




 本文深入解析Java集合框架,包括Collection和Map的主要实现类,如List(ArrayList,LinkedList,Vector),Set(HashSet,TreeSet,LinkedHashSet)及Map(HashMap,LinkedHashMap,TreeMap)的特点与应用场景,探讨其内部结构与线程安全性。
本文深入解析Java集合框架,包括Collection和Map的主要实现类,如List(ArrayList,LinkedList,Vector),Set(HashSet,TreeSet,LinkedHashSet)及Map(HashMap,LinkedHashMap,TreeMap)的特点与应用场景,探讨其内部结构与线程安全性。
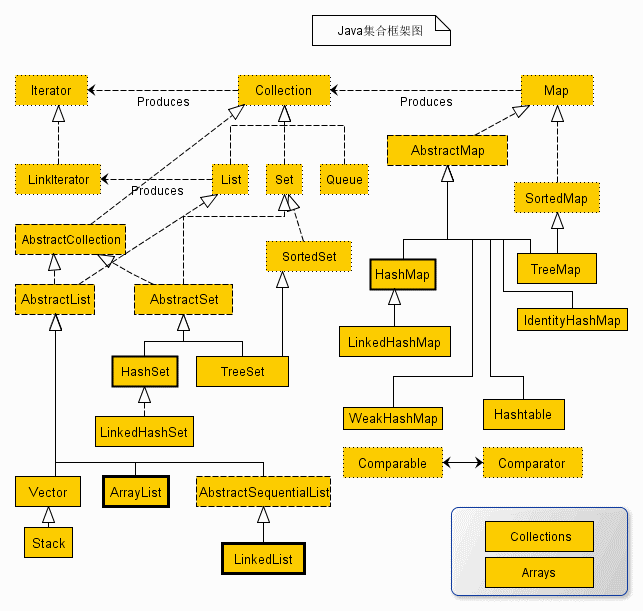
上面是一张java集合框架的基本关系图(虚线表示接口,实线为实现类)
java集合框架主要由两部分组成
1.Collection
主要的子接口是 List, Set, Queue
2.Map
(1)List(有序、可重复的集合)中的主要实现有三个,ArrayList、LinkedList,Vector
ArrayList:是一个动态的数组,它可以自动扩容,和数组一样使用下标访问,使用是最好先定义大小避免扩容操作
随机访问速度快,删除中间元素慢因为要改变后面每个元素的下标,非同步不是线程安全的。
LinkedList:是一个双向链表,只能根据前一个元素找到下一个元素,查询速度慢,但是在中间插入或者删除元素
速度快因为只需要修改元素的前后两个指针
Vector:和ArrayList一样是动态数组,但是它是同步的线程安全的,适合在多线程环境下使用。
// LinkedList源码
private static class Node<E> {
E item; //元素本身
Node<E> next; //前面一个元素(也可以说是前指针)
Node<E> prev; //后面一个元素
Node(Node<E> prev, E element, Node<E> next) {
this.item = element;
this.next = next;
this.prev = prev;
}
}
(2)Set(无序不可以重复的集合)中的主要实现类HashSet、TreeSet、LinkedHashSet
1.HashSet:基于HashMap实现的,因为HashMap中的key是不允许重复的,但是可以有一个key为null,所有HashSet的值也可以null,非同步线程不安全。
2.LinkedHashSet:基于LinkedHashMap 是有序的不可重复集合,使用链表的方式维护元素的插入顺序,非同步。
3.TreeSet:基于TreeMap,有序不可重复集合,可以使用自然排序和定制排序,
TreeSet集合不是通过hashcode和equals函数来比较元素的.它是通过compare或者comparaeTo函数来判断元素是否相等
(3)Map(键值对关系,键不可以重复可以为空,值可以重复也可以为空)主要实现类HashMap、LinkedHashMap、TreeMap
1.HashMap:jdk1.7使用数组+链表的形式实现,1.8使用数组+链表+红黑树实现,先是通过对key的hash计算得到hash值与数组tab的长度-1进行&运算等到在数组tab中相应的位置,1.7则一直使用链表,1.8在链表长度大于8时转换成红黑树。(无序,线程不安全)
1.8HashMap:https://blog.youkuaiyun.com/v123411739/article/details/78996181
2.LinkedHashMap:使用链表维护插入顺序,如果accessOrder设置为true,那么调用get方法后,会将这次访问的元素移至链表尾部,不断访问可以形成按访问顺序排序的链表。(有序,线程不安全)
/**
* The iteration ordering method for this linked hash map: true
* for access-order, false for insertion-order.
* true表示最近最少使用次序,false表示插入顺序
*/
private final boolean accessOrder;
//构造函数
public LinkedHashMap(int initialCapacity,
float loadFactor,
boolean accessOrder) {
super(initialCapacity, loadFactor);
this.accessOrder = accessOrder;
}
3.TreeMap:使用红黑数维护顺序,
自然排序:TreeMap中所有的key必须实现Comparable接口,并且所有的key都应该是同一个类的对象,否则会报ClassCastException异常。
定制排序:定义TreeMap时,创建一个comparator对象,该对象对所有的treeMap中所有的key值进行排序,采用定制排序的时候不需要TreeMap中所有的key必须实现Comparable接口。TreeMap判断两个元素相等的标准:两个key通过compareTo()方法返回0,则认为这两个key相等。

















 2044
2044

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









