




 本文深入解析MapReduce的工作原理,包括大数据处理流程、Map和Reduce阶段的详细操作,以及Shuffle过程中的关键步骤,如分区、排序、组合和溢写。
本文深入解析MapReduce的工作原理,包括大数据处理流程、Map和Reduce阶段的详细操作,以及Shuffle过程中的关键步骤,如分区、排序、组合和溢写。
整体把握:
1.有一个待处理的大数据,被划分成大小相同的数据库(如64MB),以及与此相应的用户作业程序。
2.系统中有一个负责调度的主节点(Master),以及数据Map和Reduce工作节点(Worker).
3.用户作业提交个主节点。
4.主节点为作业程序寻找和配备可用的Map节点,并将程序传送给map节点。
5.主节点也为作业程序寻找和配备可用的Reduce节点,并将程序传送给Reduce节点。
6.主节点启动每一个Map节点执行程序,每个Map节点尽可能读取本地或本机架的数据进行计算。(实现代码向数据靠拢,减少集群中数据的通信量)。
7.每个Map节点处理读取的数据块,并做一些数据整理工作(combining,sorting等)并将数据存储在本地机器上;同时通知主节点计算任务完成并告知主节点中间结果数据的存储位置。
8.主节点等所有Map节点计算完成后,开始启动Reduce节点运行;Reduce节点从主节点所掌握的中间结果数据位置信息,远程读取这些数据。
9.Reduce节点计算结果汇总输出到一个结果文件,即获得整个处理结果。
MapReduce大致处理过程如图,详细过程见下文
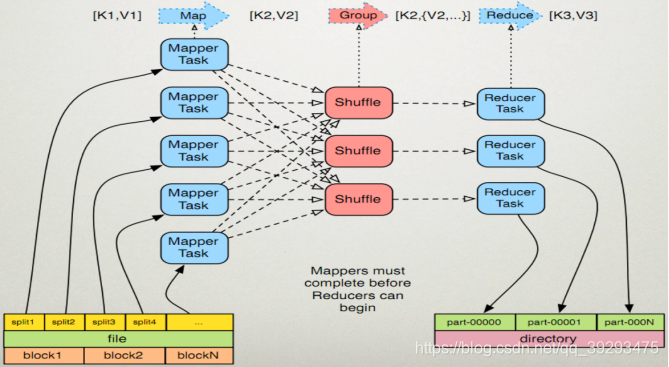
实例:
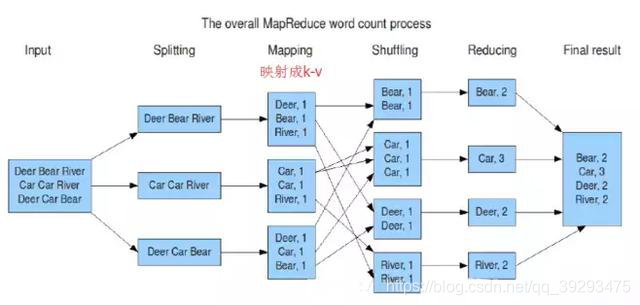
图片出自:https://blog.youkuaiyun.com/m0_37803704/article/details/80364237
过程详解:
初始化:
1.MapReduce程序启动的时候,Hadoop系统会把程序运行依赖库(包括用户自定义的Map处理和Reduce处理)拷贝到各个计算节点,资源管理器向节点管理器获取一个运行application master的容器,节点管理器为application master分配资源,然后application master向资源管理器请求资源,各个计算节点的node manager 分配资源,application master定期向resource manager 汇报任务进度。
Mapper:
然后系统从系统磁盘中读取数据,mapper将每一行变成一个<k,v>,k为偏移量。每一个键值对调用一次map函数。覆盖map(),接收第一步产生的<k,v>,进行split处理,转换为新的中间键值对<k,v>输出。
2.Shuffle:
2..1Mapper Shuffle:
2.1.1.分区(默认分区为1)分区数目=Reducer数目
在经过Mapper运行后,输出是这样一个Key/Value对:Key是“aaa”,Value是1。假设这个Job有3个ReduceTask,到底“aaa”应该交由哪个Reducer去处理,是需要现在决定的。MapReduce提供了Partitioner接口,其作用是根据Key或Value及Reduce的数量来决定当前这对输出数据最终应该交由哪个ReduceTask处理。默认对Key进行哈希运算后,再以ReduceTask数量取模。在该例中,“aaa”经过Partition(分区)后返回0,也就是这对输出数据应当由第一个Reducer来处理。接下来需要将数据写入内存缓冲区中。缓冲区的作用就是批量收集Map结果,减少磁盘I/O影响。
内存缓冲区的大小是有限的,默认是100MB。当MapTask输出结果有很多时,内存可能会不足,所以需要在一定条件下将缓冲区中的数据临时写入磁盘,然后重新利用这个缓冲区。这个从内存往磁盘写数据的过程被称为Spill,中文译为溢写。
2.1.2.排序
当缓冲区的数据达到阀值,溢写线程启动,锁定这80MB的内存,执行溢写过程。剩下的20MB继续写入map task的输出结果。互不干涉!
当溢写线程启动后,需要对这80MB内存空间内的key做排序(Sort)。排序是mapreduce模型的默认行为,也是对序列化的字节做的排序。排序规则:字典排序!
2..1.3.(combiner)(可选项)
对每个spill 文件进行 小型的reduce处理,举个栗子:要写入缓冲区的溢出文件中的内容是:<“hello”,1>,<“world”,1>,<“hello”,1>,<“hello”,1>,combiner执行后就是<“hello”,3>,<“world”,1>,在这个过程可以看成是一次小型的reduce过程,主要是为了降低IO开销。仔细一想就会明白:如果不执行combiner,下一步传输的IO序列将是<“hello”,{1,1,1,1,1,1,,.....}>,执行之后就是<“hello”,{n}>
2..1.4.写入spill(溢出)文件中
2..1.5.合并(分组).
对多个溢写(spill)文件在磁盘上进行合并,也是为了降低网络IO开销
2.2网络IO:
mapper完成后经过网络IO传输到相应的Reducer的内存缓冲区中,这个过程由application master 通知相应的reducer(注意:如果在mapper阶段有的mapper出现故障,application master会开启相关的备份数据节点替代它)
2.3.Reduce Shuffle:
Mapper处理结果经过网络IO首先写到reduce端的缓存中,同样缓存占用到达一定阈值后会将数据写到磁盘中,同样会进行partition、combine、排序等过程。如果形成了多个磁盘文件还会进行合并,最后一次合并的结果作为reduce的输入而不是写入到磁盘中在Reducer端执行之前,对多个Mapper端传来的文件进行合并,形成key-<value1,value2......>的格式,这里缓冲区的大小要比map端的更为灵活,它是基于JVM的heap size设置,因为shuffler阶段reducer不运行,所以应该把绝大部分的内存都给shuffle用。最终的输入文件可能存放在磁盘,也可能存放在内存中,默认存放在磁盘上。当Reducer的输入文件已定时,整个Shuffle过程才最终结束。
3.Reducer:
每一个reducer对所有mapper传输过来的数据进行一次大型的reduce操作 ,j结果存在HDFS中
merge的三种形式:
内存到内存、内存到磁盘、磁盘到磁盘
默认情况下,第一种形式不启用。当内存中的数据量达到一定的阀值,就启动内存到磁盘的merge。与map端类似,这也是溢写过程,当然如果这里设置了Combiner,也是会启动的,然后在磁盘中生成了众多的溢写文件。第二种merge方式一直在运行,直到没有map端的数据时才结束,然后启动第三种磁盘到磁盘的merge方式生成最终的那个文件。
我们对Shuffle过程的期望是:
★ 完整地从map task端拉取数据到reduce task端
★ 跨界点拉取数据时,尽量减少对带宽的不必要消耗
★ 减小磁盘IO对task执行的影响
参考博文:http://www.cnblogs.com/ahu-lichang/p/6665242.html
https://www.cnblogs.com/felixzh/p/4680808.html

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









