






 本文深入探讨数据库索引的类型及其工作原理,包括普通、唯一、主键、组合、全文索引,以及聚集和非聚集索引的区别。阐述了索引如何提升查询速度,为何写入、修改、删除操作会变慢,提供了SQL优化策略,避免索引失效情况,如不当函数使用、OR关键字、LIKE查询等,以及如何通过执行计划检查和优化SQL语句。
本文深入探讨数据库索引的类型及其工作原理,包括普通、唯一、主键、组合、全文索引,以及聚集和非聚集索引的区别。阐述了索引如何提升查询速度,为何写入、修改、删除操作会变慢,提供了SQL优化策略,避免索引失效情况,如不当函数使用、OR关键字、LIKE查询等,以及如何通过执行计划检查和优化SQL语句。
参考资料:
- https://www.cnblogs.com/yuluoxingkong/p/9403965.html
- https://www.cnblogs.com/wangzhengyu/p/10412499.html
- https://www.cnblogs.com/mfrank/p/11168173.html(索引相关)
索引理解
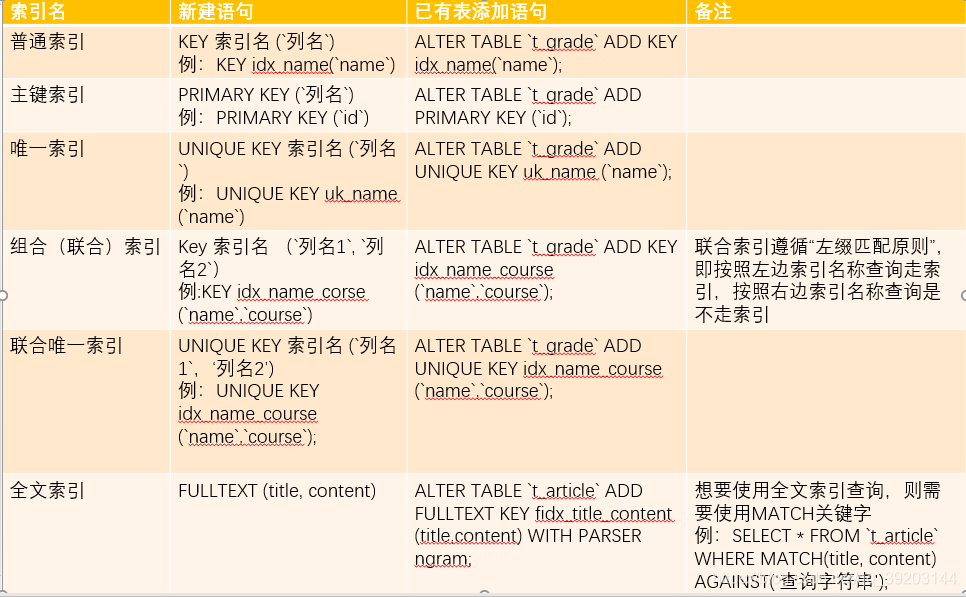
普通索引:最基本的索引,没有任何限制;
唯一索引:与"普通索引"类似,不同的就是:索引列的值必须唯一,但允许有空值;
主键索引:是一种特殊的唯一索引,不允许有空值;
组合索引:为了提高mysql效率可以建立组合索引,遵循最左前缀原则。
全文索引:仅可用于 MyISAM 表,针对较大的数据,生成全文索引很耗时好空间;
为什么要给表加上主键?
- 聚集索引
索引原理,平衡树,如果给表带上了主键,那么表在磁盘上的存储结构就由整齐排列的结构变成了树状结构,也就是平衡树结构,整个表就变成了一个索引。整个表变成了一个索引后,就是所谓的聚集索引。
一个表只能有一个主键,一个表只能由一个聚集索引,主键的作用就是把数据表格式变成一个索引(平衡树)的结构。
- 非聚集索引
索引树结构中的各个节点来自于表中的索引字段,而索引是建表之初就已经设定的内容, 假如给user表的name字段加上索引 , 那么索引就是由name字段中的值构成,在数据改变时,DBMS(数据库管理系统)需要一直维护索引结构的正确性,如果给表中多个字段加上索引 , 那么就会出现多个独立的索引结构,每个索引(非聚集索引)互相之间不存在关联。
- 聚集索引与非聚集索引区别
通过聚集索引可以查到需要查找的数据(直接查索引,直接寻找到主键,然后在树的最底层查询到数据);
而通过非聚集索引可以查到记录对应的主键值 , 再使用主键的值通过聚集索引查找到需要的数据。
不管以任何方式查询表, 最终都会利用主键通过聚集索引来定位到数据, 聚集索引(主键)是通往真实数据所在的唯一路径
- 覆盖索引
当为字段建立索引以后, 字段中的内容会被同步到索引之中, 如果为一个索引指定两个字段, 那么这个两个字段的内容都会被同步至索引之中。
比起单个索引,覆盖索引要是查询字段在索引中,就会直接查出这个字段,而不会再走一遍id聚集索引去查询字段的过程。
为什么加索引后会使查询变快?
通常树的结点(除过底部)都是由主键id字段组成,树的最下方节点才是真正的表数据。
平衡树运行取到主键id,然后在索引中从根节点查询到叶节点及最后查询出结果。将一张表转换成平衡树结构,用大O标记法就是O(log n),n是记录总树,底数是树的分叉数,结果就是树的层次数。
为什么加索引后会使写入、修改、删除变慢?
因为平衡树这个结构必须一直维持在一个正确的状态, 增删改数据都会改变平衡树各节点中的索引数据内容,破坏树结构, 因此,在每次数据改变时, DBMS(数据库管理系统)必须去重新梳理树(索引)的结构以确保它的正确,这会带来不小的性能开销,也就是为什么索引会给查询以外的操作带来副作用的原因。
如何进行sql优化
查询缓慢的原因:
数据量过大;
表设计不合理;
sql语句没写好;
没有合理使用索引
使用索引失效的情况:
- 不在索引列上做任何操作。计算,函数,类型转换会导致索引失效而转向全表扫描;
- 尽量避免在where子句中使用!=或<>操作符,否则引擎将放弃使用索引而进行全表扫描;
- Like查询要当心,%放在前面索引不起作用,只有“%”不在第一个位置,索引才会生效(like ‘%文’–索引不起作用)
- 使用联合索引时,查询条件使用了这些索引中的第一个字段,索引才会生效;
- 使用or关键字的查询,查询条件只有or关键字,并且or两个条件的列都是索引时,索引才会生效;
- 索引有大量数据重复的时候,sql语句不会去利用索引,因为索引有大量重复数据时,在其建立索引也不会有什么效率;
- 字符类型加引号。字符串不加单引号,索引失效; or改union效率高。如select * from stafs where name="july’ or name=‘lliy’ 会导致索引失效。而select * from staffs where name="july’ union select * from staffs where name="lily’就不会。如果非常用or又想索引不失效,可以用覆盖索引,如select name,age from statfs where name="july’ or name=‘lliy’。
针对sql语句的优化:
- 查询语句尽量不用*;
- 尽量减少子查询,使用关联语句(left join,right join,inner join)替代;
- 尽量减少in或者not in语句,使用exist和not exist替代; or查询尽量用union或者union all替代;
- 合理增肌冗余字段,减少表的连接查询;
- 增加中间表的优化,多用于报表统计类的查询,后台开发定时任务先将数据统计好,尽量不要在查询时统计;
- 那些可以过滤掉最大数量记录的条件必须写在WHERE子句的最末尾,即有关条件中查询的范围值放在最后,例如name =miao and age <24 ,范围条件放在最后;
执行计划:
数据库在接到查询请求之后,会对查询请求进行解析和处理,生成一个执行计划,而数据库的查询执行引擎则根据这个查询计划来完成整个查询。
通过查看语句的执行计划,我们可以分析SQL语句执行的过程,观察其查询过程是否利用了索引,如果没有合理利用索引就可以通过创建索引来优化查询性能。在MySQL中,使用explain命令可以查看一条语句的执行计划。
1、有排序情况下要走索引排序;

重点关注列:
表的读取顺序 ( id )
id 相同,执行顺序由上至下
id 不同,如果是子查询,id 的序号会递增,id 值越大优先级越高,越先被执行
id 为 null 时表示一个结果集,不需要使用它查询,常出现在包含 union 等查询语句中
每个子查询使用了哪种类型 ( type )
enter image description here
system > const > eq_ref > ref > range > index > all
关注ALL,index类型。若type是此类型,且rows较大,一般有问题。
哪些索引被实际使用 ( key )
表的连接匹配条件,即哪些列或常量被用于查找索引列上的值 ( ref )
关注具体用到了索引中的哪些列
每张表有多少行被优化器查询 ( rows )
对于rows很大的行务必关注,考虑是否有其它更合适索引
额外信息(Extra)
Using filesort: MySQL 中无法利用索引完成的排序操作称为“文件排序”。
Using temporary:表示 MySQL 需要使用临时表来存储结果集,常见于 order by 和 group by,distinct等。
Using index condition:索引下推。使用索引中部分列进行索引查找。同时有部分条件无法利用索引,但是字段包含在索引中,可以利用索引中存储的信息进行过滤,无需回表过滤。
比如:
索引为 A+B+C,where 条件是 A= XX and C=XX,会利用索引列A快速筛选出n条数据,然后用索引中存储的C列值对n条数据进一步过滤得到m条数据。如果索引为A+B,那么只能利用A列筛选出n条数据后回表查询出对应完整的数据再利用C列进行筛选得到m条数据,性能会差很多。
mysql为什么使用B+树
mysql真实数据和索引数据存储在磁盘中,不能存在内存中,存在内存中,一旦断电,数据就会消失,本质还是内存和磁盘交互,一旦交互,就会涉及I/O操作,涉及I/O操作,就要尽可能减少交互,尽量读取大批量数据;
软件设计考虑I/O交互时,考虑两个层面,一个是减少I/O操作次数,一个减少I/O操作2量;
减少I/O量的,比如sql查询时,去除非必须字段查询,比如

















 1146
1146

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









