.txt中原来内容会被覆盖,只保存"hello world",无论操作多少次,file.txt只保存最新写入的一行
4、写入包含引号的行(特别注意)
# 比如,写入line = 你好,"老王",你今天真帅!
# 注意,这里line的内容包含双引号"",属于特殊符号,需要使用转义符号
echo "你好,\"老王\",你今天真帅!" file.txt
————————————————
版权声明:本文为优快云博主「ken_asr」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.youkuaiyun.com/zkgoup/article/details/110432316
9.多线程执行for循环shell脚本
多线程执行for循环shell脚本
当时你执行的shell脚本里面for比较多时,可以考虑让for里面的内容同时执行。
例如:
#!/bin/bash
start=`date +%s` #定义脚本运行的开始时间
for ((i=1;i<=1000;i++))
do
{
sleep 1 #sleep 1用来模仿执行一条命令需要花费的时间(可以用真实命令来代替)
echo 'success'$i;
}& #用{}把循环体括起来,后加一个&符号,代表每次循环都把命令放入后台运行
#一旦放入后台,就意味着{}里面的命令交给操作系统的一个线程处理了
#循环了1000次,就有1000个&把任务放入后台,操作系统会并发1000个线程来处理
#这些任务
done
wait #wait命令的意思是,等待(wait命令)上面的命令(放入后台的)都执行完毕了再
#往下执行。
#在这里写wait是因为,一条命令一旦被放入后台后,这条任务就交给了操作系统
#shell脚本会继续往下运行(也就是说:shell脚本里面一旦碰到&符号就只管把它
#前面的命令放入后台就算完成任务了,具体执行交给操作系统去做,脚本会继续
#往下执行),所以要在这个位置加上wait命令,等待操作系统执行完所有后台命令
end=`date +%s` #定义脚本运行的结束时间
echo "TIME:`expr $end - $start`"
对于多层循环的,一次模仿即可。
但是如果任务数量超过了机器可以核数,则可以设置每次最多时行的数量限制,详细内容请看上面那篇博客。
10.linux利用公钥免密登入
- 分别在本地和服务器上生成ssh key
ssh-keygen -t rsa -C "邮箱@qq.com"
直接三次回车,会提示公钥文件id_rsa.pub的存储路径
[root@ahuang bin]# ssh-keygen -t rsa -C 'test@qq.com'
Generating public/private rsa key pair.
Enter file in which to save the key (/root/.ssh/id_rsa):
Enter passphrase (empty for no passphrase):
Enter same passphrase again:
Your identification has been saved in /root/.ssh/id_rsa.
Your public key has been saved in /root/.ssh/id_rsa.pub.
查看公钥并配置
[root@ahuang bin]# cat /username/.ssh/id_rsa.pub
- 将本地id_rsa.pub上传到服务器上(本地操作)
(base) username@username-desktop:~/.ssh$ scp id_rsa.pub username@serverip:/home/username
The authenticity of host '[username]:2333 ([]:2333)' can't be established.
ECDSA key fingerprint is SHA256:5ubJVf9Zv0aQ+DMJkzvoVhxFkn+SlqpX2yXuRUHZvPE.
Are you sure you want to continue connecting (yes/no)? yes
Warning: Permanently added '[username]:2333' (ECDSA) to the list of known hosts.
xx@xxx's password: # 需要数入密码登入
id_rsa.pub
- 将上传的key添加到服务器上的authorized_keys文件中(服务器上操作)
[username@WeServer ~]$ cd .ssh
[username@WeServer .ssh]$ ls
authorized_keys id_rsa id_rsa.pub
[username@WeServer .ssh]$ cat my_id_rsa.pub >> authorized_keys
#这个命令将my_id_rsa.pub的内容追加到了authorized_keys的内容后面
[username@WeServer .ssh]$ cat authorized_keys
ssh-rsa AAAAB3NzaC1yc2ExPSkfGpHo2C1AmvDVw926VkdOxq6Mh6Z6nYNvP6pmtbYmw/x3r53FcejOxCprx4ShG/cOWu7Bs47MnmCurCDbV/bKd1d1aboioS0Li9MdUf60MrUhu3eDe2bVytaBwkpwu username@qq.com
[username@WeServer .ssh]$ ls
authorized_keys id_rsa id_rsa.pub
[username@WeServer .ssh]$ chmod 600 authorized_keys # 给文件授权
- 测时登入(本地操作)
(base) username@username-desktop:~/.ssh$ ssh username@serverip
Activate the web console with: systemctl enable --now cockpit.socket
Last login: Wed Sep 22 18:55:11 2021
[username@WeServer ~]$ ls
可以发现,此时已经无需输入密码了。
11. vscode远程链接服务器
- 1.安装Remote-SSH
参考教程1,参考教程2 - 2.config配置文件
其中配置文件参考如下:
注意以下错误:Host temp_aliyun ServerAliveInterval 50 ServerAliveCountMax 3 HostName 47.104.176.95 User root Port 22 IdentityFile ~/.ssh/id_rsa.pub IdentitiesOnly yes- 如果提示错误
load pubkey "\342\200\252C:\\Users\\sss\\.ssh\\id_rsa": Invalid argument, 则检测路径是否写错,如果没有写错依然提示,则可能是编码问题,如果复制过来的,建议可以尝试删了手写一遍。 - SSH Key: “Permissions 0644 for ‘id_rsa.pub’ are too open.” on mac, 可以采用
chmod 400 ~/.ssh/id_rsa, 参考https://stackoverflow.com/questions/29933918/ssh-key-permissions-0644-for-id-rsa-pub-are-too-open-on-mac. - “id_rsa.pub file SSH Error: invalid format”, 参考https://stackoverflow.com/questions/48328446/id-rsa-pub-file-ssh-error-invalid-format, 将
~/.ssh/id_rsa.pub改为~/.ssh/id_rsa.
- 如果提示错误
- 3.修改缓存路径,vscode会产生很多ipch相关文件,这个非常占据空间,它是vscode缓存的一些信息,可以定期删除,或者修改缓存路径。推荐后者方案,可以将其设置到空间比较大的盘上去。配置方法,参考此链接,在VSCode找到设置→扩展→C/C++→Intelli Sense Cache Path,如上图。1处写明了vscode默认Intelli Sense缓存文件路径所在位置,windows和Linux不同;2处可以更改为你要保存缓存文件的位置。据我所知,这些缓存文件删了也不影响的之前的文件的,所以可以随时删~只是每次编译又会重新产生,所以还是把缓存路径改为别的盘吧.

12.文件内查找指定内容
grep -[acinvo] '搜索内容串' filename
eq:
查找filename中以1开头且紧跟一个空格的行:
xx@xxxx:xx$ grep "^1 " filename
1 1
1 2
1 11
1 4
1 10
1 12
1 13
1 16
1 17
13.kill 僵尸进程
https://stackoverflow.com/questions/16944886/how-to-kill-zombie-process
zombie is already dead, so you cannot kill it. To clean up a zombie, it must be waited on by its parent, so killing the parent should work to eliminate the zombie. (After the parent dies, the zombie will be inherited by pid 1, which will wait on it and clear its entry in the process table.) If your daemon is spawning children that become zombies, you have a bug. Your daemon should notice when its children die and wait on them to determine their exit status.
An example of how you might send a signal to every process that is the parent of a zombie (note that this is extremely crude and might kill processes that you do not intend. I do not recommend using this sort of sledge hammer):
# Don't do this. Incredibly risky sledge hammer!
kill -9 $(ps -A -ostat,ppid | awk '/[zZ]/ && !a[$2]++ {print $2}')
14.将普通用户添加到sudo组
新建一个用户:
useradd -m yourusername # yourusername 是我的用户名
然后通过下面命令设置密码:
passwd mypassword # 为刚创建的用户设置密码
把普通用户增加到 sudo 组 通常使用两种方法:
第一种: 修改/etc/sudoers 文件
先cd到/etc/sudoers目录下
由于sudoers文件为只读权限,所以需要添加写入权限,chmod u+w sudoers
vim sudoers
找到root ALL = (ALL) ALL这一行,在下一行加入username ALL = (ALL) ALL。username指代你想加入sudo组的用户名。
把sudoers文件的权限修改回来。chmod u-w sudoers
这样普通用户可以执行sudo命令了
…
第二种:直接执行命令添加用户到 sudo
# 添加到sudo组
usermod -a -G sudo yourusername # yourusername 为用户名
# 撤销上面的操作,即将指定用户从sudo组中移除:
groups yourusername # 查看当前分组
sudo deluser yourusername sudo
groups yourusername
让Linux用户sudo操作免密码:
https://bingozb.github.io/views/default/58.html#%E8%A7%A3%E5%86%B3
15.设置服务器断开时长
默认情况下,与服务器没有操作后,会自动断开,我们可以修改这个时长:
解决ssh登录后闲置时间过长而断开连接
sudo vim /etc/ssh/sshd_config
修改其中的参数:
ClientAliveInterval 60
ClientAliveCountMax 10
最后使配置文件生效:
sudo /etc/init.d/ssh restart
>>
[ ok ] Restarting ssh (via systemctl): ssh.service
16.查看机器配置
lscpu # cpu数量
cat /proc/cpuinfo # cpu信息
free -m # 内存容量,在加上-h单位为G
lsblk # 磁盘挂载
fdisk -l # 磁盘分区
df -h # 磁盘总量以及使用情况
du -h # 该目录下占用的磁盘空间
uname -a # 查看系统内核版本
cat /etc/lsb-release # 系统版本
lspci |grep VGA # 查看显卡型号
17.查看用户相关信息
who #查看当前系统中有哪些人登录
whoami #查看我是谁
w #查看活动用户
id username #查看指定用户信息
last #查看用户登录日志
cut -d: -f 1 /etc/passwd #查看系统所有用户
cut -d: -f 1 /etc/group #查看系统所有组
crontab -l #查看当前用户的计划任务
18.rm 删除-(破折号)开头文件
rm将无法删除以破折号-开头的文件,它会解析成选项。
解决这个问题的一个方法就是在要删除的文件的前边加上"./"
如:
rm ./-slow_query_130103.txt.gz
另一种解决的方法是 在文件名前边加上 " -- ".
如
rm -- -slow_query_130102.txt.gz
19.nautilus 用命令打开文件
nautilus /home/dir_name
20.命令行启动 TeamViewer
https://blog.youkuaiyun.com/Scythe666/article/details/82780651
# 启动或停止 daemon
sudo teamviewer --daemon stop
sudo teamviewer --daemon start
# 打印 id
sudo teamviewer --info print id
`## 设置密码
sudo teamviewer --passwd <password>``
## 21. cp多个文件
参考:[linux cp简单用法,五分钟学会使用Linux cp命令](https://blog.youkuaiyun.com/weixin_36177719/article/details/116920251?spm=1001.2101.3001.6650.8&utm_medium=distribute.pc_relevant.none-task-blog-2%7Edefault%7EBlogCommendFromBaidu%7ERate-8-116920251-blog-105860821.235%5Ev27%5Epc_relevant_3mothn_strategy_recovery&depth_1-utm_source=distribute.pc_relevant.none-task-blog-2%7Edefault%7EBlogCommendFromBaidu%7ERate-8-116920251-blog-105860821.235%5Ev27%5Epc_relevant_3mothn_strategy_recovery&utm_relevant_index=11)
```shell
cp [options] <source file or directory> <target file or directory>
或
cp [options] source1 source2 source3 …. directory
上面第一条命令为单个文件或目录拷贝,下一个为多个文件拷贝到最后的目录。
options选项包括:
- a 保留链接和文件属性,递归拷贝目录,相当于下面的d、p、r三个选项组合。
- d 拷贝时保留链接。
- f 删除已经存在目标文件而不提示。
- i 覆盖目标文件前将给出确认提示,属交互式拷贝。
- p 复制源文件内容后,还将把其修改时间和访问权限也复制到新文件中。
- r 若源文件是一目录文件,此时cp将递归复制该目录下所有的子目录和文件。当然,目标文件必须为一个目录名。
- l 不作拷贝,只是链接文件。
-s 复制成符号连结文件 (symbolic link),亦即『快捷方式』档案;
-u 若 destination 比 source 旧才更新 destination。
cp命令使用范例:
1、将文档 file1复制成file2,复制后名称被改file2
cp -i file1 file2
或,
cp file1 file2
2、将文档 file1复制到dir1目录下,复制后名称仍未file1
cp -i file1 dir1
或,
cp file1 dir1
3、将目录dir1复制到dir2目录下,复制结果目录被改名为dir2
cp -r dir1 dir2
4、将目录dir1下所有文件包括文件夹,都复制到dir2目录下
cp -r dir1/*.* dir2
————————————————
版权声明:本文为优快云博主「sqbzo」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.youkuaiyun.com/sqbzo/article/details/9000027
使用通配符,将expr-的文件全部复制到./中:
cp -r /dir/expr-* ./
21.Ubuntu下U盘只读文件系统的解决办法
参考:
- https://blog.youkuaiyun.com/ustccw/article/details/79040757
- https://askubuntu.com/questions/147228/how-to-repair-a-corrupted-fat32-file-system
22.如何安装软件,让所有用户都能使用
当您安装软件时,您可以选择将其安装在所有用户都可以访问的位置,这样所有用户都可以执行和访问该软件。
一般来说,您可以将软件安装在以下位置之一:
/usr/local/bin: 这是系统范围的可执行文件存储位置,所有用户都可以访问。如果您将软件安装在此目录下,所有用户都可以执行该软件。
/opt: 这是一个用于存放“可选”应用程序的目录。它被用来存放那些不需要与其它应用程序共享的应用程序。您可以将软件安装在此目录下,以使所有用户都能访问。
如果您将软件安装在其他位置,例如用户主目录下,那么只有该用户才能访问该软件。其他用户将无法访问该软件,除非他们具有足够的权限。
23.关闭linux终端还让程序继续执行的方法
摘抄自:关闭linux终端还让程序继续执行的方法
这个博主不仅给出了方案,还分析了原因,很赞!
- nohup
nohup sh test.sh & # 直接关闭当前终端,再打开一个查看 - exit
sh test.sh & exit # 不直接关闭当前终端,而是用exit退出
更多方法,见关闭linux终端还让程序继续执行的方法。
24.更改分区挂载点
通过更改分区挂载点让所有用户访问某给分区(挂载的盘)。
0.查看没有挂载的硬盘
查看系统检测的硬盘 命令:
$ lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINTS
loop0 7:0 0 4K 1 loop /snap/bare/5
loop1 7:1 0 902.5M 1 loop /snap/clion/249
loop2 7:2 0 906.9M 1 loop /snap/clion/250
loop3 7:3 0 55.7M 1 loop /snap/core18/2785
loop4 7:4 0 55.7M 1 loop /snap/core18/2790
loop5 7:5 0 63.4M 1 loop /snap/core20/1974
loop6 7:6 0 63.5M 1 loop /snap/core20/2015
loop7 7:7 0 73.9M 1 loop /snap/core22/858
loop8 7:8 0 73.9M 1 loop /snap/core22/864
loop9 7:9 0 240.5M 1 loop /snap/firefox/3206
loop10 7:10 0 238.8M 1 loop /snap/firefox/3252
loop11 7:11 0 349.7M 1 loop /snap/gnome-3-38-2004/140
loop12 7:12 0 349.7M 1 loop /snap/gnome-3-38-2004/143
loop13 7:13 0 496.9M 1 loop /snap/gnome-42-2204/132
loop14 7:14 0 497M 1 loop /snap/gnome-42-2204/141
loop15 7:15 0 91.7M 1 loop /snap/gtk-common-themes/1535
loop16 7:16 0 45.9M 1 loop /snap/snap-store/638
loop17 7:17 0 12.3M 1 loop /snap/snap-store/959
loop18 7:18 0 40.8M 1 loop /snap/snapd/20092
loop19 7:19 0 40.9M 1 loop /snap/snapd/20290
loop20 7:20 0 428K 1 loop /snap/snapd-desktop-integration/57
loop21 7:21 0 452K 1 loop /snap/snapd-desktop-integration/83
vda 252:0 0 200G 0 disk
├─vda1 252:1 0 1M 0 part
├─vda2 252:2 0 513M 0 part /boot/efi
└─vda3 252:3 0 199.5G 0 part /var/snap/firefox/common/host-hunspell
/
vdb 252:16 0 500G 0 disk
确认vdb没有挂载,但是存在
1.卸载当前挂载的目录
$ df -h # 先查看,确定需要修改的分区/dev/vdb
Filesystem Size Used Avail Use% Mounted on
tmpfs 9.5G 2.0M 9.5G 1% /run
/dev/vda3 196G 79G 107G 43% /
tmpfs 48G 3.2M 48G 1% /dev/shm
tmpfs 5.0M 0 5.0M 0% /run/lock
/dev/vda2 512M 6.1M 506M 2% /boot/efi
tmpfs 9.5G 112K 9.5G 1% /run/user/1000
/dev/vdb 492G 28K 467G 1% /home/user/data
tmpfs 9.5G 64K 9.5G 1% /run/user/1002
tmpfs 9.5G 64K 9.5G 1% /run/user/1001
卸载:
$ sudo umount /dev/vdb
$ df -h
Filesystem Size Used Avail Use% Mounted on
tmpfs 9.5G 2.0M 9.5G 1% /run
/dev/vda3 196G 79G 107G 43% /
tmpfs 48G 3.2M 48G 1% /dev/shm
tmpfs 5.0M 0 5.0M 0% /run/lock
/dev/vda2 512M 6.1M 506M 2% /boot/efi
tmpfs 9.5G 112K 9.5G 1% /run/user/1000
tmpfs 9.5G 64K 9.5G 1% /run/user/1002
tmpfs 9.5G 64K 9.5G 1% /run/user/1001
2.更改分区挂载点
如果新的挂载点不存在,需要新建目录,在终端输入(新挂载点以‘/mnt2’为例):
$ sudo mkdir /mnt2 # 创建挂载点
$ df -h
Filesystem Size Used Avail Use% Mounted on
tmpfs 9.5G 2.0M 9.5G 1% /run
/dev/vda3 196G 79G 107G 43% /
tmpfs 48G 3.2M 48G 1% /dev/shm
tmpfs 5.0M 0 5.0M 0% /run/lock
/dev/vda2 512M 6.1M 506M 2% /boot/efi
tmpfs 9.5G 112K 9.5G 1% /run/user/1000
tmpfs 9.5G 64K 9.5G 1% /run/user/1002
tmpfs 9.5G 64K 9.5G 1% /run/user/1001
$ sudo mount /dev/vdb /mnt2 # 将目标分区挂载到指定目录下
$ df -h
Filesystem Size Used Avail Use% Mounted on
tmpfs 9.5G 2.0M 9.5G 1% /run
/dev/vda3 196G 79G 107G 43% /
tmpfs 48G 3.2M 48G 1% /dev/shm
tmpfs 5.0M 0 5.0M 0% /run/lock
/dev/vda2 512M 6.1M 506M 2% /boot/efi
tmpfs 9.5G 112K 9.5G 1% /run/user/1000
tmpfs 9.5G 64K 9.5G 1% /run/user/1002
tmpfs 9.5G 64K 9.5G 1% /run/user/1001
/dev/vdb 492G 28K 467G 1% /mnt2
3.授权所有用户读写权限
$ sudo chmod -R 777 /mnt2
可以用其它用户去访问测试了.
25. Read-only file system
造成这个问题的原因大多数是因为非正常关机后导致文件系统受损引起的,在系统重启之后,受损分区就会被Linux自动挂载为只读。
解决的方法是通过fsck来修复文件系统,然后重启即可,以下是以针对/dev/xvde1分区,ext4文件系统分区的一个操作案例:
fsck.ext4 -y /dev/xvde1
本文只着重强调一点:要针对出问题的分区进行操作,在挂载了多个硬盘的机器上要仔细分辨一下。
最后重启,等一会重新登录就行了:
shutdown -r now
26.指定密钥路径登录/传输
登录:
ssh -i /root/.ssh/ido_sch_pro ido@192.168.1.111 -p 774 # -i指定密钥,-p指定端口
传输:
scp -i /root/.ssh/ido_sch_pro file_name 2.168.1.11
详见:scp命令详解
27.测试磁盘性能
参考:
读性能:
$ hdparm -Tt /dev/sda
# 其中的/dev/sda就是你希望测试的盘,可以通过df -h来看:
$ df -h
Filesystem Size Used Avail Use% Mounted on
/dev/sda 186G 0 186G 0% /mnt

可以看到,2秒钟读取了19812MB的缓存,约合9917.83 MB/sec;
在3秒中读取了1986MB磁盘(物理读),读取速度约合661.56MB/sec.
写性能:
$ time dd if=/dev/zero of=/tmp/test.dat bs=20G count=1 # of路径可选
0+1 records in
0+1 records out
2147479552 bytes (2.1 GB, 2.0 GiB) copied, 2.95092 s, 728 MB/s
real 0m3.245s
user 0m0.000s
sys 0m2.396s
28.程序挂起执行
具体用法参考:Linux nohup 命令
nohup 英文全称 no hang up(不挂起),用于在系统后台不挂断地运行命令,退出终端不会影响程序的运行。
nohup 命令,在默认情况下(非重定向时),会输出一个名叫 nohup.out 的文件到当前目录下,如果当前目录的 nohup.out 文件不可写,输出重定向到 $HOME/nohup.out 文件中。
语法格式
nohup Command [ Arg … ] [ & ]
参数说明:
Command:要执行的命令。
Arg:一些参数,可以指定输出文件。
&:让命令在后台执行,终端退出后命令仍旧执行。
实例
以下命令在后台执行 root 目录下的 runoob.sh 脚本:
nohup /root/runoob.sh &
39.linux下编译出现tmp空间不足解决办法
tmp文件夹空间不足了,不能满足编译的需求,编译的中间文件不能写入。
解决办法 :修改/tmp文件位置,你可以在空间充足的地方mkdir 文件夹——你可以使用的文件夹,例如:
mkdir /home/username/tmp
为了是设置生效,需要设置环境变量,只要
export TMPDIR=/home/username/tmp
编辑完成记得
source ~/.bashrc
这样就不会出现 tmp文件夹不够用的情况。
40.终端光标消失的问题
在终端(Terminal)中输入以下命令即可显示光标:
echo -e "\033[?25h"
在终端(Terminal)中输入以下命令即可隐藏光标:
echo -e "\033[?25l"
参考自:https://www.jianshu.com/p/3a9cc48748f1
41.htop
主要分为CPU和进程监控,上部分显示了每个CPU的活动情况,下面部分展示了每个进程的情况,包括:PID, VIRT(虚拟内存), RES(物理内存) 等。可以用鼠标点击进行排序。
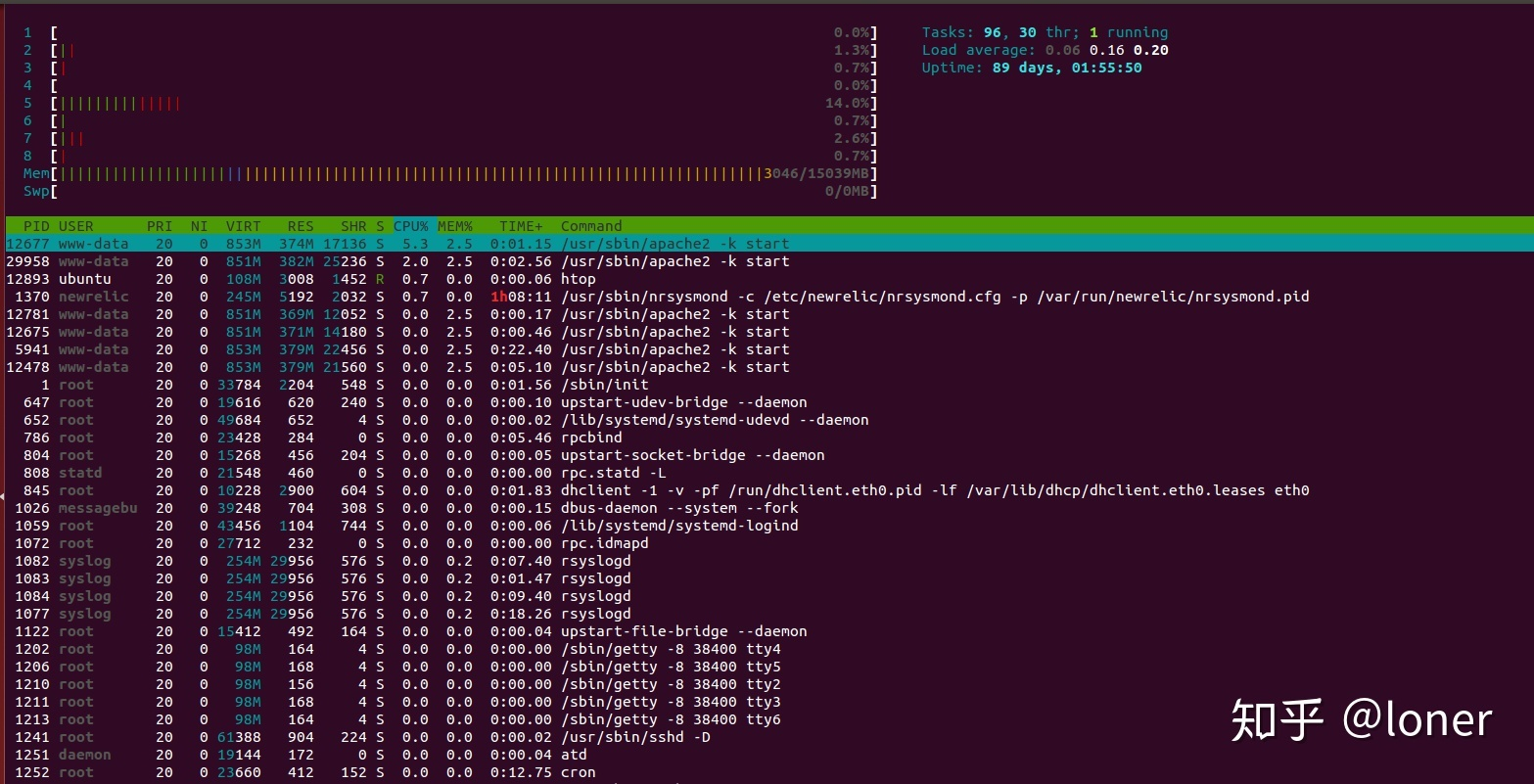
42.fsck.ext4 与 mkfs.ext4区别
fsck.ext4 和 mkfs.ext4 都与 ext4 文件系统有关,但它们分别是文件系统的检查和创建工具。
fsck.ext4:
fsck.ext4 是用于检查和修复 ext4 文件系统中的错误的工具。它会扫描文件系统的数据结构,检查并修复可能的问题,例如坏块、未使用的块、链接错误等。它在文件系统损坏时尤其有用,可以尝试修复损坏的文件系统。
fsck.ext4 在文件系统不正常关闭(如系统崩溃)或者文件系统出现问题时可以使用。它会尝试恢复文件系统到一种一致的状态。
mkfs.ext4:
mkfs.ext4 是用于创建 ext4 文件系统的工具。它会在一个分区上创建一个全新的 ext4 文件系统,为其分配数据结构、超级块、inode 等元数据。
mkfs.ext4 通常在格式化分区或者创建新的硬盘分区时使用。它会擦除分区中的所有数据并构建一个全新的文件系统。
总结:fsck.ext4 用于检查和修复已有的 ext4 文件系统中的问题,而 mkfs.ext4 用于创建一个新的 ext4 文件系统。
43.sudo免输密码
sudo visudo /etc/sudoers
# 在文件末尾添加
your_user_name ALL=(ALL) NOPASSWD:ALL
44.最大打开文件数(句柄)
参考:https://help.fanruan.com/finebi/doc-view-28.html
特别注意:修改时一定要注意针对的用户,以及你代码运行时的用户身份(例如sudo会以root身份执行,修改普通用户的就无效), https://www.cnblogs.com/ExMan/p/11208226.html
Linux 系统本身默认系统应用最大打开的文件数为 1024,BI 执行时会读取保存在本地的数据,有些情况 BI 打开的文件数会超过这个限制,因此需要手动改掉linux系统的最大打开文件数。该修改在不同情况下会涉及到3个关键值。
| 参数 | 说明 | 默认值 |
|---|---|---|
| nofile | 单个进程的最大打开文件数 | 1024 |
| nr_open | 单个进程可分配的最大文件数 | 1,048,576 |
| file-max | 系统内核一共可以打开的最大文件数 | 185,745 |
基于修改策略,请在执行下文的修改操作前,先查看各个参数的大小。
| 参数 | 查看命令 | 默认值 |
|---|---|---|
| nofile | ulimit -n 命令,单个进程的最大打开文件数 | 1024 |
| nr_open | cat /proc/sys/fs/nr_open 命令,单个进程可分配的最大文件数 | 1,048,576 |
| file-max | cat /proc/sys/fs/file-max 命令,系统内核一共可以打开的最大文件数 | 185,745 |
修改方法:https://help.fanruan.com/finebi/doc-view-28.html
具体修改方法:修改LInux的文件打开数为65534个,而且需要永久生效
注意需要重新登录帐号,修改才会生效!!!
sudo vim /etc/security/limits.conf
# 将下列内容添加到文件中, 修改对应用户名(root/xxxx)
# 注意如果是对于sudo执行的命令,其用户身份对应root
your_user_name soft nofile 65534
your_user_name hard nofile 65534
45.关闭swap
永久关闭
vi /etc/fstab
注释掉最后一行 /swap.img(可能swap行内容不完全一样):
# /etc/fstab: static file system information.
#
# Use 'blkid' to print the universally unique identifier for a
# device; this may be used with UUID= as a more robust way to name devices
# that works even if disks are added and removed. See fstab(5).
#
# <file system> <mount point> <type> <options> <dump> <pass>
# / was on /dev/ubuntu-vg/ubuntu-lv during curtin installation
/dev/disk/by-id/dm-uuid-LVM-Bd1Y18z2BDUtZLfxa6xAkBwmdM5CJWzJ6VffRRnKPUXYwBOeeGpa3aVDru0ReKDB / ext4 defaults 0 0
# /boot was on /dev/sda2 during curtin installation
/dev/disk/by-uuid/78606f3c-cc6d-4bf2-b0c1-e8a3f27847b4 /boot ext4 defaults 0 0
# /boot/efi was on /dev/sda1 during curtin installation
/dev/disk/by-uuid/E557-046B /boot/efi vfat defaults 0 0
# /swap.img none swap sw 0 0
原文链接:https://blog.youkuaiyun.com/yilovexing/article/details/120163308
46.理解virt res shr之间的关系
建议阅读原文:https://www.orchome.com/298
作者:無名
链接:https://www.orchome.com/298
来源:OrcHome
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
想必在linux上写过程序的同学都有分析进程占用多少内存的经历,或者被问到这样的问题——你的程序在运行时占用了多少内存(物理内存)?
通常我们可以通过top或者htop命令查看进程占用了多少内存。这里我们可以看到VIRT、RES和SHR三个重要的指标,他们分别代表什么意思呢?
这是本文需要跟大家一起探讨的问题。当然如果更加深入一点,你可能会问进程所占用的那些物理内存都用在了哪些地方?这时候top命令可能不能给到你你所想要的答案了,不过我们可以分析proc文件系统提供的smaps文件,这个文件详尽地列出了当前进程所占用物理内存的使用情况。
本文将分为三个部分
- 分简要阐述虚拟内存和驻留内存这两个重要的概念;
- 解释top命令中VIRT、RES以及SHR三个参数的实际参考意义;
- 向大家介绍一下smaps文件的格式,通过分析smaps文件我们可以详细了解进程物理内存的使用情况,比如mmap文件占用了多少空间、动态内存开辟消耗了多少空间、函数调用栈消耗了多少空间等等。
关于内存的两个概念
要理解top命令关于内存使用情况的输出,我们必须首先搞清楚虚拟内存(Virtual Memory)和驻留内存(Resident Memory)两个概念。
虚拟内存
首先需要强调的是虚拟内存不同于物理内存,虽然两者都包含内存字眼但是它们属于两个不同层面的概念。进程占用虚拟内存空间大并非意味着程序的物理内存也一定占用很大。虚拟内存是操作系统内核为了对进程地址空间进行管理(process address space management)而精心设计的一个逻辑意义上的内存空间概念。我们程序中的指针其实都是这个虚拟内存空间中的地址。比如我们在写完一段C++程序之后都需要采用g++进行编译,这时候编译器采用的地址其实就是虚拟内存空间的地址。因为这时候程序还没有运行,何谈物理内存空间地址?凡是程序运行过程中可能需要用到的指令或者数据都必须在虚拟内存空间中。既然说虚拟内存是一个逻辑意义上(假象的)的内存空间,为了能够让程序在物理机器上运行,那么必须有一套机制可以让这些假象的虚拟内存空间映射到物理内存空间(实实在在的RAM内存条上的空间)。这其实就是操作系统中页映射表(page table)所做的事情了。内核会为系统中每一个进程维护一份相互独立的页映射表。页映射表的基本原理是将程序运行过程中需要访问的一段虚拟内存空间通过页映射表映射到一段物理内存空间上,这样CPU访问对应虚拟内存地址的时候就可以通过这种查找页映射表的机制访问物理内存上的某个对应的地址。“页(page)”是虚拟内存空间向物理内存空间映射的基本单元。
下图演示了虚拟内存空间和物理内存空间的相互关系,它们通过Page Table关联起来。其中虚拟内存空间中着色的部分分别被映射到物理内存空间对应相同着色的部分。而虚拟内存空间中灰色的部分表示在物理内存空间中没有与之对应的部分,也就是说灰色部分没有被映射到物理内存空间中。这么做也是本着“按需映射”的指导思想,因为虚拟内存空间很大,可能其中很多部分在一次程序运行过程中根本不需要访问,所以也就没有必要将虚拟内存空间中的这些部分映射到物理内存空间上。
到这里为止已经基本阐述了什么是虚拟内存了。总结一下就是,虚拟内存是一个假象的内存空间,在程序运行过程中虚拟内存空间中需要被访问的部分会被映射到物理内存空间中。虚拟内存空间大只能表示程序运行过程中可访问的空间比较大,不代表物理内存空间占用也大。
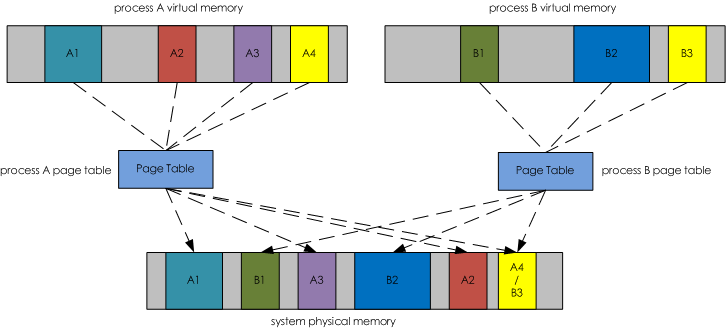
虚拟内存空间到物理内存空间映射
驻留内存
驻留内存,顾名思义是指那些被映射到进程虚拟内存空间的物理内存。上图中,在系统物理内存空间中被着色的部分都是驻留内存。比如,A1、A2、A3和A4是进程A的驻留内存;B1、B2和B3是进程B的驻留内存。进程的驻留内存就是进程实实在在占用的物理内存。一般我们所讲的进程占用了多少内存,其实就是说的占用了多少驻留内存而不是多少虚拟内存。因为虚拟内存大并不意味着占用的物理内存大。
top命令中VIRT、RES和SHR
关于虚拟内存和驻留内存这两个概念我们说到这里。下面一部分我们来看看top命令中VIRT、RES和SHR分别代表什么意思。
top命令中VIRT、RES和SHR的含义
搞清楚了虚拟内存的概念之后解释VIRT的含义就很简单了。VIRT表示的是进程虚拟内存空间大小。对应到图1中的进程A来说就是A1、A2、A3、A4以及灰色部分所有空间的总和。也就是说VIRT包含了在已经映射到物理内存空间的部分和尚未映射到物理内存空间的部分总和。
RES的含义是指进程虚拟内存空间中已经映射到物理内存空间的那部分的大小。对应到图1中的进程A来说就是A1、A2、A3以及A4几个部分空间的总和。所以说,看进程在运行过程中占用了多少内存应该看RES的值而不是VIRT的值。
最后来看看SHR所表示的含义。SHR是share(共享)的缩写,它表示的是进程占用的共享内存大小。在上图中我们看到进程A虚拟内存空间中的A4和进程B虚拟内存空间中的B3都映射到了物理内存空间的A4/B3部分。咋一看很奇怪。为什么会出现这样的情况呢?其实我们写的程序会依赖于很多外部的动态库(.so),比如libc.so、libld.so等等。这些动态库在内存中仅仅会保存/映射一份,如果某个进程运行时需要这个动态库,那么动态加载器会将这块内存映射到对应进程的虚拟内存空间中。多个进展之间通过共享内存的方式相互通信也会出现这样的情况。这么一来,就会出现不同进程的虚拟内存空间会映射到相同的物理内存空间。这部分物理内存空间其实是被多个进程所共享的,所以我们将他们称为共享内存,用SHR来表示。某个进程占用的内存除了和别的进程共享的内存之外就是自己的独占内存了。所以要计算进程独占内存的大小只要用RES的值减去SHR值即可。
进程的smaps文件
通过top命令我们已经能看出进程的虚拟空间大小(VIRT)、占用的物理内存(RES)以及和其他进程共享的内存(SHR)。但是仅此而已,如果我想知道如下问题:
- 进程的虚拟内存空间的分布情况,比如heap占用了多少空间、文件映射(
mmap)占用了多少空间、stack占用了多少空间? - 进程是否有被交换到swap空间的内存,如果有,被交换出去的大小?
mmap方式打开的数据文件有多少页在内存中是脏页(dirty page)没有被写回到磁盘的?mmap方式打开的数据文件当前有多少页面已经在内存中,有多少页面还在磁盘中没有加载到page cahe中?
。。。等等
以上这些问题都无法通过top命令给出答案,但是有时候这些问题正是我们在对程序进行性能瓶颈分析和优化时所需要回答的问题。所幸的是,世界上解决问题的方法总比问题本身要多得多。linux通过proc文件系统为每个进程都提供了一个smaps文件,通过分析该文件我们就可以一一回答以上提出的问题。
在smaps文件中,每一条记录(如下图所示)表示进程虚拟内存空间中一块连续的区域。其中第一行从左到右依次表示地址范围、权限标识、映射文件偏移、设备号、inode、文件路径。详细解释可以参见understanding-linux-proc-id-maps。
接下来8个字段的含义分别如下:
Size:表示该映射区域在虚拟内存空间中的大小。 Rss:表示该映射区域当前在物理内存中占用了多少空间Shared_Clean:和其他进程共享的未被改写的page的大小Shared_Dirty: 和其他进程共享的被改写的page的大小Private_Clean:未被改写的私有页面的大小。 Private_Dirty: 已被改写的私有页面的大小。Swap:表示非mmap内存(也叫anonymous
memory,比如malloc动态分配出来的内存)由于物理内存不足被swap到交换空间的大小。Pss:该虚拟内存区域平摊计算后使用的物理内存大小(有些内存会和其他进程共享,例如mmap进来的)。比如该区域所映射的物理内存部分同时也被另一个进程映射了,且该部分物理内存的大小为1000KB,那么该进程分摊其中一半的内存,即Pss=500KB。
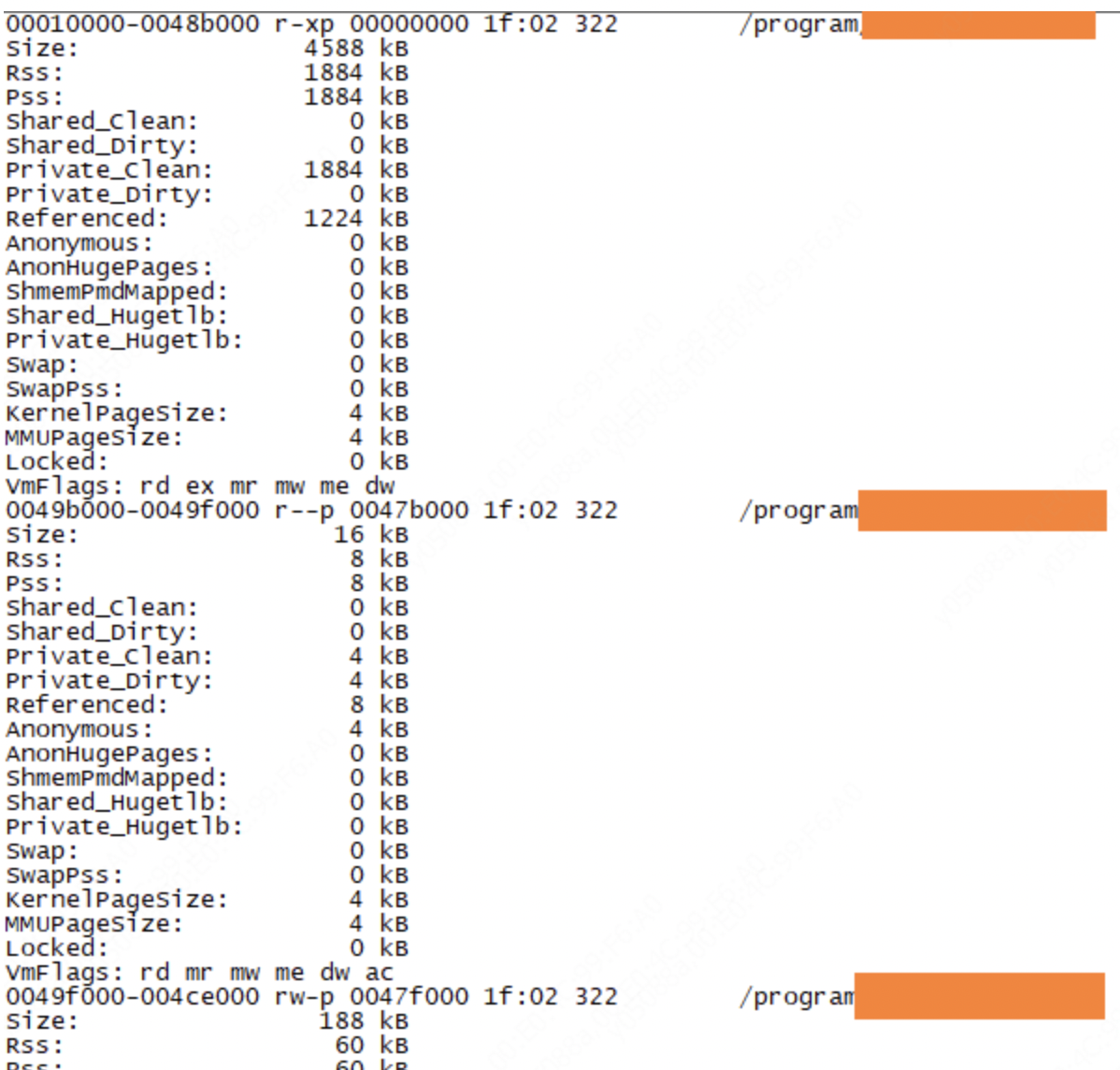
smaps文件中的几条条记录
有了smap如此详细关于虚拟内存空间到物理内存空间的映射信息,相信大家已经能够通过分析该文件回答上面提出的4个问题。
最后希望所有读者能够通过阅读本文对进程的虚拟内存和物理内存有一个更加清晰认识,并能更加准确理解top命令关于内存的输出,最后可以通过smaps文件更进一步分析进程使用内存的情况。
注意:smapsFile 文件中的字段重复出现是因为它包含了每个内存区域的详细信息,而每个内存区域都有相同的字段。这是为了提供更详细的内存使用情况。在 smapsFile 文件中,每个内存区域的信息以如下格式出现:
Address Permissions Offset Device Inode Pathname
...
Size: <size>
Rss: <rss>
Shared_Clean: <shared_clean>
Shared_Dirty: <shared_dirty>
Private_Clean: <private_clean>
Private_Dirty: <private_dirty>
Referenced: <referenced>
Anonymous: <anonymous>
...
其中 <size>, <rss>, <shared_clean>, <shared_dirty>, <private_clean>, <private_dirty>, <referenced>, <anonymous> 等字段表示了不同方面的内存信息。由于每个内存区域都有这些字段,因此在 smapsFile 文件中会重复出现。这样设计的目的是允许对每个内存区域的详细信息进行分析和处理。
下面给一个读取本进程给个统计数据的例子:
#include <iostream>
#include <unistd.h>
#include <iostream>
#include <fstream>
#include <string>
#include <unordered_map>
#include <vector>
class SmapsParser {
public:
static std::unordered_map<std::string, unsigned long> getMemorySizes(const std::string& pid) {
std::string smapsPath = "/proc/" + pid + "/smaps";
std::unordered_map<std::string, unsigned long> memorySizes;
std::ifstream smapsFile(smapsPath);
std::string line;
std::string currentCategory;
if (smapsFile.is_open()) {
size_t line_num = 0;
while (std::getline(smapsFile, line)) {
line_num++;
if (line.compare(0, 5, "Size:") == 0) {
memorySizes["Size"] += getSizeInKb(line);
} else if (line.compare(0, 4, "Rss:") == 0) {
memorySizes["Rss"] += getSizeInKb(line);
} else if (line.compare(0, 13, "Shared_Clean:") == 0) {
memorySizes["Shared_Clean"] += getSizeInKb(line);
} else if (line.compare(0, 13, "Shared_Dirty:") == 0) {
memorySizes["Shared_Dirty"] += getSizeInKb(line);
} else if (line.compare(0, 14, "Private_Clean:") == 0) {
memorySizes["Private_Clean"] += getSizeInKb(line);
} else if (line.compare(0, 14, "Private_Dirty:") == 0) {
memorySizes["Private_Dirty"] += getSizeInKb(line);
} else if (line.compare(0, 5, "Swap:") == 0) {
memorySizes["Swap"] += getSizeInKb(line);
} else if (line.compare(0, 4, "Pss:") == 0) {
memorySizes["Pss"] += getSizeInKb(line);
}
}
std::cout << "file line_num=" << line_num << std::endl;
smapsFile.close();
} else {
std::cerr << "Failed to open smaps file." << std::endl;
}
return memorySizes;
}
private:
static unsigned long getSizeInKb(const std::string& line) {
std::string sizeStr = line.substr(line.find_first_of("0123456789"));
// std::cout << "sizeStr:" << sizeStr << ", "
// << std::stoul(sizeStr) << std::endl;
return std::stoul(sizeStr);
}
};
// Example usage
int main() {
pid_t pid = getpid(); // 获取本进程ID
std::string pid_str = std::to_string(pid);
std::cout << "Process ID: " << pid_str << std::endl;
std::string smapsPath = "/proc/" + pid_str + "/smaps";
std::vector<int> a(1000000);
std::unordered_map<std::string, unsigned long> memorySizes
= SmapsParser::getMemorySizes(pid_str);
std::cout << "----------------smaps-----------------" << std::endl;
for (const auto& pair : memorySizes) {
std::cout << pair.first << ": " << pair.second
<< " kB" << std::endl;
}
std::cout << "--------------------------------------" << std::endl;
return 0;
}
/*
Size:表示该映射区域在虚拟内存空间中的大小。
Rss:表示该映射区域当前在物理内存中占用了多少空间
Shared_Clean:和其他进程共享的未被改写的page的大小
Shared_Dirty: 和其他进程共享的被改写的page的大小
Private_Clean:未被改写的私有页面的大小。
Private_Dirty: 已被改写的私有页面的大小。
Swap:表示非mmap内存(也叫anonymous memory,比如malloc动态分配出来的内存)由于物理内存
不足被swap到交换空间的大小。
Pss:该虚拟内存区域平摊计算后使用的物理内存大小(有些内存会和其他进程共享,例如mmap进来的)。
比如该区域所映射的物理内存部分同时也被另一个进程映射了,且该部分物理内存的大小为1000KB,那
么该进程分摊其中一半的内存,即Pss=500KB。
output:
Process ID: 1
file line_num=1080
Swap: 0 kB
Private_Dirty: 4156 kB
Shared_Dirty: 0 kB
Pss: 5810 kB
Rss: 7520 kB
Private_Clean: 1600 kB
Shared_Clean: 1764 kB
Size: 10532 kB
*/
47.文件传输
scp
不支持文件断点重传
scp graph500-28.e.random.b.zst root@xxxx://data_old/dataset/graph500-28/
rsync
支持断点重传,貌似速度更快,大文件推荐!
rsync --partial --progress --rsh=ssh graph500-28.e.random.b.zst root@xxxx://data_old/dataset/graph500-28/
wget
wget -c url
48.设置代理(vpn)
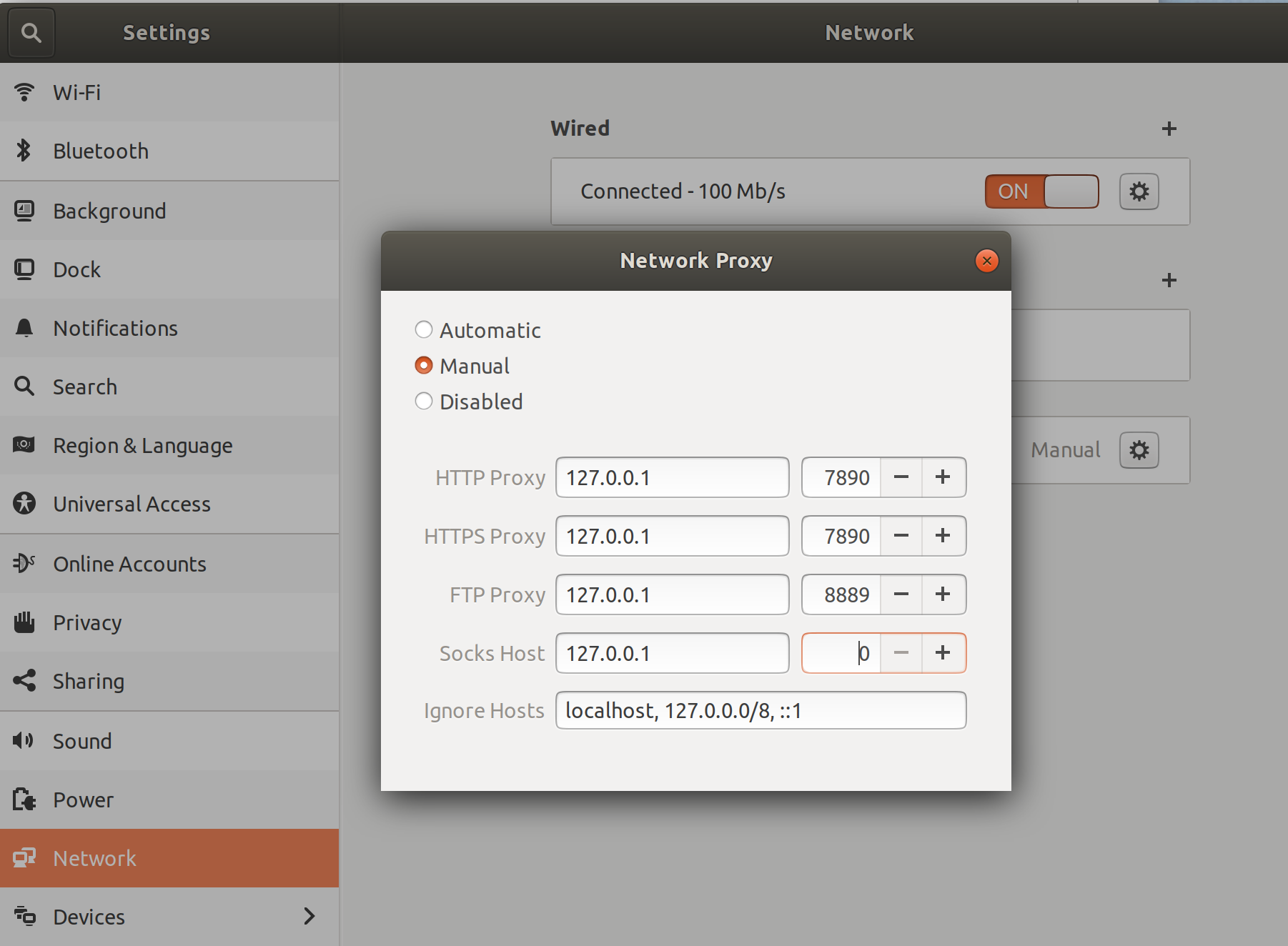
49.mac 安装 Homebrew
参考:https://brew.idayer.com/guide/start/
50.修改终端命令提示符及其颜色配置
参考:
# 获取当前终端格式
echo $PS1
[\u@\h \W]\$
# 设置终端格式
export PS1='[\u@\h $PWD]$'
终端提示符的命令选项
\d :#代表日期,格式为weekday month date,例如:"Mon Aug 1"
\H :#完整的主机名称
\h :#仅取主机的第一个名字
\t :#显示时间为24小时格式,如:HH:MM:SS
\T :#显示时间为12小时格式
\A :#显示时间为24小时格式:HH:MM
\u :#当前用户的账号名称
\v :#BASH的版本信息
\w :#完整的工作目录名称
\W :#利用basename取得工作目录名称,所以只会列出最后一个目录
\# :#下达的第几个命令
\ $ :#提示字符,如果是root时,提示符为:#,普通用户则为:$
颜色设置:
开始颜色输入:[\e[F;Bm]
结束颜色输入:[\e[0m]
'F' 字体颜色(编号30-37)
'B' 背景颜色(编号40-47)
'm' 表示转义结束
字体颜色 背景颜色 所选颜色
30 40 黑色
31 41 红色
32 42 绿色
33 43 黄色
34 44 蓝色
35 45 紫红色
36 46 青蓝色
37 47 白色
"\e":表示设置颜色值
"F": 表示前景色(字体颜色)
"B": 表示背景色
参考:
export PS1='\[\e[32;40m\][\u@\h:$PWD]\$\[\e[0m\] '

如果希望长期有效,可以写入到:
sudo vim ~/.bashrc
51. 信号量不够
运行openGuass报错如下:FATAL: could not create semaphores: No space left on device
分析参考:https://blog.youkuaiyun.com/qingsong3333/article/details/124445788
随着后续恢复、启动、关闭的数据库越来越多,发现问题又出现了。但是已经启动的openGauss数据库都已经停止了,怎么还残留这么多信号量呢? 经过测试发现,如果使用kill -9命令杀掉openGauss数据库的进程,那么会残留信号量,占用资源。如果使用gs_ctl stop停止,则没有问题。
# 查看系统限制
ipcs -ls
# 查看当前使用情况
ipcs -s
# 清空指定用户的占用
ipcs -s | grep your_user_name | awk '{print $2}' | xargs -n 1 ipcrm -s
# 查看当前使用情况
ipcs -s
52. Ubuntu下的终端多标签切换快捷键
添加终端多标签:
- ctrl + shift + t;
切换:
- alt+1 alt+2 alt+3
- ctrl + pageUp/pageDown
- Edit–> Keybord Shortcuts 到这里去自己设置快捷键。
mac系统的风格:
alt + shift + t —> 新标签
alt + shift + [ —> 上一个标签
alt + shift + ] —> 下一个标签
53. centos 7 系统设置时区及同步时间
细节参考:https://blog.youkuaiyun.com/Chaolei3/article/details/122870275
$ timedatectl
Local time: 日 2024-10-27 22:09:01 EDT
Universal time: 一 2024-10-28 02:09:01 UTC
RTC time: 一 2024-10-28 02:09:01
Time zone: America/New_York (EDT, -0400)
NTP enabled: yes
NTP synchronized: yes
RTC in local TZ: no
DST active: yes
Last DST change: DST began at
日 2024-03-10 01:59:59 EST
日 2024-03-10 03:00:00 EDT
Next DST change: DST ends (the clock jumps one hour backwards) at
日 2024-11-03 01:59:59 EDT
日 2024-11-03 01:00:00 EST
$ timedatectl set-timezone Asia/Shanghai
.... 需要授权/和验证账户密码
$ timedatectl
Local time: 一 2024-10-28 10:12:02 CST
Universal time: 一 2024-10-28 02:12:02 UTC
RTC time: 一 2024-10-28 02:12:02
Time zone: Asia/Shanghai (CST, +0800)
NTP enabled: yes
NTP synchronized: yes
RTC in local TZ: no
DST active: n/a



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











