






 Pandas是一种高性能的数据分析库,提供Series和DataFrame两种核心数据结构,适用于复杂的数据操作和分析任务。它基于NumPy构建,与Matplotlib等工具配合使用,为Python数据科学生态提供了强大的支持。本文介绍了Pandas的基本用法,包括数据创建、索引、切片、算术运算和比较运算,以及数据类型操作如重排和索引调整。
Pandas是一种高性能的数据分析库,提供Series和DataFrame两种核心数据结构,适用于复杂的数据操作和分析任务。它基于NumPy构建,与Matplotlib等工具配合使用,为Python数据科学生态提供了强大的支持。本文介绍了Pandas的基本用法,包括数据创建、索引、切片、算术运算和比较运算,以及数据类型操作如重排和索引调整。
Pandas—提高高性能易用数据类型和分析工具
引用
importpandas aspd
Pandas基于NumPy实现,常与NumPy和Matplotlib一同使用

两个数据类型—Series,DataFrame
Series类型
Series类型由一组数据及与之相关的数据索引组成

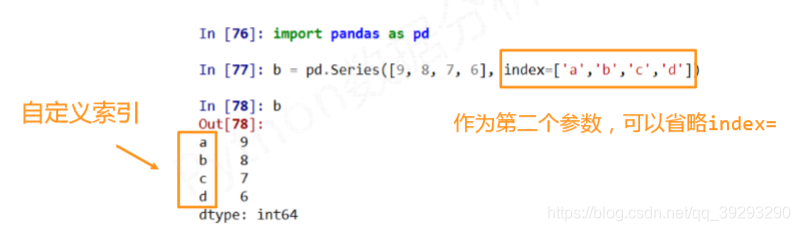
Series类型可以由如下类型创建:
- Python列表 ,index与列表元素个数一致
- 标量值 ,index表达Series类型的尺寸
- Python字典 ,键值对中的“键”是索引,index从字典中进行选择操作
- ndarray ,索引和数据都可以通过ndarray类型创建
- 其他函数,range()函数等
Series类型的基本操作
Series类型包括index和values两部分
Series类型的操作类似ndarray类型
Series类型的操作类似Python字典类型
In [1]: import pandas as pd
In [2]: b = pd.Series([9,8,7,6],['a','b','c','d'])
In [3]: b
Out[3]:
a 9
b 8
c 7
d 6
dtype: int64
In [4]: b.index
Out[4]: Index(['a', 'b', 'c', 'd'], dtype='object')
In [5]: b.values
Out[5]: array([9, 8, 7, 6], dtype=int64)
In [6]: b['b']
Out[6]: 8
In [7]: b[1]
Out[7]: 8
In [8]: b[['c','d',0]]
Out[8]:
c 7.0
d 6.0
0 NaN
dtype: float64
In [9]: b[['c','d','a']]
Out[9]:
c 7
d 6
a 9
dtype: int64
Series类型的操作类似ndarray类型:
•索引方法相同,采用[]
•NumPy中运算和操作可用于Series类型
•可以通过自定义索引的列表进行切片
•可以通过自动索引进行切片,如果存在自定义索引,则一同被切片
DataFrame类型
DataFrame类型由共用相同索引的一组列组成

DataFrame类型可以由如下类型创建:
- 二维ndarray对象
- 由一维ndarray、列表、字典、元组或Series构成的字典
- Series类型
- 其他的DataFrame类型
DataFrame是二维带“标签”数组
DataFrame基本操作类似Series,依据行列索引
数据类型操作—改变Series和DataFrame对象
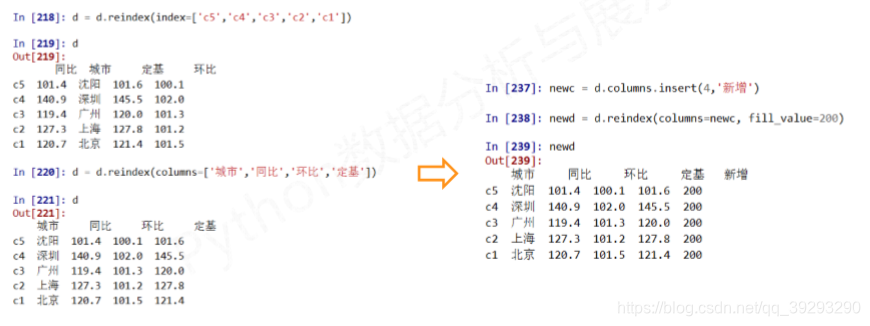
增加和重排—重新索引
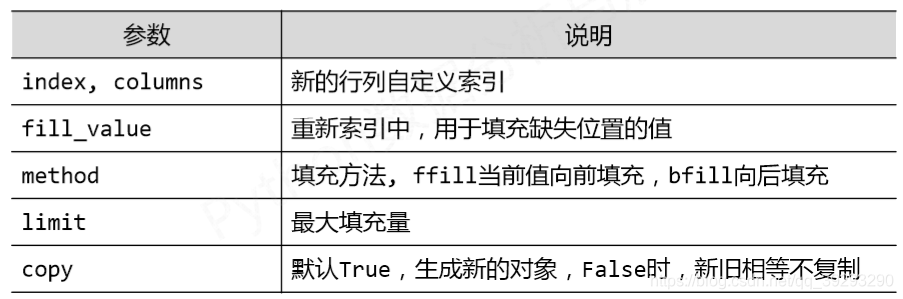
.reindex()函数
.reindex(index=None, columns=None,…)的参数
删除指定索引对象
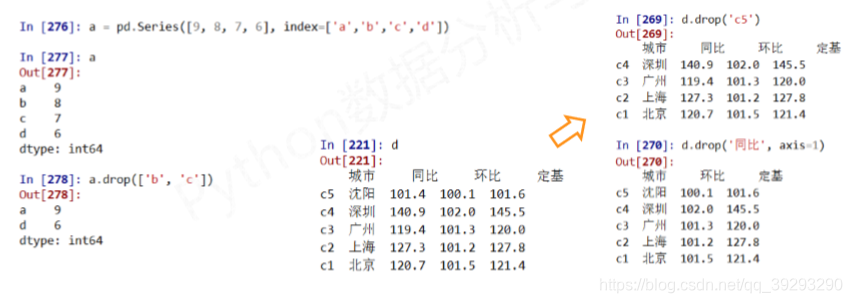
.drop()函数
.drop()能够删除Series和DataFrame指定行或列索引
算术运算


比较运算

像对待单一数据一样对待Series和DataFrame对象

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









